A Scalable Front-End Architecture for Fast Instruction Deliveryという論文を読んでみている。 幾つかのCPUの実装で、分岐予測のペナルティを削減するための手法としてこの論文が引用されていたので、これをちょっと読んでみる。
https://web.eecs.umich.edu/~taustin/papers/ISCA99-ftb.pdf
https://dl.acm.org/doi/10.1145/307338.300999
この論文は、プロセッサのフェッチメカニズムに焦点を当て、フェッチの速度がボトルネックにならないようにする手法を研究している。 フロントエンドからの命令の供給が制限されると、バックエンドの実行効率及び全体のパイプラインの性能に影響を与えてしまう。
フロントエンドは、以下のような要素が要因としてレイテンシが大きくなりがちである: - 命令キャッシュミス - 分岐予測ミス - 分岐ターゲットバッファ(BTB)へのアクセス
これらの要素は、機構が大きくなると上手くスケーリングしなくなる可能性がある。
この論文の提案手法は、Fetch Target Buffer(FTB)と呼ばれ、命令フェッチおよびデコードのパイプラインから独立して動作することにより、より高速なフェッチが可能となる。
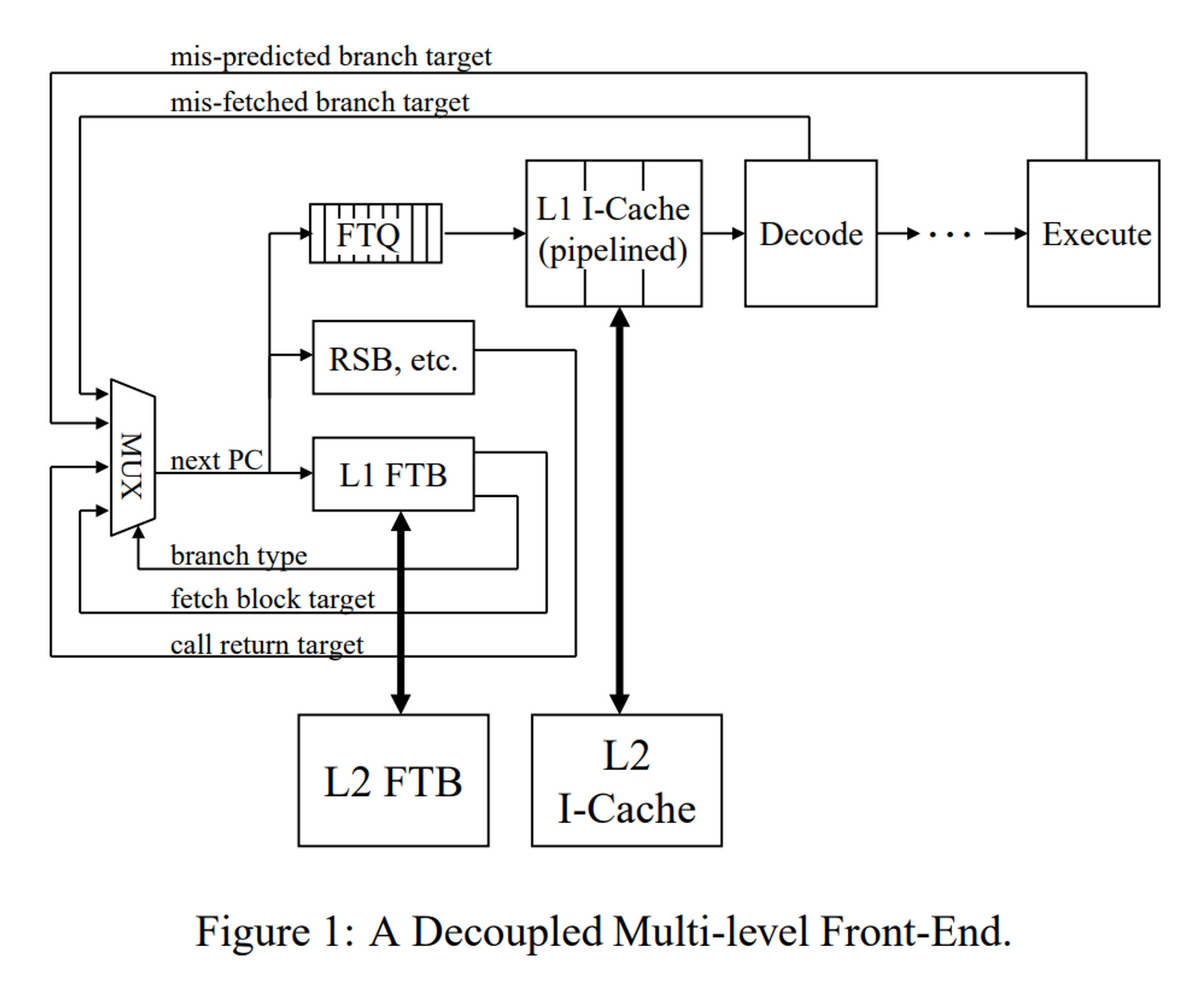
上記の図のポイントとしては、プログラムカウンタとキャッシュの間にFTQ(Fetch Target Queue)というキューが挿入されている。 これによりPCの生成とフェッチアクセスを分離するという目的がある。
現在のPCを用いてL1 FTBにアクセスし、分岐命令の型および次のフェッチブロックのターゲットを取得し、それを次のPCとして活用する。これを高速に繰り返すことによって、高速な分岐予測及びフェッチを繰り返すということが可能になる。