自作CPUの実装、ロードストア命令の物理アドレスが決まらないうえでのハザードが性能ボトルネックになっているのを見た。
ずいぶんと時間が空いてしまったが実装のデバッグを行う。以下のようなプログラムを作成して検証する。
loop: div x3, x3, x4 sd x10, 0(x3) sd x11, 8(x3) sd x12, 16(x3) sd x13, 24(x3) sd x14, 32(x3) sd x15, 40(x3) sd x16, 48(x3) sd x17, 56(x3) ld x20, 0(x1) ld x21, 8(x1) ld x22, 16(x1) ld x23, 24(x1) ld x24, 32(x1) ld x25, 40(x1) ld x26, 48(x1) ld x27, 56(x1) addi x10, x10, 0x67 addi x11, x11, 0x33 addi x12, x12, 0xbb addi x13, x13, 0x67 addi x14, x14, 0x33 addi x15, x15, 0xbb addi x16, x16, 0x67 addi x17, x17, 0x33
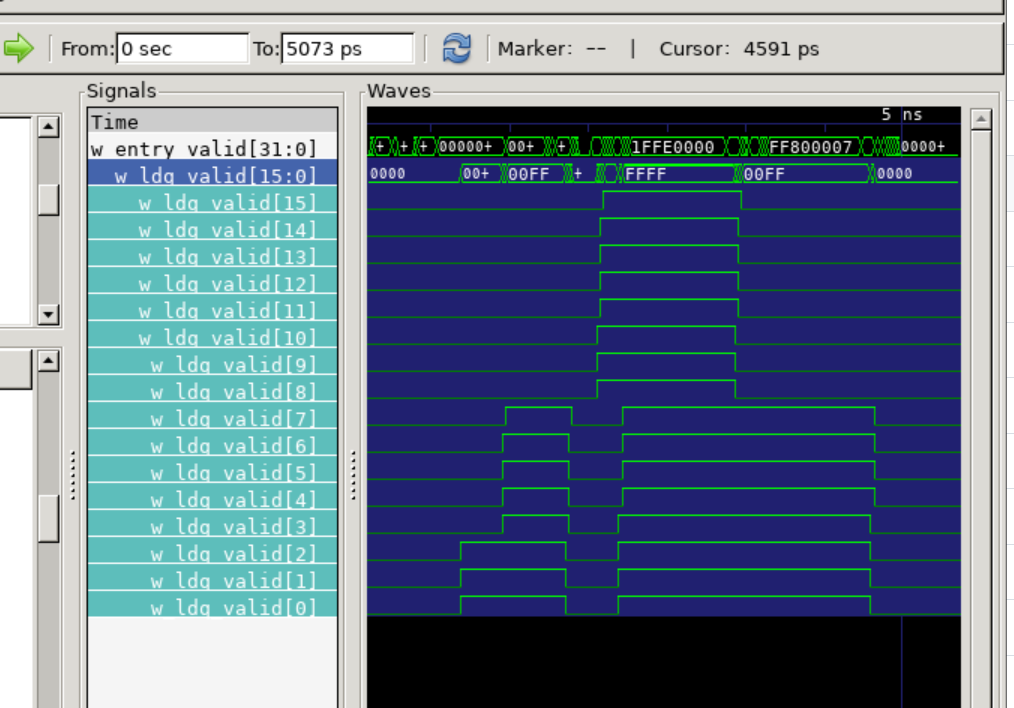
ストア命令が先行しており、次にロード命令が続く。ストア命令のベースアドレスはdiv命令によって算出されるため非常に遅い。従ってロード命令が先行して投機実行されてほしいが、SD命令のアドレスが解決するまではLD命令は実行できない。
このため、とりあえずLD命令を投機的に実行させて、SD命令を実行時に同じアドレスを先行したLD命令が踏んでいる場合はそのLD命令をフラッシュさせるという作戦にでる。このフラッシュ信号をANOTHER_FLUSHと名付け新たに定義する。
まずSD命令とLD命令でアクセスする領域が被らなかった場合、投機的に実行されたLD命令はフラッシュされずにそのままコミットされる。
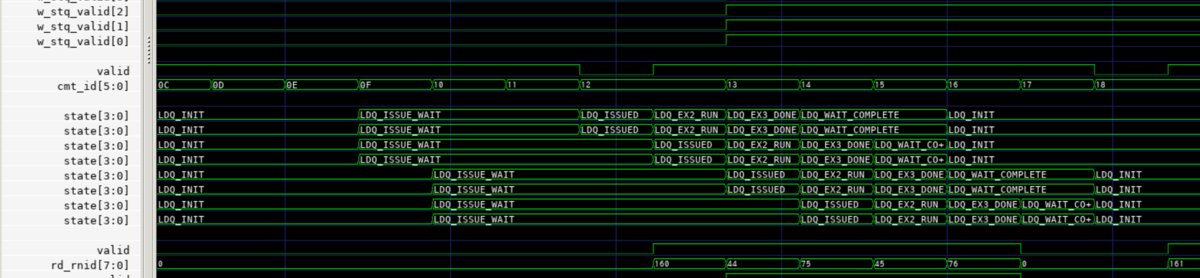
ANOTHER_FLUSHを適用した場合は、4サイクル、ANOTHER_FLUSHを適用しなかった場合は15サイクル必要となる。うまく行ったようだ。
4558 : 20 : PC=[0000000080000050] (05,01) 0241c1b3 div gp, gp, tp GPR[03](37) <= 0000000080000200 4558 : 21 : PC=[0000000080000054] (05,02) 00a1b023 sd a0, 0(gp) MW8(0x0000000080000200)=>0000000000000567 4558 : 22 : PC=[0000000080000058] (05,04) 00b1b423 sd a1, 8(gp) MW8(0x0000000080000208)=>0000000000000233 4558 : 23 : PC=[000000008000005c] (05,08) 00c1b823 sd a2, 16(gp) MW8(0x0000000080000210)=>00000000000000bb 4566 : 24 : PC=[0000000080000060] (06,01) 00d1bc23 sd a3, 24(gp) MW8(0x0000000080000218)=>0000000000011567 4566 : 25 : PC=[0000000080000064] (06,02) 02e1b023 sd a4, 32(gp) MW8(0x0000000080000220)=>0000000000011233 4566 : 26 : PC=[0000000080000068] (06,04) 02f1b423 sd a5, 40(gp) MW8(0x0000000080000228)=>00000000000110bb 4566 : 27 : PC=[000000008000006c] (06,08) 0301b823 sd a6, 48(gp) MW8(0x0000000080000230)=>0000000000022567 4570 : 28 : PC=[0000000080000070] (07,01) 0311bc23 sd a7, 56(gp) MW8(0x0000000080000238)=>0000000000022233 4570 : 29 : PC=[0000000080000074] (07,02) 0000ba03 ld s4, 0(ra) MR8(0x0000000080000100)=>0000000000000000 GPR[20](69) <= 0000000000000000 4570 : 30 : PC=[0000000080000078] (07,04) 0080ba83 ld s5, 8(ra) MR8(0x0000000080000108)=>0000000000000000 GPR[21](101) <= 0000000000000000 4570 : 31 : PC=[000000008000007c] (07,08) 0100bb03 ld s6, 16(ra) MR8(0x0000000080000110)=>0000000000000000 GPR[22](133) <= 0000000000000000 4574 : 32 : PC=[0000000080000080] (08,01) 0180bb83 ld s7, 24(ra) MR8(0x0000000080000118)=>0000000000000000 GPR[23](38) <= 0000000000000000 4574 : 33 : PC=[0000000080000084] (08,02) 0200bc03 ld s8, 32(ra) MR8(0x0000000080000120)=>0000000000000000 GPR[24](70) <= 0000000000000000 4574 : 34 : PC=[0000000080000088] (08,04) 0280bc83 ld s9, 40(ra) MR8(0x0000000080000128)=>0000000000000000 GPR[25](102) <= 0000000000000000 4574 : 35 : PC=[000000008000008c] (08,08) 0300bd03 ld s10, 48(ra) MR8(0x0000000080000130)=>0000000000000000 GPR[26](134) <= 0000000000000000 4578 : 36 : PC=[0000000080000090] (09,01) 0380bd83 ld s11, 56(ra)
一方で、ANOTHER_FLUSHを実装しない場合はLD命令の完了が大きく遅れる。
4946 : 75 : PC=[0000000080000054] (19,02) 00a1b023 sd a0, 0(gp) MW8(0x0000000080000200)=>0000000000000635 4946 : 76 : PC=[0000000080000058] (19,04) 00b1b423 sd a1, 8(gp) MW8(0x0000000080000208)=>0000000000000299 4946 : 77 : PC=[000000008000005c] (19,08) 00c1b823 sd a2, 16(gp) MW8(0x0000000080000210)=>0000000000000231 4946 : 78 : PC=[0000000080000060] (19,16) 00d1bc23 sd a3, 24(gp) MW8(0x0000000080000218)=>0000000000011635 4954 : 79 : PC=[0000000080000064] (20,01) 02e1b023 sd a4, 32(gp) MW8(0x0000000080000220)=>0000000000011299 4954 : 80 : PC=[0000000080000068] (20,02) 02f1b423 sd a5, 40(gp) MW8(0x0000000080000228)=>0000000000011231 4954 : 81 : PC=[000000008000006c] (20,04) 0301b823 sd a6, 48(gp) MW8(0x0000000080000230)=>0000000000022635 4954 : 82 : PC=[0000000080000070] (20,08) 0311bc23 sd a7, 56(gp) MW8(0x0000000080000238)=>0000000000022299 4962 : L1D Stq Store : 80000200(16) : ____________________________________00000000_00000299_00000000_00000635 4966 : L1D Stq Store : 80000210(16) : 00000000_00011635_00000000_00000231____________________________________ 4970 : L1D Stq Store : 80000220(17) : ____________________________________00000000_00011231_00000000_00011299 4974 : L1D Stq Store : 80000230(17) : 00000000_00022299_00000000_00022635____________________________________ 5030 : 83 : PC=[0000000080000074] (21,01) 0000ba03 ld s4, 0(ra) MR8(0x0000000080000100)=>0000000000000000 GPR[20](48) <= 0000000000000000 5030 : 84 : PC=[0000000080000078] (21,02) 0080ba83 ld s5, 8(ra) MR8(0x0000000080000108)=>0000000000000000 GPR[21](78) <= 0000000000000000 5030 : 85 : PC=[000000008000007c] (21,04) 0100bb03 ld s6, 16(ra) MR8(0x0000000080000110)=>0000000000000000 GPR[22](109) <= 0000000000000000 5030 : 86 : PC=[0000000080000080] (21,08) 0180bb83 ld s7, 24(ra) MR8(0x0000000080000118)=>0000000000000000 GPR[23](141) <= 0000000000000000 5038 : 87 : PC=[0000000080000084] (22,01) 0200bc03 ld s8, 32(ra) MR8(0x0000000080000120)=>0000000000000000 GPR[24](49) <= 0000000000000000 5038 : 88 : PC=[0000000080000088] (22,02) 0280bc83 ld s9, 40(ra) MR8(0x0000000080000128)=>0000000000000000 GPR[25](79) <= 0000000000000000 5038 : 89 : PC=[000000008000008c] (22,04) 0300bd03 ld s10, 48(ra) MR8(0x0000000080000130)=>0000000000000000 GPR[26](110) <= 0000000000000000 5038 : 90 : PC=[0000000080000090] (22,08) 0380bd83 ld s11, 56(ra) MR8(0x0000000080000138)=>0000000000000000