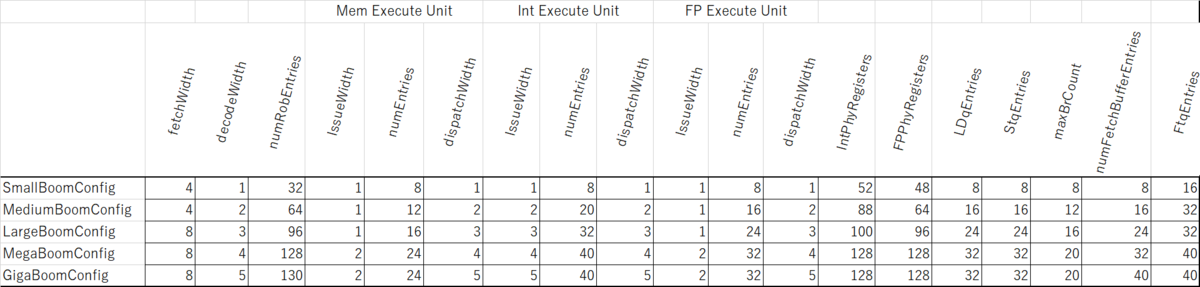
SonicBOOMの基本的な性能を見るために、Dhrystoneを実行してみることにした。SonicBOOMはパラメータに応じて以下の構成を取ることができる。
これらの構成の違いは、BOOMのconfix-mixins.scalaに定義されている。GigaBoomConfigは以下のように定義されている。
generators/chipyard/src/main/scala/config/BoomConfigs.scala
class GigaBoomConfig extends Config(
new chipyard.iobinders.WithUARTAdapter ++
new chipyard.iobinders.WithTieOffInterrupts ++
new chipyard.iobinders.WithBlackBoxSimMem ++
new chipyard.iobinders.WithTiedOffDebug ++
new chipyard.iobinders.WithSimSerial ++
new testchipip.WithTSI ++
new chipyard.config.WithBootROM ++
new chipyard.config.WithUART ++
new chipyard.config.WithL2TLBs(1024) ++
new freechips.rocketchip.subsystem.WithNoMMIOPort ++
new freechips.rocketchip.subsystem.WithNoSlavePort ++
new freechips.rocketchip.subsystem.WithInclusiveCache ++
new freechips.rocketchip.subsystem.WithNExtTopInterrupts(0) ++
new boom.common.WithGigaBooms ++
new boom.common.WithNBoomCores(1) ++
new freechips.rocketchip.subsystem.WithCoherentBusTopology ++
new freechips.rocketchip.system.BaseConfig)
このうちのWithGigaBoomsにこれらのパラメータが定義されている。
src/main/scala/common/config-mixins.scala
class WithGigaBooms extends Config((site, here, up) => {
case BoomTilesKey => up(BoomTilesKey, site) map { b => b.copy(
core = b.core.copy(
fetchWidth = 8,
decodeWidth = 5,
numRobEntries = 130,
issueParams = Seq(
IssueParams(issueWidth=2, numEntries=24, iqType=IQT_MEM.litValue, dispatchWidth=5),
IssueParams(issueWidth=5, numEntries=40, iqType=IQT_INT.litValue, dispatchWidth=5),
IssueParams(issueWidth=2, numEntries=32, iqType=IQT_FP.litValue , dispatchWidth=5)),
numIntPhysRegisters = 128,
numFpPhysRegisters = 128,
numLdqEntries = 32,
numStqEntries = 32,
maxBrCount = 20,
numFetchBufferEntries = 40,
enablePrefetching=true,
numDCacheBanks=1,
ftq = FtqParameters(nEntries=40),
fpu = Some(freechips.rocketchip.tile.FPUParams(sfmaLatency=4, dfmaLatency=4, divSqrt=true))),
dcache = Some(DCacheParams(rowBits = site(SystemBusKey).beatBytes*8,
nSets=64, nWays=8, nMSHRs=8, nTLBEntries=32)),
icache = Some(ICacheParams(fetchBytes = 4*4, rowBits = site(SystemBusKey).beatBytes*8, nSets=64, nWays=8, prefetch=true))
)}
case SystemBusKey => up(SystemBusKey, site).copy(beatBytes = 16)
case XLen => 64
case MaxHartIdBits => log2Up(site(BoomTilesKey).size)
})
これらの構成においてそれぞれDhrystoneを走らせた結果が以下のようになった。演算器やそれぞれのリソースの量を増やすとそれなりにサイクル数が減少していることが見て取れる。
| Configuration |
Cycles |
| SmallBoomConfig |
211123 |
| MediumBoomConfig |
116078 |
| LargeBoomConfig |
88391 |
| MegaBoomConfig |
74496 |
| GigaBoomConfig |
68039 |
これに調子に乗って、より大きなコンフィグレーションを作成してTeraBoomConfigを定義してみたが、Verilog生成時にメモリが足りずに落ちてしまった。なんてこった...
class WithTeraBooms extends Config((site, here, up) => {
case BoomTilesKey => up(BoomTilesKey, site) map { b => b.copy(
core = b.core.copy(
fetchWidth = 8,
decodeWidth = 8,
numRobEntries = 208,
issueParams = Seq(
IssueParams(issueWidth=2, numEntries=24, iqType=IQT_MEM.litValue, dispatchWidth=8),
IssueParams(issueWidth=8, numEntries=40, iqType=IQT_INT.litValue, dispatchWidth=8),
IssueParams(issueWidth=4, numEntries=32, iqType=IQT_FP.litValue , dispatchWidth=8)),
numIntPhysRegisters = 256,
numFpPhysRegisters = 256,
numLdqEntries = 48,
numStqEntries = 48,
maxBrCount = 20,
numFetchBufferEntries = 56,
enablePrefetching=true,
numDCacheBanks=1,
ftq = FtqParameters(nEntries=40),
fpu = Some(freechips.rocketchip.tile.FPUParams(sfmaLatency=4, dfmaLatency=4, divSqrt=true))),
dcache = Some(DCacheParams(rowBits = site(SystemBusKey).beatBytes*8,
nSets=64, nWays=8, nMSHRs=8, nTLBEntries=32)),
icache = Some(ICacheParams(fetchBytes = 4*4, rowBits = site(SystemBusKey).beatBytes*8, nSets=64, nWays=8, prefetch=true))
)}
case SystemBusKey => up(SystemBusKey, site).copy(beatBytes = 16)
case XLen => 64
case MaxHartIdBits => log2Up(site(BoomTilesKey).size)
})