前のブログエントリの続き:
引き続き、以下の資料を読んでいく。
--
- プログラミングモデルは、プログラマがどのようにコードを表現するかを示す。
- シーケンシャルコード、SIMD、データフロー、MIMD、SPMD など
実行モデルはコードをどのようにハードウェアが実行するかを示す
- アウト・オブ・オーダ実行、ベクトルプロセッサ、アレイプロセッサ...
GPUの概要
- 命令パイプラインはSIMDパイプライン(アレイプロセッサのように)動作する
- しかし、スレッドを用いたプログラミングを行い、SIMD命令は使用しない
- このために、まずは並列コード例を見てみよう。
for (i = 0; i < N; i++) { C[i] = A[i] + B[i] }

- シーケンシャル実行(SISD)の場合
- パイプラインプロセッサ・アウトオブオーダプロセッサにより実行される
- 異なるイタレーションが命令ウィンドウ内で同時に現れ、並列に実行できる
- スーパスカラ or VLIW プロセッサ:複数の命令を同時にフェッチして実行できる

- データ並列性 (SIMD)の場合
- 各イタレーションは独立であるとし、プログラマもしくはコンパイラがSIMDコードを生成し実行する

- マルチスレッドの場合
- 各イタレーションは独立であるとし、プログラマもしくはコンパイラが各イタレーションを実行するスレッドを生成する。各スレッドは同じことを実行する。
- 特別なモデルでは、SPMD (Single Program Multiple Data) / SIMT (Single Instruction Multiple Thread) とも呼ばれる

GPUはSIMD(SIMT)マシンであるということ:ただしSIMD命令は使用しない
- スレッドを使ってプログラミングをする(SPMDプログラミングモデル)
- 各スレッドは同じコードを実行するが、異なるデータを処理する
- 同じ命令を持つスレッドの集合は、動的にwarp(wavefront) としてグループ化される
- これは、ハードウェアによって構成されるSIMD操作と考えればよい
SIMTマシンにおけるSPMD
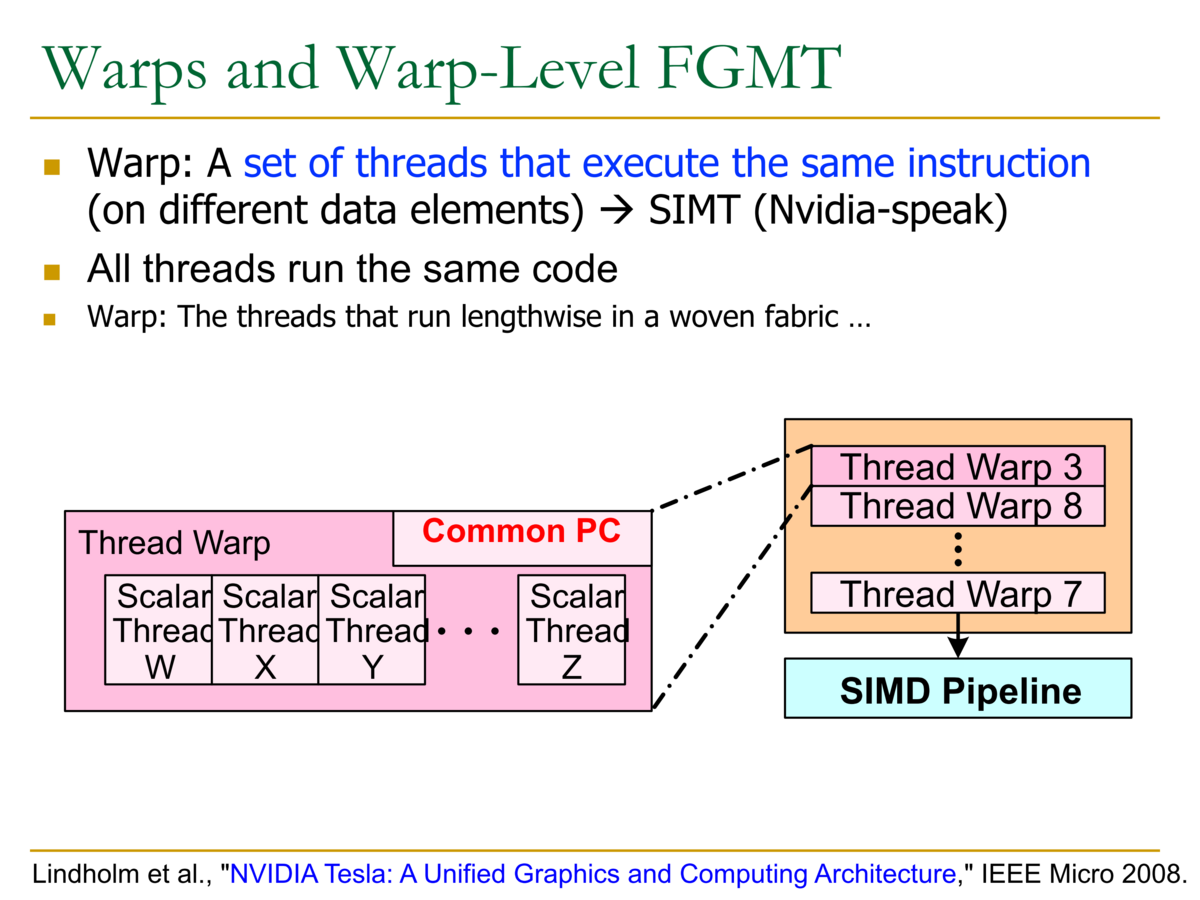
- Warpとは、同じ命令を実行するスレッドの集合と考えればよい
- SPMD (Single Program Multiple Data) や SIMT (Single Instruction Multiple Thread) といったモデルと同一

- GPUにおいて、プログラマからSIMDハードウェアを隠ぺいする (SIMT)
- SIMD と SIMTの実行モデルの比較
- SIMD:各命令が複数のデータを取る:構成要素"[VLD, VLD, VADD, VST], VLEN"
- SIMT:各スレッドは1つのWarpに動的にグループ化される:構成要素"[LD, LD, ADD, ST], NumThreads"
- SIMTのメリット:各スレッドを独立に取り扱える → MIMD処理
- 複数のスレッドを柔軟にまとめてWarpに集約できる → 真に同じ命令を実行すると思われるスレッドをグループ化できる

- Warpの細粒度マルチスレッディング
- Warpには32スレッドが含まれていると仮定
- 32Kのイタレーションが存在しているとすると、1イタレーション/スレッド → 1K Warp
- Warpは同じパイプラインでインタリーブされる → Warpの細粒度マルチスレッド
- Iteration 0-31が1つのWarpに纏められる
- Iteration 32-63が1つのWarpに纏められる
- Iteration 64-95が1つのWarpに纏められる
- Iteration 96-127が1つのWarpに纏められる

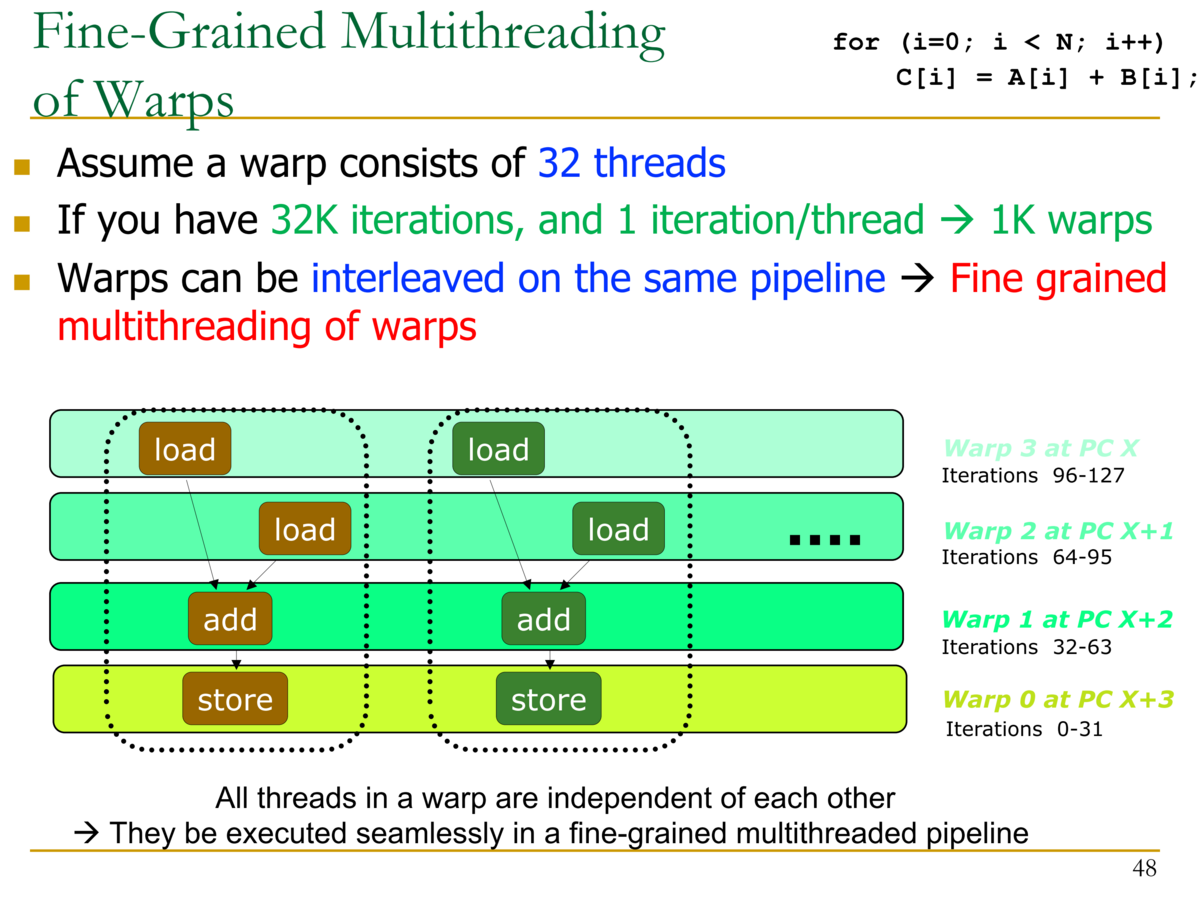
- 細粒度マルチスレッドについて:各パイプラインステージは完全に独立した異なるスレッドの命令を実行している

- WarpとWarp-Level 細粒度マルチスレッディング
- Warp:同じ命令を実行するスレッドの集合 → NVIDIA用語でSIMT
- すべてのスレッドが同じコードを実行する
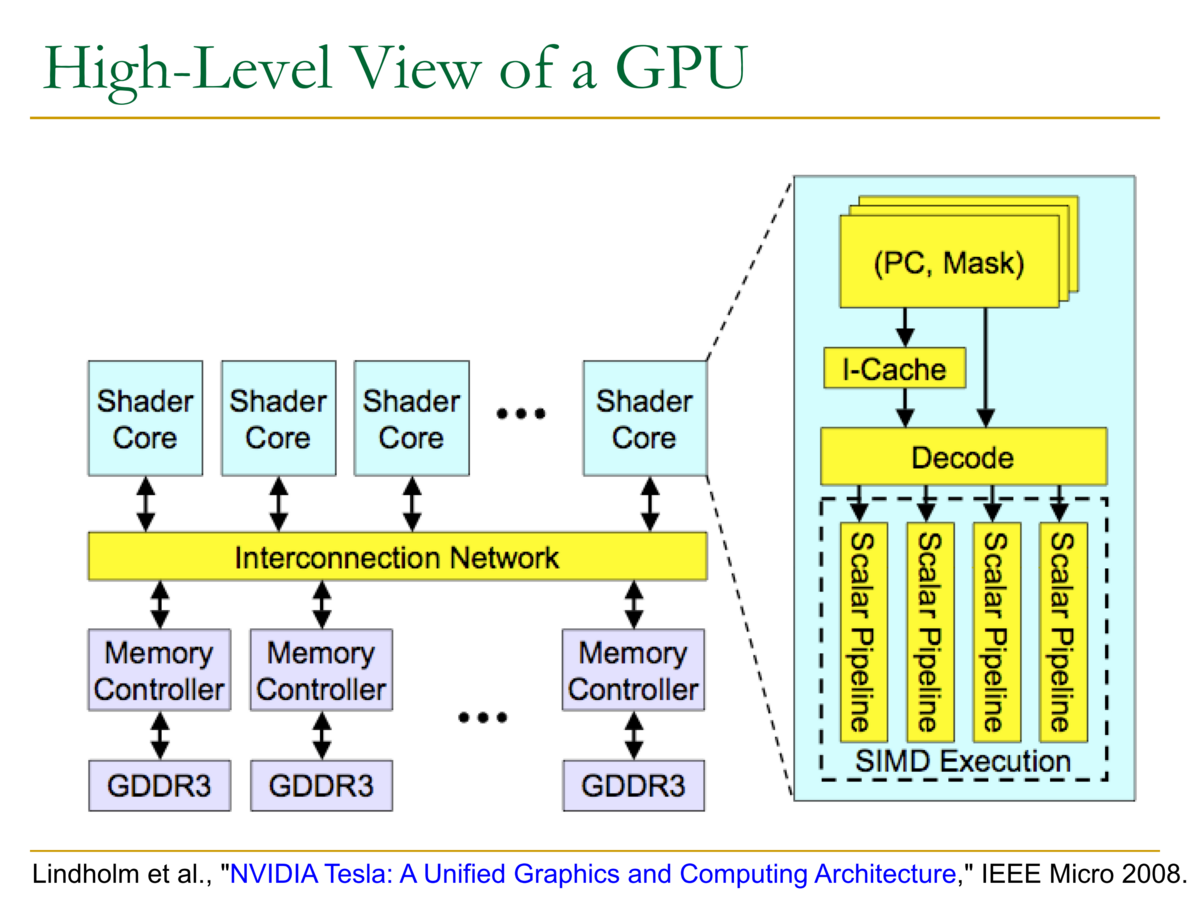
- GPUの概要図
- 各シェーダコアがスカラパイプラインを持っており、SIMD・スタイルで実行する
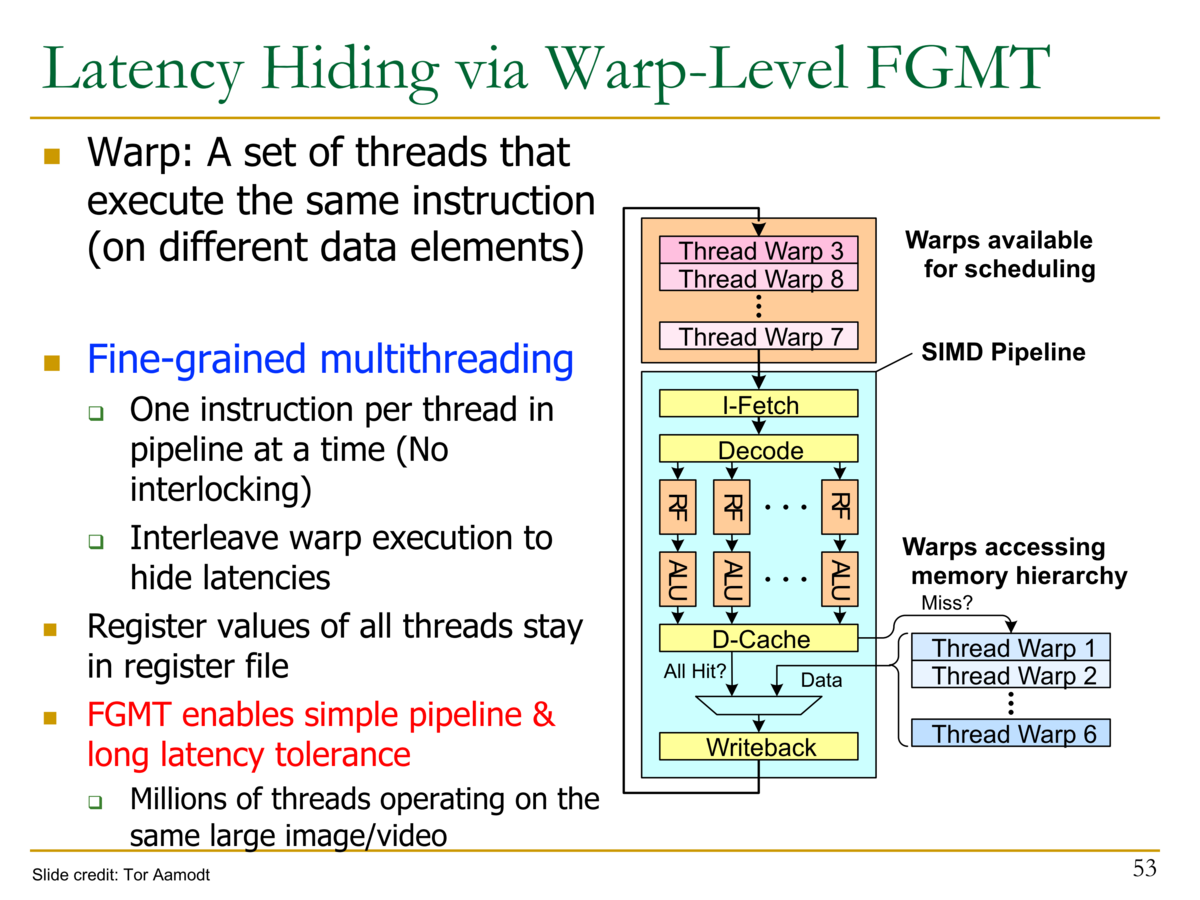
- Warp-LevelのFGMT(Fine Grained Multi-Threading)
- Warpは同じ命令を実行するスレッドの集合
- 細粒度マルチスレッディング
- パイプラインには1スレッド当たり1つの命令を実行する (インターロックがない)
- Warpの実行をインタリーブし、レイテンシを隠ぺいする
- すべてのスレッドの値はレジスタに格納されている
- FGMTによりシンプルなパイプラインを実現し、レイテンシ耐性を達成する
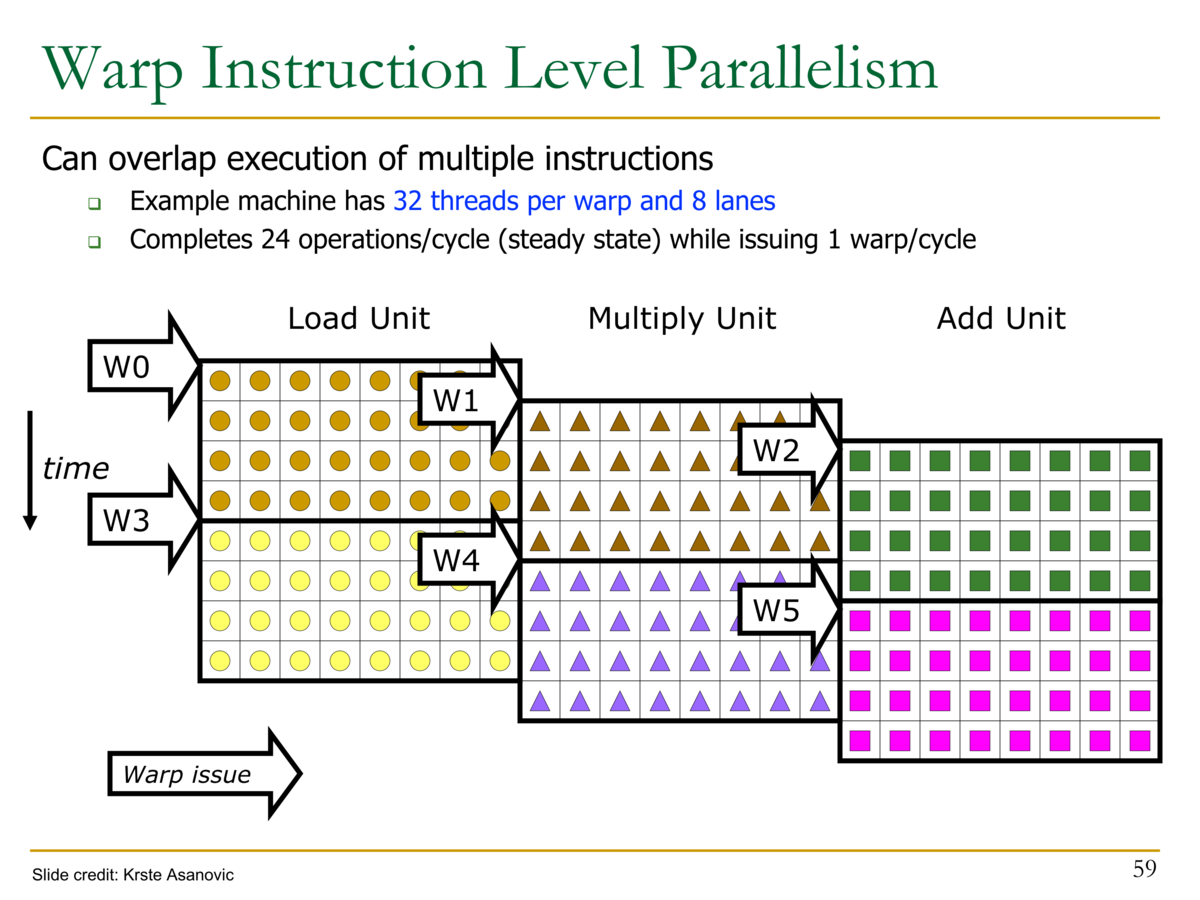
- ベクトル命令の実行と Warpの実行の比較
- ベクトル命令:
VADD A, B --> C - 32スレッドのWarp:
ADD A[tid],B[tid] → C[tid]
- ベクトル命令:





- SIMTのメモリアクセス (ロード・ストア命令)
- 異なるスレッドの同じ命令はスレッドIDを用いて異なるデータ要素のインデックスとアクセスを制御する
- N=16かつWarpが4スレッドの場合:4つのWarpが存在する

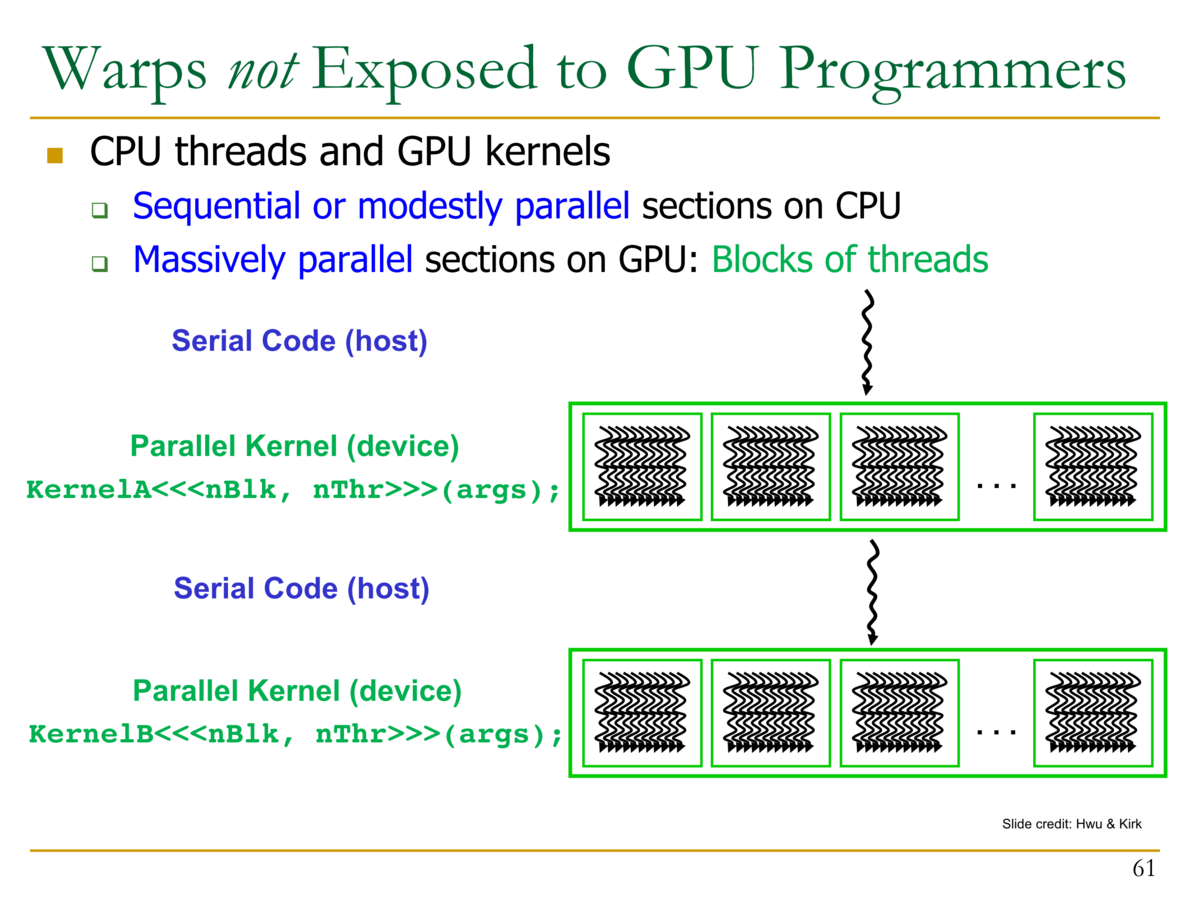
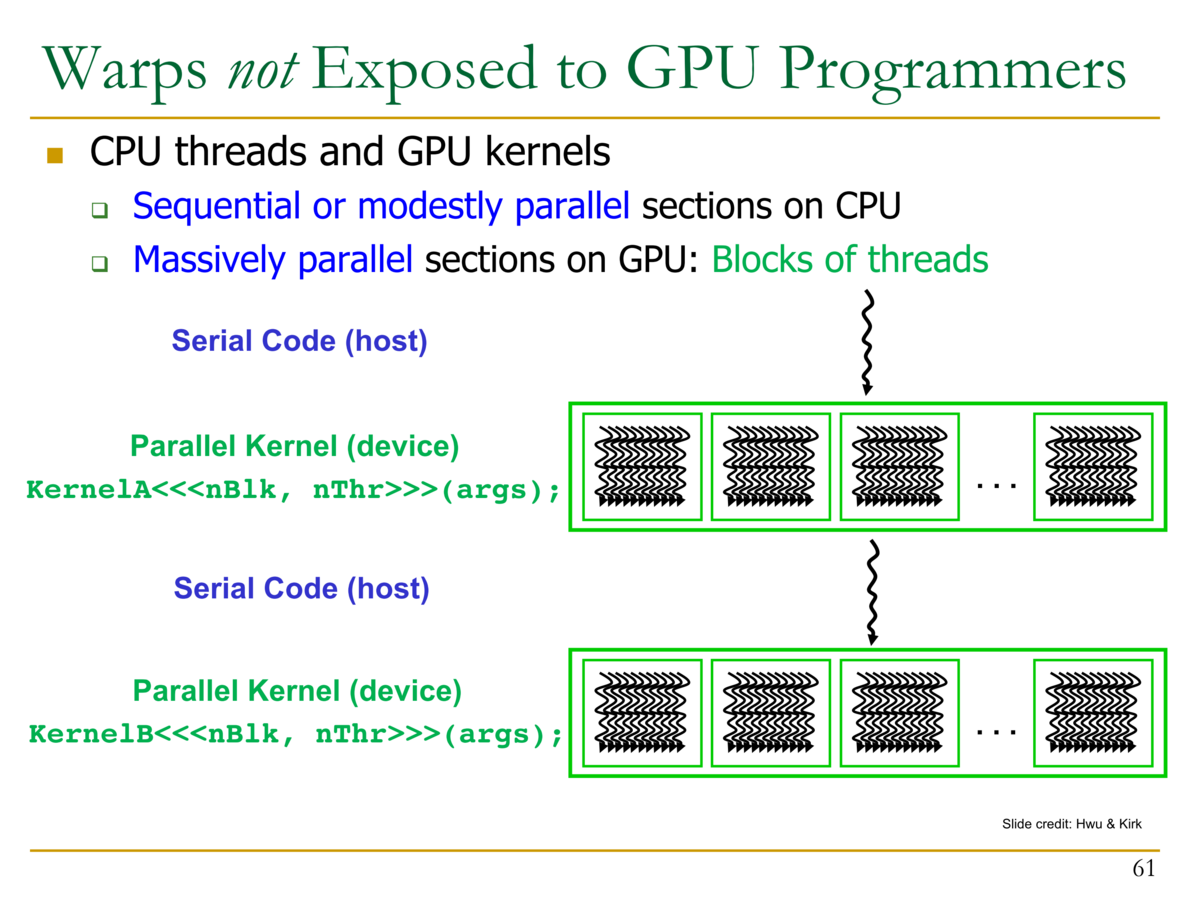
- GPUプログラマからは、Warpは隠蔽される
- CPUのスレッドとGPUのカーネル
- CPUのスレッド:シーケンシャル・または緩やかにパラレルな部分
- GPUのカーネル:非常に並列な部分。スレッドのブロック
- CPUのスレッドとGPUのカーネル
- シンプルなGPU SIMTコードの例
- 下記のコードでは、100000個のスレッドが生成される