ちょっといろいろとCPUの投機実行について調べる必要があって,Runahead実行についていい資料があったのでまとめてみることにした.
資料自体は以下:Runahead Executionを最初に提案した Onur Mutlu 先生直々の講義資料なので,これを読めばまあ間違いなかろう.
Mutlu et al., "Runahead Execution: Runahead Execution: An Alternative to Very Large Instruction Windows for Out-of-order Processors" HPCA 2003.
なぜOoOの実行は有益なのか?
- すべてのオペレーションが1サイクルで済むとしたら?
- レイテンシ耐性:OoO実行は、独立したオペレーションを同時に実行することで、マルチサイクル・オペレーションの待ち時間を許容する。
- 1つの命令に500サイクルかかるとしたら?
- デコードを続けるためには、どれくらいの大きさの命令ウィンドウが必要なのか?
- OoOは何サイクルの待ち時間を許容できるか?
- Tomasulo のアルゴリズムのレイテンシ耐性のスケーラビリティを制限するものは何か?
- アクティブ/命令ウィンドウサイズ:レジスタファイル、スケジューリングウィンドウ、リオーダーバッファ、ストアバッファ、ロードバッファによって決まる
- ウィンドウがいっぱいになることによるストール
- ロング・レイテンシの命令が完了しない場合、リタイアがブロックされる
- 将来の命令は命令ウィンドウを埋める
- ウィンドウが一杯になると、プロセッサは新しい命令をウィンドウに入れることができなくなる。
- これはフルウィンドウストールと呼ばれる。
- フルウィンドウストールは、プロセッサがプログラムの実行を進めるのを妨げる。
- 8エントリの命令ウィンドウである場合:
- L2ミスにより100サイクルが消費されるものとする:
- 後続の命令において,L2ミスとは無関係なものがリタイアすることができない
- さらに,命令ウィンドウが一杯であることにより,後続の命令をウィンドウに挿入して実行することができない
- L2キャッシュミスは、ほとんどのフルウィンドウストールの原因となっている。

- L2キャッシュミスによるストールの影響
- 下記のグラフは,ハイエンドx86プロセッサーモデルで、147のメモリ集中型ベンチマークを平均したデータ


- 問題点
- アウトオブオーダ実行には、今日のメインメモリのレイテンシを許容するための大きな命令ウィンドウが必要である
- メインメモリのレイテンシが増加するにつれて、メモリレイテンシを完全に許容するためには、命令ウィンドウサイズも増加する必要がある
- 大きな命令ウィンドウを作ることは非常に困難である
- 低消費電力/エネルギー消費(タグ・マッチング・ロジック、LD/STバッファ)
- 短いサイクルタイム(アクセス、ウェイクアップ/セレクト・レイテンシ)
- 設計と検証の複雑さが少ない(?)
- 命令ウィンドウサイズの効率的なスケーリング
- アウトオブオーダ実行における主要な研究課題の一つ
- 大きなウィンドウのメリットを小さなウィンドウで(あるいはもっとシンプルな方法で)実現するには?
- Runahead実行?
- L2ミス時、アーキテクチャの状態をチェックポイントし、プリフェッチのみ投機的に実行し、データが準備できたら再実行する。
- コンティニュアス・フロー・パイプライン?
- L2ミス時に、L2ミス依存に属するすべてのデータを割り当て解除し、再割り当て/再リネームし、データレディ時に再実行する。
- デュアルコア?
- 1つのコアが先行し、L2ミスでストールせず、命令をコミットする別のコアに供給する
- Runahead実行?
- Runahead 実行
- 大きな命令ウィンドウのメモリレベル並列性の利点を得る技術
- 最も古い命令がロング・レイテンシのキャッシュ・ミスである場合:
- アーキテクチャの状態をチェックポイントし、Runaheadモードに入る
- Runaheadモードでは
- 投機的に命令を事前実行する
- 事前実行の目的は、プリフェッチを生成することである。
- L2ミス依存の命令はINVとマークされ削除される
- Runaheadモードは元のミスが戻った時点で終了する
- チェックポイントが復元され、通常の実行が再開される。
- Mutlu et al., "Runahead Execution:Runahead Execution: An Alternative to Very Large Instruction Windows for Out-of-order Processors" HPCA 2003.
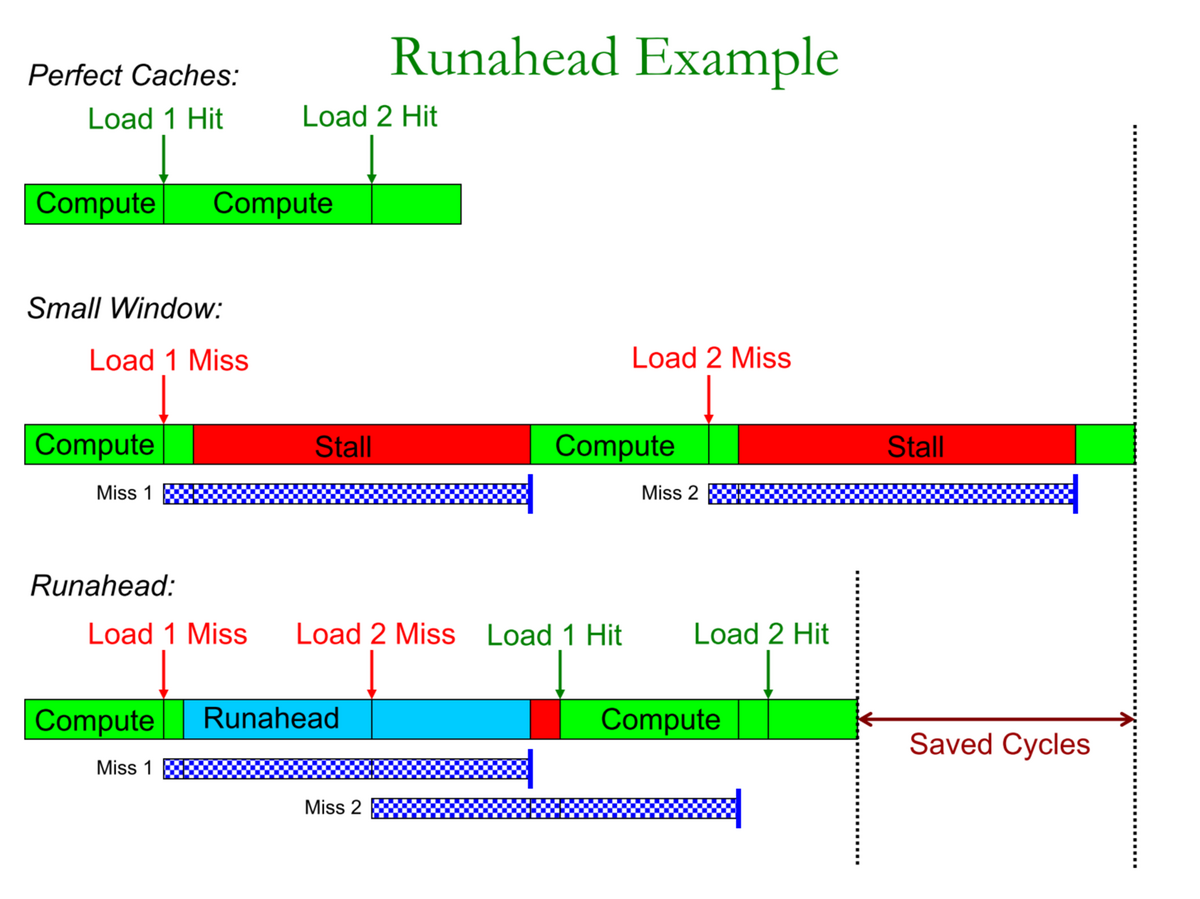
- Runahead実行の利点
- L2キャッシュ・ミス時にストールする代わりに
- L2ミス命令に依存しない事前実行されたロードとストアは、非常に正確なデータプリフェッチを生成する:
- 定期的、不定期どちらのアクセスパターンにも対応
- 予測されたプログラムパス上の命令は、命令/トレースキャッシュとL2にプリフェッチされる。
- ハードウェアプリフェッチャと分岐予測テーブルは、将来のアクセス情報を使って学習される。
- Runahead実行のメカニズム
- Runahead モードへの移行
- アーキテクチャ・レジスタの状態をチェックポイント
- Runahead モードでの命令処理
- Runahead モードからの終了
- チェックポイントからアーキテクチャ・レジスタの状態をリストア
- Runaheadモードの処理は,通常の命令処理と同じであるが,例外がある:
- 純粋に投機的である:アーキテクチャ上の(ソフトウェアから見える)レジスタやメモリの状態は、Runaheadモードでは更新されない。
- L2ミス依存命令は特定され、特別に扱われる。
- これらはすぐに命令ウィンドウから外される
- これらの結果は信用されない。
- Runahead モードへの移行
- L2ミスに依存する命令
- 2種類に分類される:INVとVALID
- INV = L2ミスに依存する
- INVは、レジスタファイルとストア・バッファのINVビットを使ってマークされる。
- INVの値はプリフェッチ/分岐解決には使用されない。
- ウィンドウから命令を削除
- 最も古い命令が疑似的なリタイアを検討する
- INVな命令は即座にウィンドウから取り除かれる。
- VALID命令は実行が完了すると削除される。
- 疑似リタイア命令は、割り当てられたリソースを解放する。
- これにより、後の命令の処理が可能になる
- 疑似的にリタイアしたストアは、そのデータを依存するロードに伝える。
- 最も古い命令が疑似的なリタイアを検討する
- Runaheadモードでのロード・ストア命令処理
- 擬似リタイヤしたストア命令は、Runaheadキャッシュと呼ばれる専用メモリにデータとINVステータスを書き込む
- 目的:ランヘッドモードでのメモリ経由のデータ通信。
- 依存するロードはRunaheadキャッシュからデータを読み込む。
- 常に正しい必要はない 🡪 ランナヘッドキャッシュのサイズは非常に小さい。
- Runaheadモードでの分岐命令処理
- INVな分岐命令は解決できない。
- 誤ったINV分岐の予測により、プロセッサはRunahead実行が終了するまで誤ったプログラム経路を進むことになる。
- VALIDな分岐命令は解決され、予測を誤るとリカバリーを開始する。
- INVな分岐命令は解決できない。
- Runahead命令のメリット
- すべてのキャッシュレベルにおけるデータ/命令に対する非常に正確なプリフェッチ
- プログラムのパスに従う
- 実行前のスレッド構築の必要なし
- メインスレッドと同じスレッドコンテキストを使用するため、コンテキストの無 駄がない。
- 実装が簡単で、ほとんどのハードウェアがすでに組み込まれている。
- すべてのキャッシュレベルにおけるデータ/命令に対する非常に正確なプリフェッチ
- 欠点/限界:
- 追加で命令が実行される
- 分岐予測精度による制限
- 依存キャッシュミスをプリフェッチできない。
- 利用可能な「メモリレベル並列性」(MLP)によって制限される効果
- メモリのレイテンシによって制限されるプリフェッチ距離