面白そうな論文があったので読んでみることにした。
Effects of MSHR and Prefetch Mechanisms on an On-Chip Cache of the Vector Architecture
https://ieeexplore.ieee.org/document/4725165
1. 概要
ベクトル・スーパーコンピュータのためのMSHRおよびプリフェッチの技法の提案について。
- MSHRが科学アプリケーションの計算性能を1.45倍向上させる。
- プリフェッチ機構は計算性能を1.6倍向上させる。
2. 関連研究
- Geeらの論文[6]:Cray X-MP / Ardent Titanによって、ベクトル・アーキテクチャにおけるキャッシュ性能の評価を行った。
- フル連想キャッシュとn-wayセット連想キャッシュを採用
- ラインサイズは16B ~ 128B、最大キャッシュサイズは4MB
- 時間的局所性は小さいが、空間性局所性は大きいことを示した。
- メモリ参照あたりの平均遅延の減少により、ベクトルプロセッサの計算性能を向上させた。
- Fuらの論文[5]:Alliant Fx/8のベクトル・マルチプロセッサ・システムにおけるハードウェア・ベースのプリフェッチ機構の効果を評価した。
- 彼らのプリフェッチ・メカニズムによって、マルチプロセッサにおける長いストライドベクトルアクセスとブロック無効かによるミスの影響を減らすことができる。
- プリフェッチ機構がプリフェッチしないキャッシュよりも優れた性能を持つこと示した。
- Bettenらの論文[3]:ベクトル・プロセッサの上にノンブロッキング・キャッシュを持つベクトル・リフィル・ユニットを提案した。
- ベクトル・メモリ・コマンドを事前に実行し、必要なキャッシュ・ラインのリフィルを通常の実行に先駆けて発行した。
- 従来の方法よりも少ないリソースで実現できることを示した。
- Cray X1[2]:
- 32バイトのキャッシュライン・サイズ
- LRUの置き換えポリシ
- BlackWindow
- 512KBのL2キャッシュ
- 8MBのL3キャッシュ
3 ベクトルアーキテクチャ用オンチップキャッシュの設計
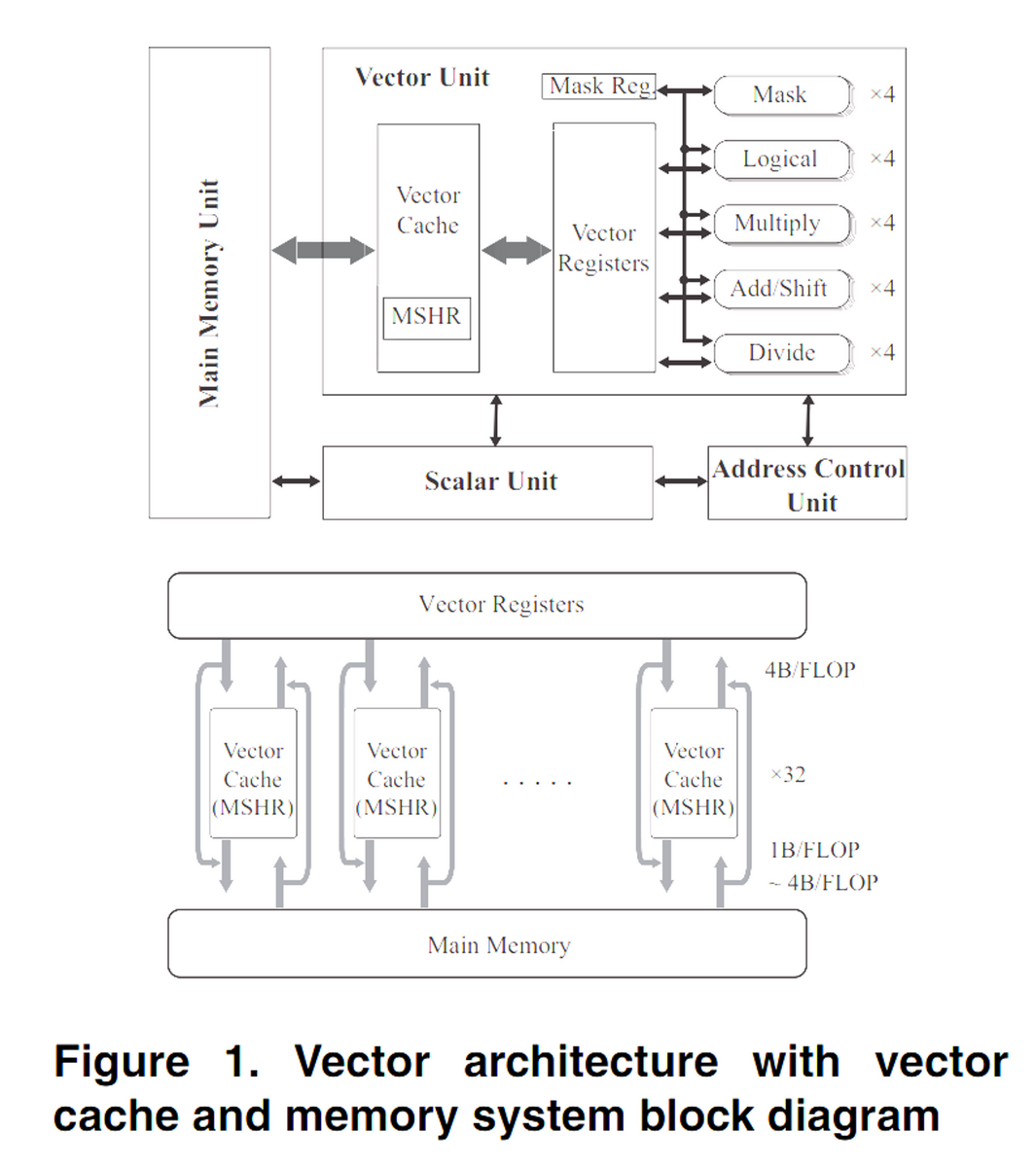
ベクトル型すーぱ・コンピュータのためのオンチップ・ベクトル・キャッシュの設計を行った。Figure.1にその概要を示す。
- ベクトル・ユニット
- アドレス制御ユニット
- スーパスカラ・ユニット
メインメモリとプロセッサは32個のメモリ・ポーとで相互接続されている。同様に、ベクトル・キャッシュは32個のサブキャッシュで構成され、サブキャッシュはベクトル・レジスタ・ファイルとメインメモリ間でバイパス機構を持つノンブロックキャッシュとなっている。
さらに、MSHRを導入し、インフライト・ロード要求を保持する。 インフライト・ロード・データが到着すると、後続のロード要求は即座にレジスタファイルに書き込まれる。 プリフェッチは、ソフトウェアによる発行を想定している。
4. 実験方法
実験用のベクトルアーキテクチャのパラメータは以下のとおりである。トレース駆動シミュレータを使用し、パラメータをモデル化する。
ロード要求のレイテンシがほかの処理で隠せない場合、あるいは複数のロード要求がプリフェッチデータを再利用できる場合、トレースファイルにプリフェッチ命令を挿入する。
| Base System Architecture | NEC SX-7 |
|---|---|
| Main Memory | DDR-SDRAM |
| Vector Cache | SRAM |
| Total Size (Sub-cache) | 8MB (256KB) |
| Associativity | 2-way |
| Cache Policy | LRU, Write Through |
| Cache Bank Cycle | 5% of memory cycle |
| Cache Latency | 15% of memory latency |
| LineSize | 8B |
| MSHR Entries (Sub-cache) | 8192 (256) |
| Memory - Cache bandwidth per flop/s | 1B/FLOP, 2B/FLOP, 4B/FLOP |
| Cache - Register bandwidth per flop/s | 4B/FLOP |
続く。