ちょっといろいろとCPUの投機実行について調べる必要があって,Runahead実行についていい資料があったのでまとめてみることにした.
資料自体は以下:Runahead Executionを最初に提案した Onur Mutlu 先生直々の講義資料なので,これを読めばまあ間違いなかろう.
前回のブログ:
- メモリレベル並列処理(MLP)
- アイデア複数のキャッシュミスを発見し、並行して処理する
- なぜ複数のミスが発生するのか?
- レイテンシのトレランスを有効化する:複数のミスのレイテンシをオーバラップさせる
- 複数のミスを発生させるには?
- アウトオブオーダー実行、マルチスレッド、ランナヘッド、プリフェッチ

- メモリ・レイテンシの許容テクニック
- キャッシング[当初はウィルクス、1965年]。
- 広く使われ、シンプルで効果的だが、効率が悪く、受動的である。
- すべてのアプリケーション/フェーズが時間的または空間的な局所性を示すわ けではない
- プリフェッチ[当初はIBM 360/91、1967年]
- 通常のメモリ・アクセス・パターンに有効
- 不規則なアクセスパターンをプリフェッチするのは難しく、不正確で、ハードウェアに負荷がかかる。
- マルチスレッド(当初はCDC 6600、1964年]
- 複数のスレッドがある場合に有効
- マルチスレッドハードウェアを使用したシングルスレッド性能の向上は、現在進行中の研究努力である。
- アウト・オブ・オーダ実行[当初はトマスロ、1967年]
- プリフェッチできないキャッシュミスを許容する
- 長いレイテンシを許容するために広範なハードウェア・リソースが必要
- キャッシング[当初はウィルクス、1965年]。
- Runahead実行 vs 大きなウィンドウの実行
- 128エントリのウィンドウとRunaheadにより,384のウィンドウと同等の性能を達成

- インオーダ実行とアウトオブオーダの比較
- In-OrderのRunahead実行とOut-of-order実行のRunahead実行

- Runahead vs. ウィンドウの大きなプロセッサ
- ウィンドウが大きくなると,逆にRunaheadの効果が小さくなっている

- インオーダ実行とアウトオブオーダ実行の比較
- メモリレイテンシが増加すると,Runahead実行の効果が大きくなる.

- ベースラインのRunahead実行のメカニズムの限界
- エネルギー効率の悪さ
- 多数の命令が投機的に実行される
- Efficient Runahead Execution [ISCA’05, IEEE Micro Top Picks’06]
- ポインタを多用するアプリケーションでは効果がない
- Runahead実行は、依存するL2キャッシュ・ミスを並列化できない
- Address-Value Delta (AVD) Prediction [MICRO’05]
- Runahead モードでの解決不可能な分岐予測ミス
- 誤予測されたL2ミス依存分岐から回復できない
- Wrong Path Events [MICRO’04]
- エネルギー効率の悪さ
- 効率の問題
- Runahead 実行により,実行される命令数が急増する.
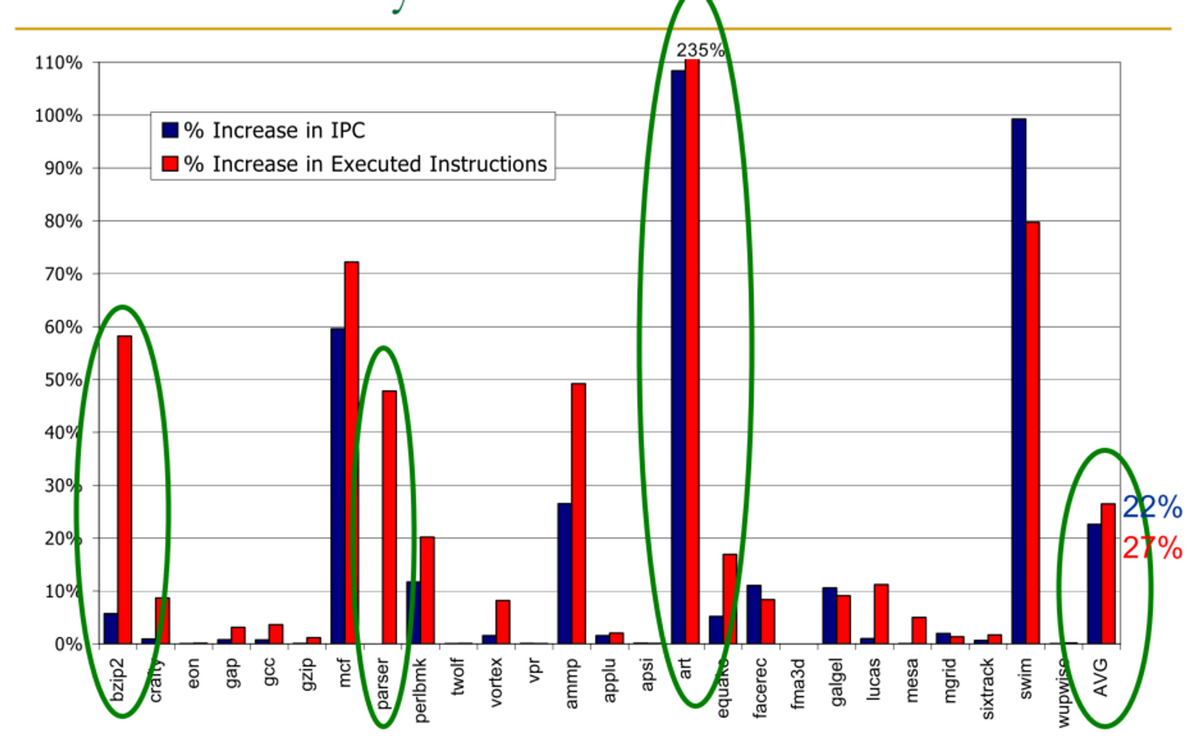
- 非効率の原因
- 短い Runahead 期間
- プリフェッチャ、間違ったパス、以前のRunahead期間によって発生したL2ミスが原因で、プロセッサが Runahead モードを開始する可能性がある。
- 赤い部分がストールの期間
- 短い Runahead が発生する (2番目のLoad 2 Missの後)
- 有用なL2ミスを生む可能性は低い
- ランナヘッド出口でのフラッシュペナルティにより、オーバーヘッドが大きい。
- 短い Runahead 期間

- 非効率の原因
- Runahead 期間の重複
- 同じ命令を実行する2つのランナヘッド期間
- Load 2 はINVになっている(たぶん Load 1に依存している)
- 2番目のRunahead期間は効率が悪い
- 同じ命令を実行する2つのランナヘッド期間
- Runahead 期間の重複

- 非効率の原因
- 無駄なRunahead 期間
- Normal モードのプリフェッチにならない期間
- Runaheadしたが,結局メモリレベル並列性が抽出できずに終わったケース
- メモリレベルの並列性がないために存在する。
- 無駄な期間をなくす仕組み
- ある期間に有用なL2ミスが発生するかどうかを予測する
- 命令ウィンドウで捕捉できないL2ミスが発生した場合、有効な期間と推定する。
- この推定に基づいて、無駄な期間予測器が学習を行う
- Normal モードのプリフェッチにならない期間
- 無駄なRunahead 期間

- Mutlu et al., "Efficient Runahead Execution: Power-Efficient Memory Latency Tolerance," IEEE Micro Top Picks 2006.
すべての解決策を適応した場合の効果(実行された命令数の削減効果)
- 平均で26.5%の命令実行増加から,6.2%の増加に減少
