HPCA2024で開催された、RISC-Vのアウト・オブ・オーダCPU XiangShanについての資料が公開されていたので、読んでみることにした。 じっくり読みたいので、1ページずつ要点を抑えていく。
次は、マイクロアーキテクチャのトピックについて。続き。
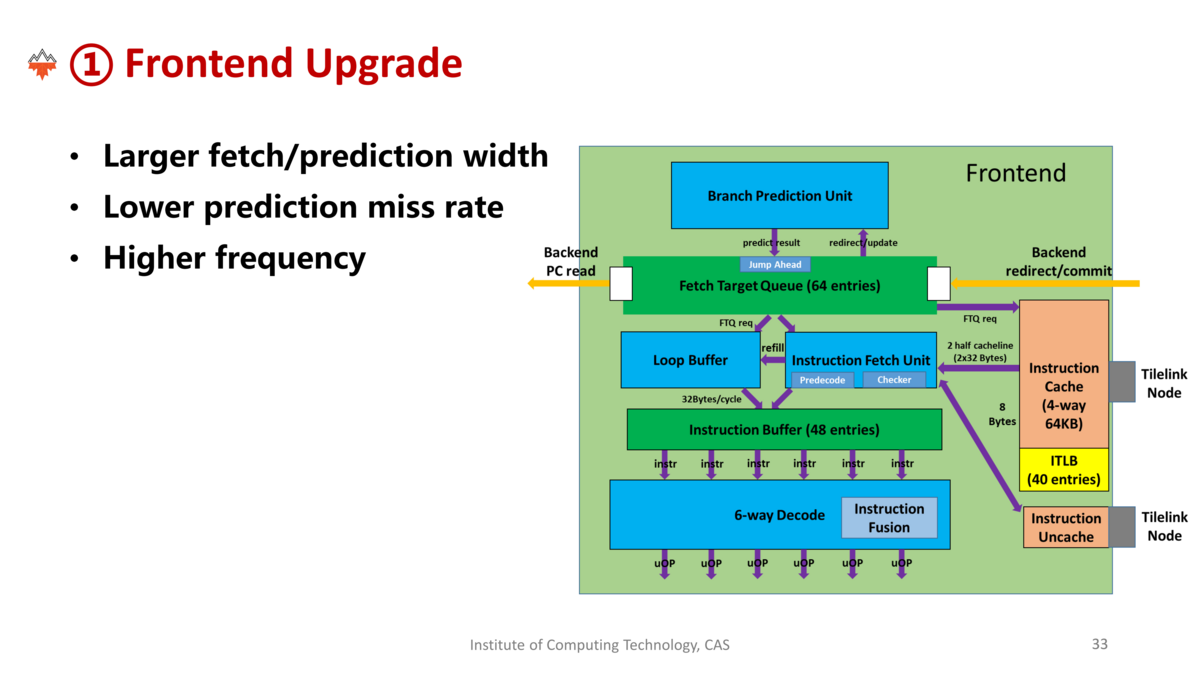
- フロントエンドのアップデート
- フェッチ・予測の幅を増強
- ミス率の低減
- 高周波数化
- TAGEの予測器の性能向上
- Branch Historyのハッシュ化
- テーブルと履歴長の調整

- L2 Fetch Target Buffer (FTB)のアップデート
- FTBは要するにBTBのこと。
- 4KBのL2 FTBを実装。
- FTBP というのは L1 & L2 の中間バッファのこと。

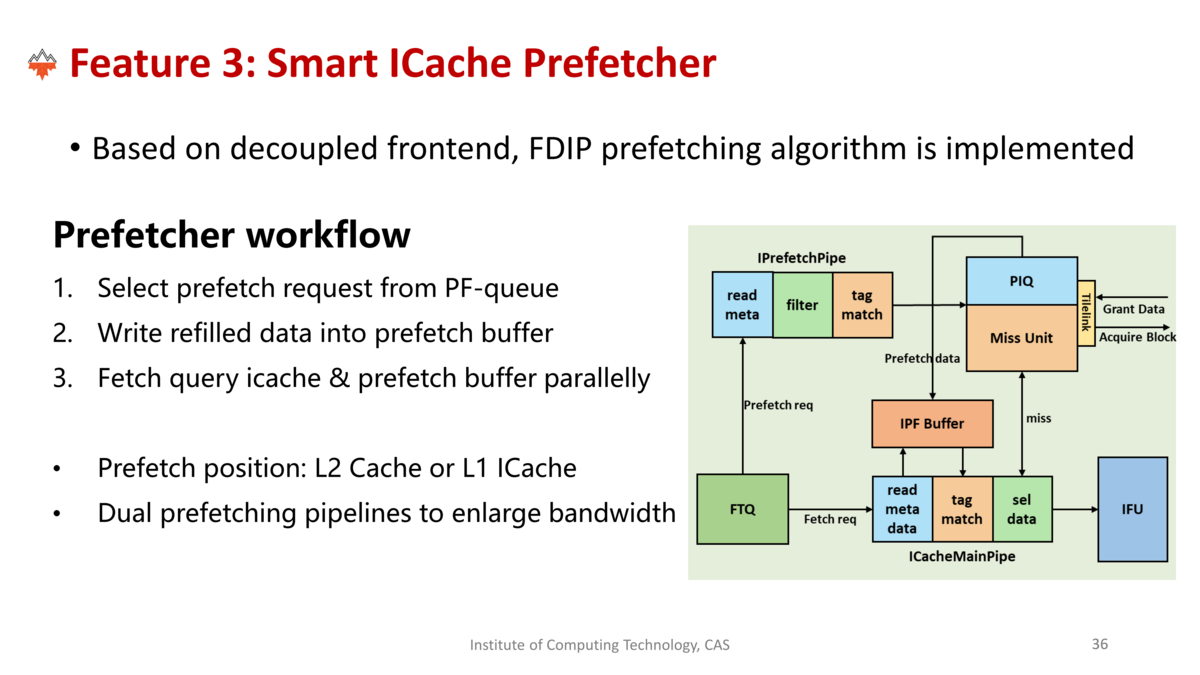
- 命令キャッシュのプリフェッチャのアップデート
- フロントエンドが分離されたので、FDIPのプリフェッチアルゴリズムを実装。
- PFキューからプリフェッチリクエストを選択
- プリフェッチバッファにリフィルデータを書き込む。
- 命令キャッシュとプリフェッチバッファの検索を並列に行う。
- バックエンドパイプラインの改良
- 発行後にレジスタを読み込むように変更
- リザベーションステーションの回路量を削減するという目的がある。
- レジスタファイルを読み込むための効率的なアービタを実装する。
- 投機的なウェイクアップとキャンセルを実装する。
- uopのコミットとリダイレクトを高速化
- リネームバッファ(RAB)を実装し、レジスタファイルの変更履歴を記録する。
- リネームバッファにレジスタファイルのマッピング情報を記録する。
- 命令がコミット・リダイレクトすると、RABをウェイクアップする
- RABはリネームテーブルをアップデートする責任を持つ
- 利点
- ROBのリリースを高速化する
- タイミングを最適化する
- Vector命令のuopへの分割をサポートする
- ROBを圧縮する
- リネームバッファ(RAB)を実装し、レジスタファイルの変更履歴を記録する。
- ベクトルパイプラインを実装
- VLEN=128のベクトル命令をサポート
- デコード・ディスパッチ・アウトオブオーダ実行を共有
- 発行後にレジスタを読み込むように変更




- ロードステアユニットのアップデート
- L1D SRAMの消費電力を削減するため、ウェイ予測を導入する
- ロードストアのバンド幅を向上させるため、ハイブリッド・ロード・ストアユニットを導入する
- L1Dプリフェッチを導入する
- StreamプリフェッチャとStrideプリフェッチャを導入する
- ロードキューのタイミングを向上させるため、ロードキューを分割する
- ロードキューを状況に応じて分割して割り当てる
- ライトバック後に仮想ロードキューから順番にリタイアすることができる
- ロードキューを状況に応じて分割して割り当てる
- TLBのタイミング向上のため、L1/L2 TLBを再デザインする


