「Spatz: A Compact Vector Processing Unit for High-Performance and Energy-Efficient Shared-L1 Clusters」という論文を読んでいる。 これは論文を読んでいるときのメモ:
https://dl.acm.org/doi/abs/10.1145/3508352.3549367
概要
- L1メモリを共有するプロセッシング・エレメントを結合し、ベクトルプロセッサとして構成することを考える。
- コンパクトなモジュール型32ビットベクトル処理ユニットSpatzを提案する。
- 4つのSniptchスカラーコアを搭載したクラスタは、32ビット整数乗算積算演算に不調なエネルギーはわずかに7.9pJである。
- SpatzベースのMemPoolシステムは、256×256の32ビット整数行列乗算を実行した場合、285GOPSを達成する。
- 同等のSnitchベースのMemPoolシステムよりも70%性能を向上する
- SpatzベースのMemPoolシステムでは、266GOPS/Wを達成する
- 128GOPS/W必要なSnitchベースのシステムよりも2倍以上のエネルギー効率を達成する。
はじめに
RISC-V Vector Extension Version 1.0の組み込みサブセットに基づくコンパクトな32ビットベクトルマシン、Spatzを提案する。
アーキテクチャ
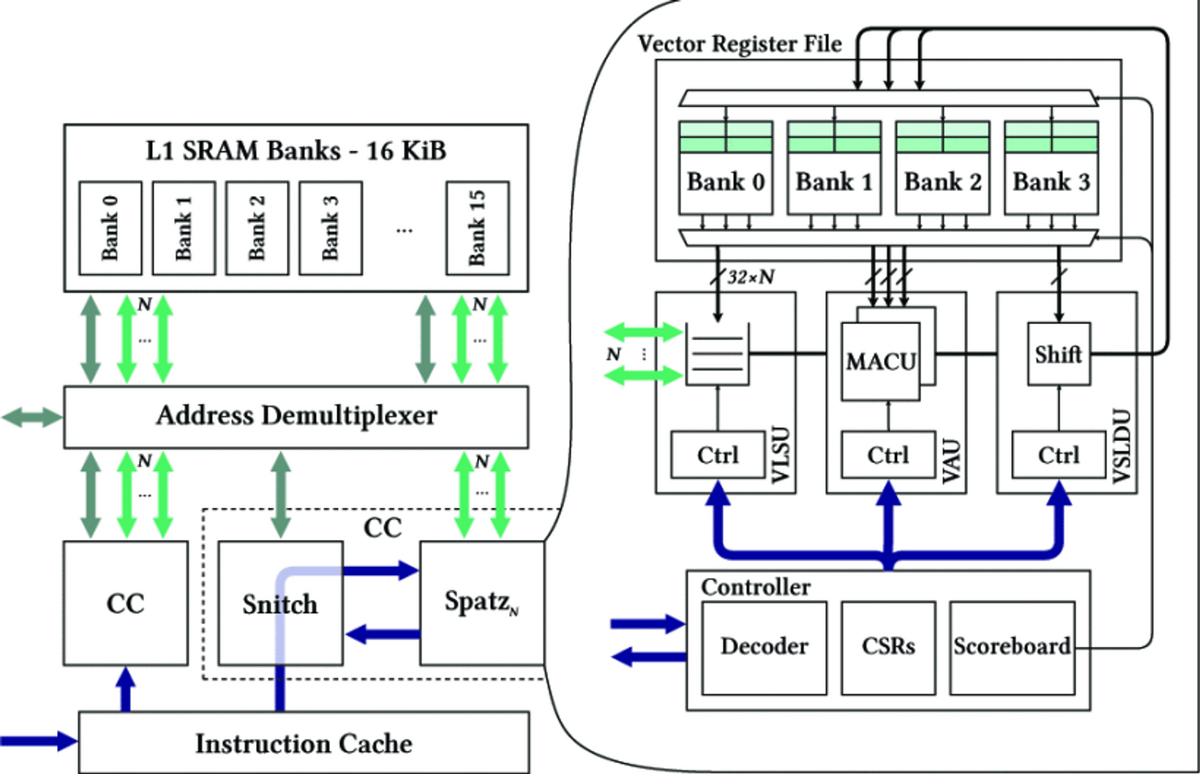
- Spatz_Nは16KBのローカルSRM(Scratch Pad Memory)を持つ小規模共有L1クラスタに結合されている。
- それぞれのバンクは1KBのSRAMバンクに分割されている。
- 各CCは、128Bと2KBのL1命令キャッシュを持つ。
- プライベート・ラッチベースのL0命令キャッシュを持つ
- アドレスベースのマルチプレクサが、CCのメモリ要求をAXIインタフェースに転送するか、クロスバに転送するかを決定する。
命令ディスパッチ
- Spatzは一般的なCORE-V X-Interface アクセラレータ・インタフェースを使用してスカラコアと通信する。
- しかしインタフェースの仕様がまだ発展途上であるため、ベクトルマシンのメモリ帯域要求にうまく適合していない。
- Spatzのベクトルロード・ストアユニットがメモリ操作を実行している間、スカラ・コアのロード・ストアユニットをストールさせることで、メモリ要求の順序を保証する。
コントローラ
- Snitch側でベクトル命令をプリデコードし、ベクトル命令とスカラオペランドをベクトルユニットにディスパッチする。
- コントローラ側でCSRを管理し、LMULの操作なども行う。
- コントローラは機能ユニットにおけるベクトル命令の実行を指揮し、ベクトル命令間のハザードはオペランドのバックプレッシャーによって処理され、チェイニングをサポートしている。
ベクトル・レジスタ・ファイル
- ベクトル・レジスタ・ファイルは3R1Wの4つのバンクを持つマルチバンク・マルチポートVRFを搭載している。各バンクはVLEN/4ビット幅で、32本のVLENビット幅のベクトル・レジスタによって、4つのVRFバンクが占められる。
- VRFはSpatzの目標MACU数を制限する要因にはならない。Spatz1コアあたり少数のMACUを搭載している。
- 集中型VRFにより、ベクトル並べ替え命令なども簡単に実現することができる。
機能ユニット
ベクトル・ロード・ストア・ユニット
- ユニット・ストライド及びコンスタント・ストライドのメモリアクセスをサポートしている。
- メモリ・インタフェースの数Nは、デザイン内のMACUの数Nと一致する。これは、メモリ帯域幅当たりのピーク演算比が0.5OP/Bであることを意味する。
- 帯域の狭いメモリインタフェースを複数搭載することにより、高速なコンスタントストライド、もしくはGather/Scatterを可能にする。
- しかし、個々のリクエストのメモリ・レスポンス間には順序保証がないため、メモリ・インタフェースとVRFの間にリオーダバッファが存在している。
ベクトル演算ユニット
- N個のMACUをホストしている。面積節約のため、MACUには4つのデータパスが存在している。
- 各データパスには、乗算器、加算器、比較器、シフタが実装されている。

- ベクトル・スライド・ユニット
- ベクトル・ストライド・ユニットにより、ベクトルの並べ替えを実行する。