RISC-Vのベクトル実装の論文を読んでいる。
https://dl.acm.org/doi/abs/10.1145/3575861
Vitruvius+というのはバルセロナスーパーコンピューティングセンターの開発しているRISC-Vベクトル拡張の実装で、初代Vitruviusの後継となる実装である。
ポイントだけまとめていく。
4 Vitruvius+ の優れた機能
以下、Vitruvius+が実装している優れた機能について説明する。これは、多くの最先端ソリューションと異なる点である。
- メモリから算術演算へのベクトル命令アウトオブオーダーチェイニングの実装
- 高速移動演算を導入することにより、ベクトル-ベクトル間の移動演算の実行を最適化。
- インターレーンリングインターコネクトの再接続機能。
- ベクトル削減演算の実行を高速化するための専用サポートを導入。
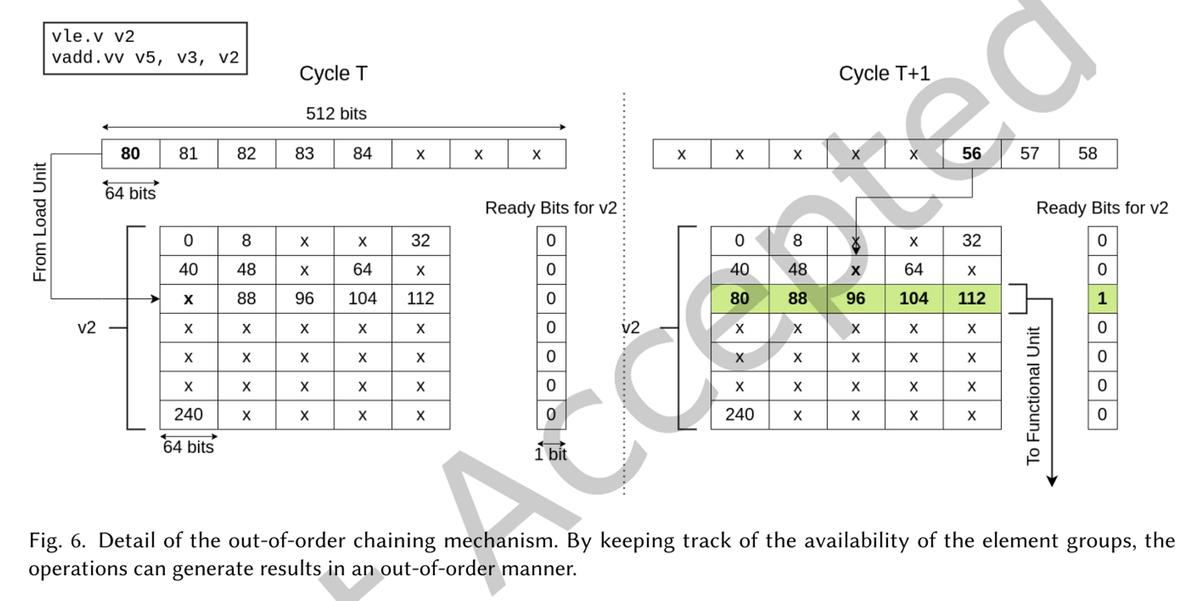
4.1 Vector Out-of-Order Chaining
- ベクトルチェイニング: あるベクトル演算の結果を、それをソースオペランドとして使用する別の演算に転送すること
- ある機能ユニットの演算結果として生成されたベクトルを、その演算の入力として使用する別の機能ユニットにバイパス実行させる (普通に考えればフォワーディング)
- メモリから演算器へのベクトルチェーン

- OVI規格の制限事項であるVPU側でのメモリ要求の受け付けができなくなるという問題を克服することができる
- 図6は、アウトオブオーダーチェイニング
Fast Moves
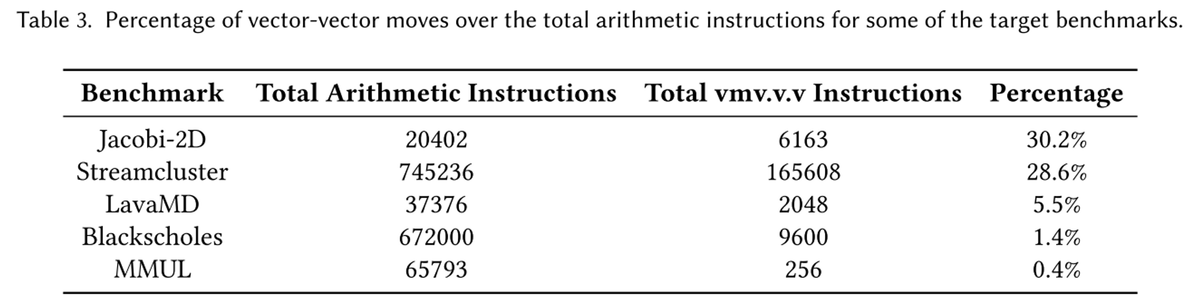
- 表3は、算術命令の総数に対するvmvの数を示している
- Jacobi-2DとStreamclusterでは、このタイプの命令が全体の算術演算のかなりの割合を占めている
- 最適化を行わない場合
- Fast Move
- リネームの際に完全に解決する
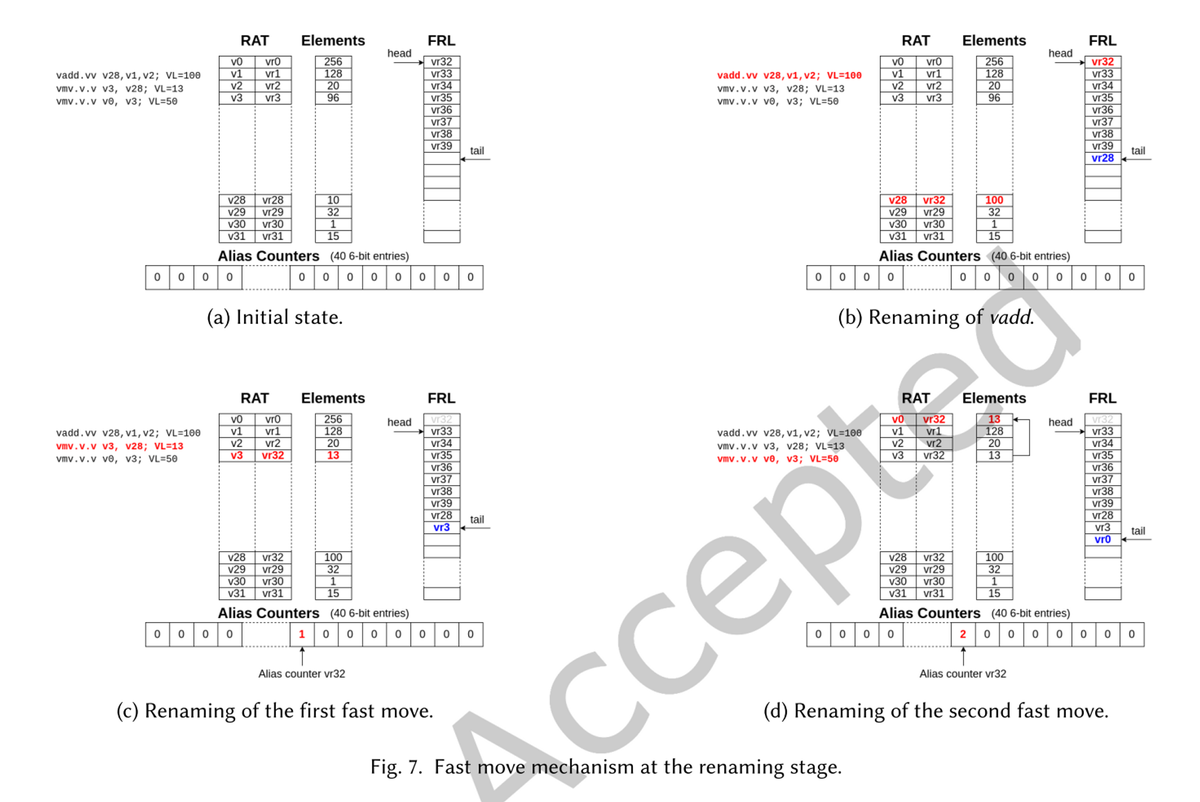
- 図7: リネームユニットに2つの追加構造体を組み込んだ
- Elements: ベクトル・レジスタが前回ベクトル演算の書き込み先となったときに割り当てられたベクトル長を記録している
- 40個のエイリアスカウンターは、物理レジスタごとに1つずつあり、同じ物理レジスタが複数の論理レジスタに割り当てられた回数を記録している
- 逆に、Fast Moveが実行されるたびに、1つの物理レジスタが複数の論理レジスタに関連付けられ、その物理レジスタにリネームされた高速移動の回数に応じてエイリアスカウンタが増加する。
- 図7aのような初期状態を想定し、図示の順序で命令がリネームステージに入るものとする。
- 図7bでは、vaddは、その宛先レジスタ
v28を物理レジスタvr32にリネームする - この命令はレーンに発行され、古い物理レジスタ
vr28はリタイア時に解放される。 - 次に、図7cに示すように、
vmvがリネームステージに入る。- この命令は、Fast Moveで実行する
- 1サイクルでRATにアクセスし、
v3とv28に割り当てられた最後の物理レジスタ(それぞれvr3とvr32)を読み出す - 次のサイクルでは、
vr32をv3に対応するRATエントリに書き込み、vr32のエイリアスカウンタとエレメントテーブルの割り当てられたエレメントの新しい値を更新する - 次のサイクルでは、ベクトルレーンで実行する必要がないため、この命令は終了する。
- これ以降、v3はベクトル長=13で
vr32にマッピングされる。 - このように、Fast Move最適化により、vmvの実行レイテンシはわずか3サイクルに短縮され、VRFへの不要なアクセスを回避することで電力消費量も削減される
- 同様に、図7dでは別の高速移動が実行されている
- 注: これもうちょっと考えて実行しないとv0の値が消えてしまいそうな…