ちょっと古い論文だが、"Decoupled Vector Architectures"という論文を読んでいる。
https://ieeexplore.ieee.org/document/501193
ベクトル命令というのは、メモリの壁を乗り越えるための手法として考案された命令セットである。メモリチップはCPUに対して10倍から100倍程度遅くなってしまい、このメモリアクセスのボトルネックをどのように解消するのかが問題となる。
すーぱスカラ・プロセッサにおいては、「キャッシュ」「マルチスレッディング」「デカップリング」を用いてこの問題を解決宇する。
この中で、プロセッサのデカップリングは、プログラムの計算を行う部分と制御を行う部分を分離することにより、メモリの遅延問題を解決するための手法である。この場合、2つの独立したプロセッサ(アドレス・プロセッサと演算プロセッサ)を持っており、それぞれは非同期で実行される。アーキテクチャ・キューを介してそれぞれが通信し、アドレスプロセッサが生成したデータはキューに格納され、計算プロセッサが取り出すまでキューにとどまることになる。
一方で、ベクトルマシンは、長いベクトルを用いることにより長いレイテンシを隠ぺいするという発想である。ベクトル演算が開始させると、長いストリームで動作するため、その待ち時間をすべての要素で効果的に償却することができるようになる。しかしそれでも、ベクトル・プロセッサが全実行サイクルの最大50%をメモリからのデータ待ちのために費やす可能性があることも示されている。
本論文では、ベクトル命令のデカップリングの原理に注目し、デカップリング・ベクトル・アーキテクチャのほうが大幅に性能が向上することができることを示す。
本論文では、評価用のベンチマークとしてPerfect Clubプログロムを用いており、Convex C3480のマシンを評価に使用している。プログラムはDixieというプログラムトレース生成ソフトウェアを使用して、トレースファイルを生成している。シミュレータはConvex C38アーキテクチャのモデルをシミュレーションするもので、単一のメモリ・ポーとベクトル・コンピュータである。これに対して、1つ目のシミュレータを拡張し、デカップリングを導入している。
まずはリファレンスアーキテクチャについて説明する。1つのメモリ・ポーとと2つの機能ユニットを持つベクトル・コンピュータである。スカラ部とベクトル部が独立して構成しており、スカラ部はスカラ・レジスタを含むすべての命令を実行し、1サイクル当たり最大1命令を実行できる。
ベクトル部は2つの演算ユニット(FU1, FU2)を搭載しており、1つのメモリ・アクセスユニット(LD)で構成される。FU2ユニットは、すべてのベクトル命令を実行することができるが、FU1ユニットは、乗算・除算・平方根を除くすべての命令を実行することができる。ベクトル・ユニットは、64ビットの要素を最大128個保持することのできる8本のベクトル・レジスタを保持している。
1本のベクトル・レジスタはレジスタ・バンクで構成されており、2つのリード・ポートと1つのライト・ポートを搭載している。コンパイラは、ポートの競合が発生しないようにベクトル命令を透けj-宇リングする必要がある。ベクトルマシンは、機能ユニット同士、ストアユニットへとベクトルを連鎖させる。一方で、ロードユニットを機能ユニットにチェーンすることはできない。この理由は、ベクトルロードは順番にベクトル要素を配送することができず、より複雑なチェーンになる可能性があるからである。これはCray-2, Cray-3も同様である。
ベンチマークの分析を行うと、リファレンス・アーキテクチャの3つのベクトル機能ユニット(FU2, FU1, LD)のみを考えると、マシンの状態は、ある時点における3つのユニットの個々の状態を表す3つの表で考えることができる。図1は6つのベンチマーク・プログラムの事項時間を8つの可能な状態に分けて示したものである。

この図では、プログラムがピークの浮動小数点速度進むサイクル(FU2, FU1, LD)もしくは(FU2, FU1, )の割合はそれほど高くなく、メモリレイテンシが増加するにつ入れて減少していることがわかる。また、ベクトル長が比較的小さいDYFESM, TRFD, SPEC77の各プログラムは、メモリレイテンシが総実行時間に与える影響が大きい。
Decoupled Vector Architecture
Decoupled Vector Architectureでは、命令ストリームを3つの異なるストリームに分割する。1つはベクトル計算命令のみで、ベクトル・プロセッサ(VP)が実行する。すべてのメモリアクセス命令(ベクトル・スカラの両方)は、Address Processor(AP)で実行される。3つ目はスカラ・モードで実行される計算命令で、Scalar Processor(SP)で実行される。
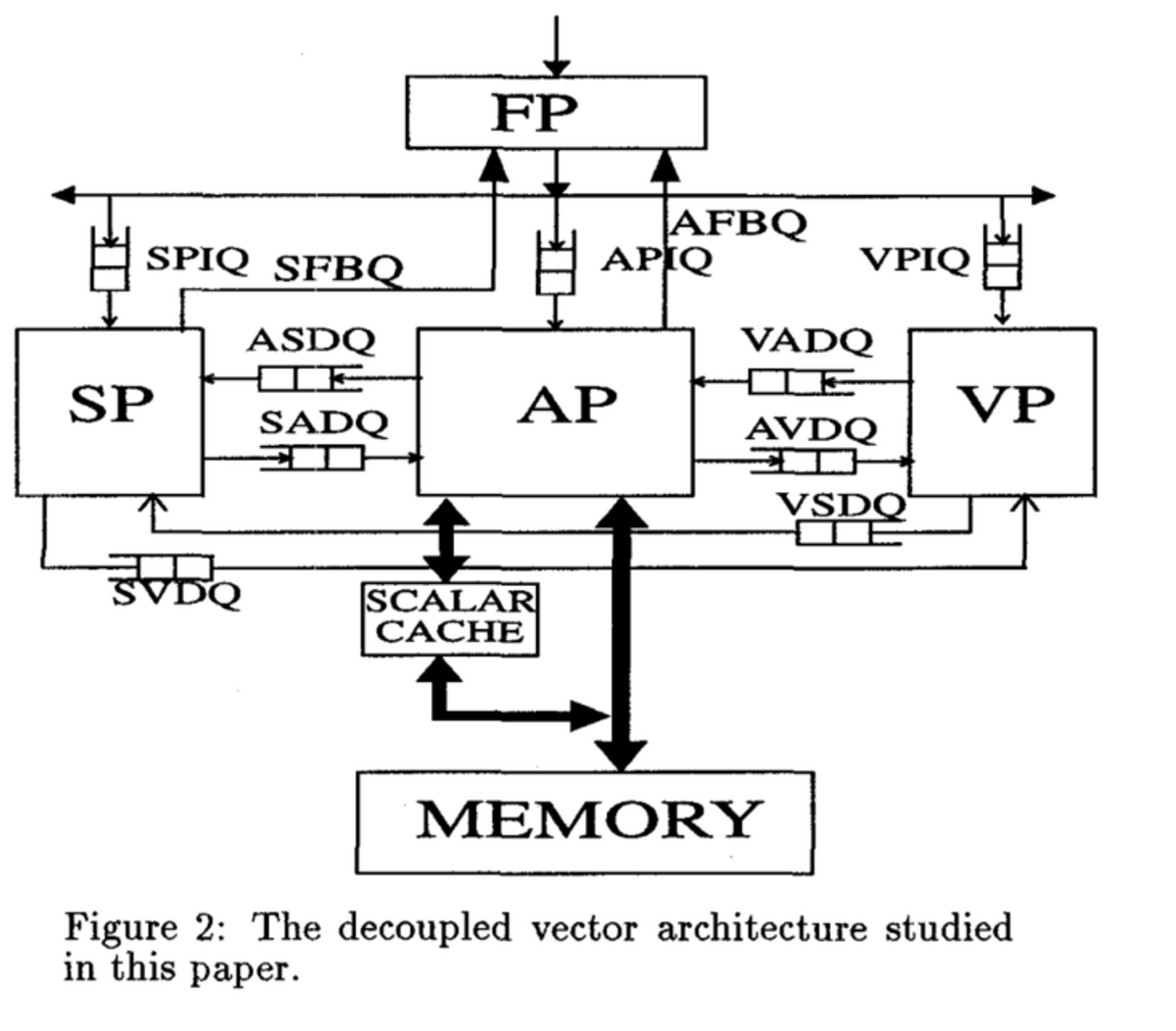
これらは1組の実装キューを介して接続される。このキューのセットは、R8000マイクロプロセッサのための浮動小数点演算部にみられる実装キューに似ている。これらの命令は、フェッチ・プロセッサ(FP)によって命令が分配される。
まずはフェッチ・プロセッサから。計算命令は、対応するユニットに送られ、メモリアクセス命令はAPに送られ、その命令の変更された命令が、データを受け取ることを期待するプロセッサに送られる。変更された命令というのは(queue mov: QMOV)は、計算プロセッサ(VPまたはSPのいずれか)に、入力キューから宛先レジスタにデータを移動するように指示される。
アドレス・プロセッサは、スカラとベクトルの両方のメモリアクセスおよびアドレス計算を実行する。ベクトルアクセスはキャッシュを経由せず、メインメモリに直接アクセスする。また、ベクトル・ロードは、その後の命令にチェーンが発生しないことを想定している。
ストア命令は2段階のプロセスで処理され、常に厳密なプログラム順序で実行される。ストア命令のアドレスがストア・アドレス・キューに保持される。APはスカラ用とベクトル用の2つのアドレスキュー(Scalar Store Address Queue: SSAQ, Vector Store Address Queue: VSAQ)を持っている。VSAQはストアの有効アドレスのベクトル長と、ストライドを保持する必要がある。対応するデータがストア・データ・キューに到着するまでそこに留まる。
ストア命令自体は、データ・キュートアドレス・・キューが一致するたびに実行される。この方式の欠点は、キューに保持されているロードとストアの間に起こりうるメモリハザードをチェックするために、動的なメモリ曖昧性の解消を使用する必要がある。
ロード命令も2段階のプロセスで実行され、ロードはストアキューのすべてのストアに対して曖昧性の解消を実行する必要がある。ベクトル・ロードの場合、曖昧性の解消は以下のように進められる。
すべてのベクトル・メモリ・アクセスについて、ベースアドレスBA、ベクトル長VL,ベクトルストライドVS、アクセス粒度Sバイトを持っている。ベクトル参照によって会うセスされるメモリの範囲を、BAとBA+(VL-1)*VS+Sの間に構成されるすべてのメモリ領域と定義すると、ベクトル・ロードは、VSAQとSSAXのストアによって定義されたすべてのメモリ範囲と照合する。
ストアに対して依存関係がある場合、ロード命令を実行する前に、ストアキューの内容をメモリに書き込む必要がある。この場合、APは最も若い違反したストアまでのキュー内のすべてのストアをメモリに送信し、実行を再開してストールしたロードを実行する。
ベクトル・プロセッサは、すべてのベクトル計算を行う。QMOVユニットは、AVDQデータ・キューからのデータをベクトル・レジスタに移動するためのキューであり、もうひとつはベクトルレジスタからVADQに転送するためのものである。
スカラ・プロセッサは、非常に単純なモデルでスカラ命令を実行するものとする。