MICRO 2021 の論文が Free Access になっているので、興味のあるものを読んでいくことにした。 Software-Defined Vectorの続き。メモリアクセスを頑張っているようだが、ここまで分散させているとちゃんとコンシステンシが取れるのか不思議に思えてくる。
https://dl.acm.org/doi/10.1145/3466752.3480099
2.3 ベクトルメモリアクセス
単一コアでの小さなメモリアクセスリクエストを集約して大きなベクトルメモリアクセスとすることで性能向上を目指す。実際のメモリアクセスはスカラコアに依存している。
- スカラコアが先に実行してデータをベクトルコアに供給する。
- スカラコア上で実行されるワイドロード命令をサポートする。
2.3.1 ベクトル・グループのためのDecoupled Access/Execute
Decoupled Access/Executeでは、スカラコアが先にメモリアクセスを実行してデータをロードし、ベクトルコアに配信する。
この方式では、ベクトルコアのローカルスクラッチパッドメモリをベクトルへの転送用のキューとして使用する。このキューでは、読み込まれたデータをフレームと呼ばれるメモリの塊に整理する。各フレームでは、マイクロスレッドが消費する必要のあるデータが含まれている。
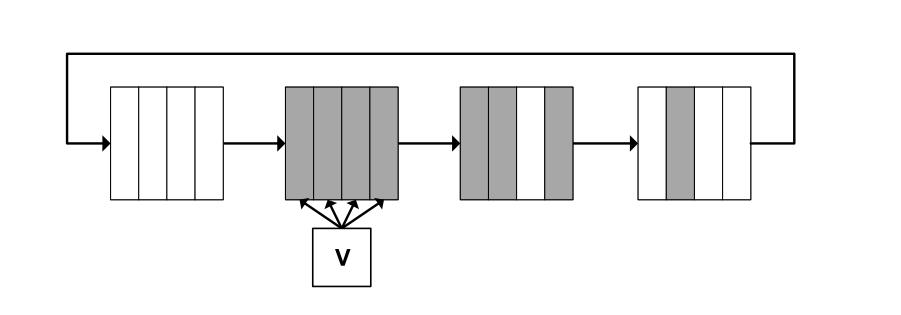
図3は、フレームキューの論理構成を示したものです。スカラコアはロードを発行してフレームを生成し、ベクターコアはフレームを生成順に消費しますが、フレーム内にデータが到着する順番は関係ありません。ベクトルコアは、フレームサイズの領域の円形バッファをスクラッチパッドに保持します。図4は、この円形バッファの状態の一例を示しています。コアがキューの先頭から読み出している間に、メモリシステムは同時に未来のフレームをファイリングします。
図3は、フレームキューの論理構造を示したものである。
- スカラコアがロード命令を発行する。このときにフレームを生成する。
- ベクトルコアはフレームを生成順に消費する。ベクトルコアはフレームと同じサイズのリングバッファをスクラッチパッドに保持する。
- ベクトルコアがキューの先頭からデータを読みだしている間に、メモリシステムは同時に将来のフレームを取り込む。
ベクトルグループを形成する前に、フレームサイズとフレームの全体サイズをCSRに書き込むことですべてのコアはフレームを構成する。この作業は、論理フレームキューをスクラッチパッド上に構成することで実現する。

マイクロスレッドコード内では、ベクトルコアがそれぞれのスクラッチパッドからフレームを消費する。frame_start命令によって、キューの先頭にあるフレームの準備が整うまで、現在のマイクロスレッドをストールさせる。フレームの消費が終わると、ベクトルコアは現在のフレームを解放するためにremem命令を使用する。
C言語レベルでは、ベクターコアでのフレームの使用は次のようになる。
int frame_ptr = FRAME_START (); int a = spad[frame_ptr + 0]; int b = spad[frame_ptr + 1]; int c = a + b; REMEM ();
このDecoupled Access/Execute機構は、ロードパスにのみ使用され、ストアでは使用されない。
2.3.2 ワイドベクトルロード
ベクトルグループのロードを集中管理することにより、データの連続したチャンクをまとめて、ベクトル命令によってまとめロードするためである。このアーキテクチャでは、スカラコアがベクトルグループに変わってロード命令を実行する。ベクトルロードは、LLCにキャッシュラインを要求し、キャッシュデータをベクトルコアに1チャンクずつ分配する。
ノンブロッキングベクトルアクセスの多面新しい命令を追加する。
vload sp, add, off, width, var
オペランドの定義:
- 受信側スクラッチパッドのオフセット
- ソースメモリアドレス
- 最初の応答を受けるベクトルグループのコアのオフセット
- ベクトルコアごとのアクセス幅
- バリアント
vloadはデフォルトではAlignedキャッシュラインのみをサポートしているが、命令を組み合わせることでUnalignedロードもサポートしている。
ベクトルロードは、アクセスされたキャッシュラインの各部分をどこに送るかをLLCに指示するための3つのバリアントをサポートしている。
図5は、各バリアントのリクエストとレスポンスの経路を示したものです。
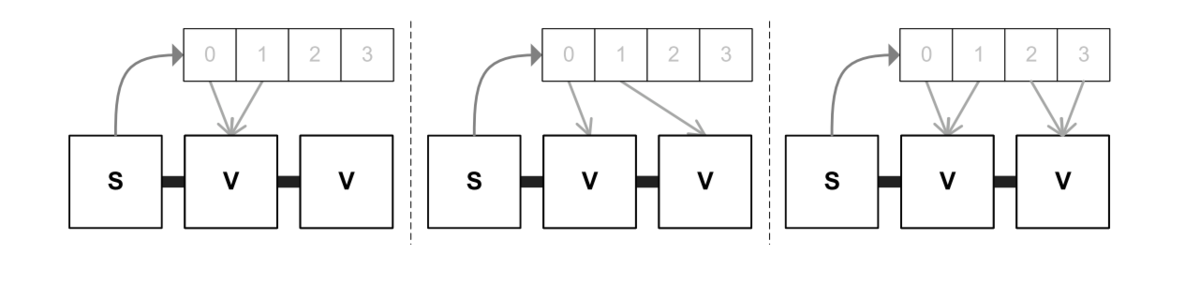
サポートされているバリアントで、多くのパタンを効率的にマッピングできることが分かった。以下のようなプログラムを考えてみる。
for (int i = tid; i < N; i += VLEN) for (int j = 0; j < M; j += FLEN) c[i] += a[i*M+j];
各ベクトルコアはj次元の和を個別に実行する。スカラ―コアは、通常ならば以下のようにメモリアクセスを発行する必要がある。
for (int core = 0; core < VLEN; core ++) vload sp , a[(i+core)*N+j], core , FLEN , SINGLE;
しかし、作業分担の方法を変えれば、より効率的な方法を採用することができる。
for (int i = 0; i < N; i++) for (int j = tid*FLEN; j < M; j += FLEN*VLEN) c_partial [i] += a[i*M+j];
スカラーコアは、j の連続したチャンクを各コアにフェッチして、部分的な和を生成する。この場合、グループロードを使用して、FLEN*VLEN相当のデータをフェッチすることができる。
追加コストとして、部分和のリダクションが必要になりますが、これはある程度安価に行うことができます。
単一レベルのループネストなどでは、どのような方法でもよいのですが、その選択は妥当性よりも性能によります。グループロードは、スカラ命令やメモリ要求が少なくて済むので、より効率的です。
2.4 ベクトルOddとEnd
ベクトルグループは、古典的なベクトルマシンをエミュレートして、predicate, gather/scatter/shuffleなどのベクトル操作をサポートする。
Predicateにより、ベクトルマシンは制御フローを分岐させることなく条件付き実行を行うことができる。マイクロスレッドは各ベクトルコア上の1ビットフラグを使用してPredicateをサポートしている。
pred_eq rs1, rs2 pred_neq rs1, rs2
flagが0の場合、ベクトルコアは後続のpredicate命令によってflagが1になるまで、すべての命令をnopとして実行する。
if (cond == 1) { c = a + b; }
上記のC言語コードは、このように実装することができる。
PRED_EQ(cond , 1); c = a + b; PRED_EQ (0, 0);
Scatter/Gather命令は、ベクトルグループ内で、各コアがワードサイズのメモリ操作を行うことで実現でき切る。各アクセスはノンブロッキングで、各コンポーネントのメモリアクセスを待つためにベクトルグループ全体がストールすることを防ぐ。
Shuffle命令は、他のコアのスクラッチパッドを使用して、リモートストアを行う(メニーコアアーキテクチャでは一般的な機能である)。