自作RISC-V アウトオブオーダCPUを作っているのだが、そろそろ乗算器を付けないとテストパタンが増やせなくなってきた。 乗算器・除算器をまじめに作るのはあまり得意ではないので、Rocket-ChipやBOOMのデザインを参考にして作ってみることにした。
Rocket-Chipには2種類の乗算器が実装されている。UnpipelinedなバージョンとPipelinedなバージョンだ。 まずはUnpipelinedなバージョンについて見ていく。こちらはRocket-Chipの標準構成にて採用されている。
chipyard/generators/rocket-chip/src/main/scala/rocket/Multiplier.scala
class MulDiv(cfg: MulDivParams, width: Int, nXpr: Int = 32) extends Module { private def minDivLatency = (cfg.divUnroll > 0).option(if (cfg.divEarlyOut) 3 else 1 + w/cfg.divUnroll) private def minMulLatency = (cfg.mulUnroll > 0).option(if (cfg.mulEarlyOut) 2 else w/cfg.mulUnroll) def minLatency: Int = (minDivLatency ++ minMulLatency).min ...
このMulDivユニットには、大きく2つのパラメータがある。
cfg.mulUnroll: 乗算器のアンロールする数を指定している。Unrollは、つまり1サイクルに何ビットの乗算を行うかを指定している。例えばXLEN=64でmulUnroll=8を設定している場合、64/8=8サイクル掛けて乗算が実行されるという算段になる。cfg.mulEarlyOut: 乗算器のサイクル数が固定ではなくなり、乗算途中でこれ以上計算する必要がない場合(つまりオペランドのどちらかが残り0になった場合)計算を途中で終了し結果を出力する。
このMulDivユニットが持つレジスタと、計算の流れを大まかに図にしてみる。
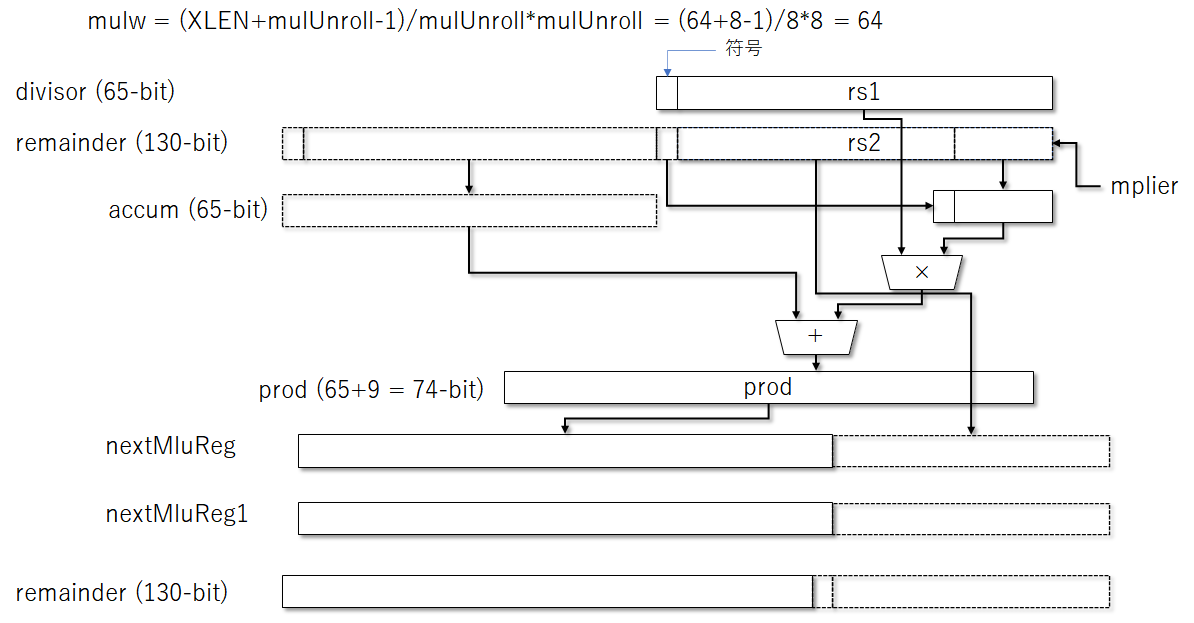
Scalaのソースコードはこのようになっている。XLEN/mulUnrollの回数だけこのループが繰り返される。
if (cfg.mulUnroll != 0) when (state === s_mul) { val mulReg = Cat(remainder(2*mulw+1,w+1),remainder(w-1,0)) val mplierSign = remainder(w) val mplier = mulReg(mulw-1,0) val accum = mulReg(2*mulw,mulw).asSInt val mpcand = divisor.asSInt val prod = Cat(mplierSign, mplier(cfg.mulUnroll-1, 0)).asSInt * mpcand + accum val nextMulReg = Cat(prod, mplier(mulw-1, cfg.mulUnroll)) val nextMplierSign = count === mulw/cfg.mulUnroll-2 && neg_out val eOutMask = ((BigInt(-1) << mulw).S >> (count * cfg.mulUnroll)(log2Up(mulw)-1,0))(mulw-1,0) val eOut = (cfg.mulEarlyOut).B && count =/= mulw/cfg.mulUnroll-1 && count =/= 0 && !isHi && (mplier & ~eOutMask) === 0.U val eOutRes = (mulReg >> (mulw - count * cfg.mulUnroll)(log2Up(mulw)-1,0)) val nextMulReg1 = Cat(nextMulReg(2*mulw,mulw), Mux(eOut, eOutRes, nextMulReg)(mulw-1,0)) remainder := Cat(nextMulReg1 >> w, nextMplierSign, nextMulReg1(w-1,0)) count := count + 1 when (eOut || count === mulw/cfg.mulUnroll-1) { state := s_done_mul resHi := isHi } }
まず結論から言うと、計算結果はremainderの上位ビットに溜まっていくことになる。
remainderは(XLEN+1)*2のビットを持っており、XLENにさらに符号ビット、そして計算対象となる下位ビットと計算結果を格納する上位ビットを格納している。
一方でdivisorはXLEN+1ビットを持っており、XLENにデータ、そして符号ビットを最上位に付けている。これはループで更新されない。
乗算は、divisorとremainderの下位unrollビットを引き抜いて乗算を行う。これがScalaコードのprodに相当する。accumはremainderの上位ビットに相当する。
val prod = Cat(mplierSign, mplier(cfg.mulUnroll-1, 0)).asSInt * mpcand + accum
最終的に乗算が終了すると、ステートマシンはstateはs_done_mulに移行され、計算は完了する。
一方でパイプライン版はよりシンプルだ。上記のステートマシンの更新が必要ないので、単純に乗算が実行される。 これだけだと何のパイプライン化もされていないが、これはDesign CompilerかVivadoか何かでタイミング調整が行われることを想定しているようだ。
class PipelinedMultiplier(width: Int, latency: Int, nXpr: Int = 32) extends Module with ShouldBeRetimed { val io = IO(new Bundle { val req = Flipped(Valid(new MultiplierReq(width, log2Ceil(nXpr)))) val resp = Valid(new MultiplierResp(width, log2Ceil(nXpr))) }) ... val lhs = Cat(lhsSigned && in.bits.in1(width-1), in.bits.in1).asSInt val rhs = Cat(rhsSigned && in.bits.in2(width-1), in.bits.in2).asSInt val prod = lhs * rhs val muxed = Mux(cmdHi, prod(2*width-1, width), Mux(cmdHalf, prod(width/2-1, 0).sextTo(width), prod(width-1, 0))) val resp = Pipe(in, latency-1) io.resp.valid := resp.valid io.resp.bits.tag := resp.bits.tag io.resp.bits.data := Pipe(in.valid, muxed, latency-1).bits }