NaxRiscvのドキュメントを、改めて位置から読んでみることにしたいと思う。
実行ユニット
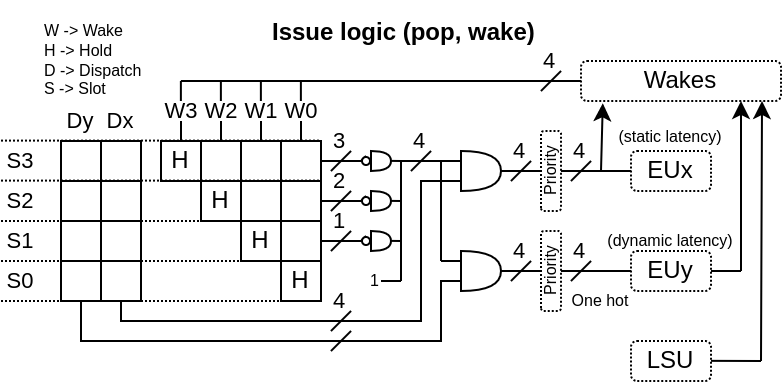
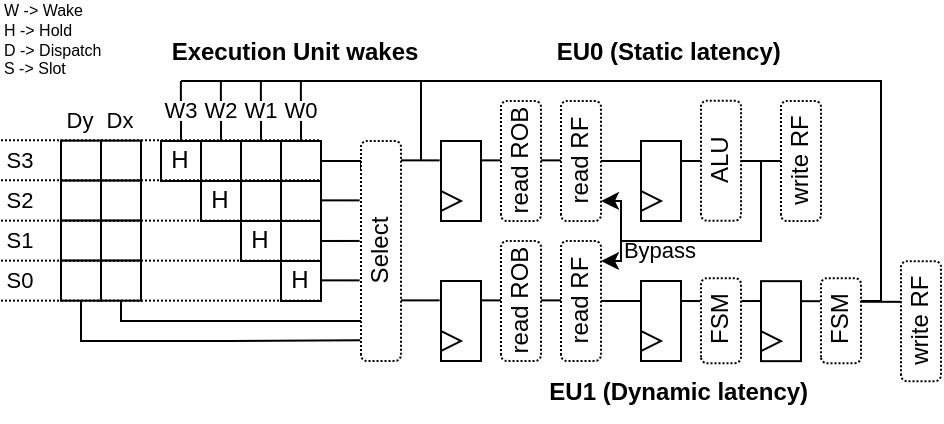
実行ユニットの主な特徴は、それに依存する命令をウェイクアップする方法である。
- 静的ウェイクアップ : 固定レイテンシ(ストールなし)のEUの場合、発行キューは静的ウェイクアップが可能である。これにより、complete-to-useの遅延を2サイクル短縮できる。
- 動的ウェイクアップ : 可変レイテンシ(ストールあり)のEUの場合、EUは発行キューにウェイクアップ・コマンドを送信する責任がある。
以下は、2つのEU(静的ウェイクアップと動的ウェイクアップのそれぞれ1つ)が、依存する命令をウェイクアップさせるために、発行キューとやりとりする様子を示した図解である。
カスタム命令
NaxRiscvにカスタム命令を追加するにはいくつかの方法がある。本節ではいくつかのデモを示す。
SIMD add命令
整数レジスタファイル上で動作するSIMD加算(4x8ビット加算器)を実装するプラグインを定義しよう。
このプラグインは、ALUプラグインの実装をよりシンプルにするExecutionUnitElementSimpleをベースとする。このようなプラグインは、指定の実行ユニット(ExecutionUnitBaseがホスト)を構成するために使用できる。
例えば、プラグイン構成は次のようになる。
plugins += new ExecutionUnitBase("ALU0") plugins += new IntFormatPlugin("ALU0") plugins += new SrcPlugin("ALU0", earlySrc = true) plugins += new IntAluPlugin("ALU0", aluStage = 0) plugins += new ShiftPlugin("ALU0" , aluStage = 0) plugins += new ShiftPlugin("ALU0" , aluStage = 0) plugins += new SimdAddPlugin("ALU0") // <- このプラグインを実装することになる
プラグインの実装
以下はこのプラグインをどのように実装するかの例である: (https://github.com/SpinalHDL/NaxRiscv/blob/d44ac3a3a3a4328cf2c654f9a46171511a798fae/src/main/scala/naxriscv/execute/SimdAddPlugin.scala#L36)
package naxriscv.execute import spinal.core._ import spinal.lib._ import naxriscv._ import naxriscv.riscv._ import naxriscv.riscv.IntRegFile import naxriscv.interfaces.{RS1, RS2} import naxriscv.utilities.Plugin //このプラグインの例では SIMD_ADD と呼ばれる以下の処理を行う新しい命令を実装する // //RD : Regfile Destination, RS : Regfile Source //RD( 7 downto 0) = RS1( 7 downto 0) + RS2( 7 downto 0) //RD(16 downto 8) = RS1(16 downto 8) + RS2(16 downto 8) //RD(23 downto 16) = RS1(23 downto 16) + RS2(23 downto 16) //RD(31 downto 24) = RS1(31 downto 24) + RS2(31 downto 24) // //Instruction encoding : //0000000----------000-----0001011 <- Custom0 func3=0 func7=0 // |RS2||RS1| |RD | // //Note : RS1, RS2, RD のビット位置はRISC-Vの仕様に準拠しており、このISAのすべての命令において共通である。 object SimdAddPlugin{ //命令タイプとエンコーディングを定義する val ADD4 = IntRegFile.TypeR(M"0000000----------000-----0001011") } //ExecutionUnitElementSimpleは、同じeuIdを持つExecutionUnitBaseによって提供されるパイプラインに結合されるベースクラスである。 // これは、カスタム命令の実装を容易にするための多数のユーティリティを提供する。 // ここでは、SIMD加算をレジスタファイルに追加するプラグインを実装する。 // staticLatency=true は、このプラグインがパイプラインを停止させることは決してないことを指定し、その結果に依存する命令を静的に発行キューで実行できるようにする。 class SimdAddPlugin(val euId : String) extends ExecutionUnitElementSimple(euId, staticLatency = true) { //このプラグインが完全に組み合わせ回路で構成されると仮定する override def euWritebackAt = 0 // セットアップコードは、プラグインが互いのことを指定するもので、手遅れになる前に設定する。 override val setup = create early new Setup{ //Let's assume we only support RV32 for now assert(Global.XLEN.get == 32) //現在のプラグインがADD4命令を実装することを実行ユニットベースに指定する。 add(SimdAddPlugin.ADD4) } override val logic = create late new Logic{ val process = new ExecuteArea(stageId = 0) { //Get the RISC-V RS1/RS2 values from the register file val rs1 = stage(eu(IntRegFile, RS1)).asUInt val rs2 = stage(eu(IntRegFile, RS2)).asUInt //Do some computation val rd = UInt(32 bits) rd( 7 downto 0) := rs1( 7 downto 0) + rs2( 7 downto 0) rd(16 downto 8) := rs1(16 downto 8) + rs2(16 downto 8) rd(23 downto 16) := rs1(23 downto 16) + rs2(23 downto 16) rd(31 downto 24) := rs1(31 downto 24) + rs2(31 downto 24) //Provide the computation value for the writeback wb.payload := rd.asBits } } }
NaxRiscv の生成
次に、新しいプラグイン付きのNaxRiscvを生成するために、以下のAppを実行することができる : (https://github.com/SpinalHDL/NaxRiscv/blob/d44ac3a3a3a4328cf2c654f9a46171511a798fae/src/main/scala/naxriscv/execute/SimdAddPlugin.scala#L71)
object SimdAddNaxGen extends App{ import naxriscv.compatibility._ import naxriscv.utilities._ def plugins = { //Get a default list of plugins val l = Config.plugins( withRdTime = false, aluCount = 2, decodeCount = 2 ) //Add our plugin to the two ALUs l += new SimdAddPlugin("ALU0") l += new SimdAddPlugin("ALU1") l } //Create a SpinalHDL configuration that will be used to generate the hardware val spinalConfig = SpinalConfig(inlineRom = true) spinalConfig.addTransformationPhase(new MemReadDuringWriteHazardPhase) spinalConfig.addTransformationPhase(new MultiPortWritesSymplifier) //Generate the NaxRiscv verilog file val report = spinalConfig.generateVerilog(new NaxRiscv(xlen = 32, plugins)) //Generate some C header files used by the verilator testbench to connect to the DUT report.toplevel.framework.getService[DocPlugin].genC() }
このAppを実行するために、NaxRiscvのディレクトリで以下を実行する:
sbt "runMain naxriscv.execute.SimdAddNaxGen"
ソフトウェアテスト
次に、アセンブリテストコードを書こう : (https://github.com/SpinalHDL/NaxSoftware/tree/849679c70b238ceee021bdfd18eb2e9809e7bdd0/baremetal/simdAdd)
.globl _start
_start:
#include "../../driver/riscv_asm.h"
#include "../../driver/sim_asm.h"
#include "../../driver/custom_asm.h"
//Test 1
li x1, 0x01234567
li x2, 0x01FF01FF
opcode_R(CUSTOM0, 0x0, 0x00, x3, x1, x2) //x3 = ADD4(x1, x2)
//Print result value
li x4, PUT_HEX
sw x3, 0(x4)
//Check result
li x5, 0x02224666
bne x3, x5, fail
j pass
pass:
j pass
fail:
j fail
以下のようにしてコンパイルする
make clean rv32im
シミュレーション
src/test/cpp/naxriscv のシミュレーションを実行する (最初にreadmeに書いてあるセットアップを行う必要がある)
make clean compile ./obj_dir/VNaxRiscv --load-elf ../../../../ext/NaxSoftware/baremetal/simdAdd/build/rv32im/simdAdd.elf --spike-disable --pass-symbol pass --fail-symbol fail --trace
シェルに2224666と表示されれば成功である :D
Conclusion
したがって、この例では、追加のデコードの指定方法や、マルチサイクルALUの定義方法については紹介していない。(TODO)。 しかし、IntAluPlugin、ShiftPlugin、DivPlugin、MulPlugin、BranchPluginでは、同じExecutionUnitElementSimpleベースクラスを使用して、それらの処理を行っている。
また、ExecutionUnitElementSimpleベースクラスを使用する必要はなく、LoadPlugin、StorePlugin、EnvCallPluginのように、より基本的なアクセスも可能である。
ハードコアな方法
同じ命令の例だが、ExecutionUnitElementSimpleの機能を使用せずに実装した例を以下に示す: (https://github.com/SpinalHDL/NaxRiscv/blob/72b80e3345ecc3a25ca913f2b741e919a3f4c970/src/main/scala/naxriscv/execute/SimdAddPlugin.scala#L100)
object SimdAddRawPlugin{ val SEL = Stageable(Bool()) //Will be used to identify when we are executing a ADD4 val ADD4 = IntRegFile.TypeR(M"0000000----------000-----0001011") } class SimdAddRawPlugin(euId : String) extends Plugin { import SimdAddRawPlugin._ val setup = create early new Area{ val eu = findService[ExecutionUnitBase](_.euId == euId) eu.retain() //We don't want the EU to generate itself before we are done with it //Specify all the ADD4 requirements eu.addMicroOp(ADD4) eu.setCompletion(ADD4, stageId = 0) eu.setStaticWake(ADD4, stageId = 0) eu.setDecodingDefault(SEL, False) eu.addDecoding(ADD4, SEL, True) //IntFormatPlugin provide a shared point to write into the register file with some optional carry extensions val intFormat = findService[IntFormatPlugin](_.euId == euId) val writeback = intFormat.access(stageId = 0, writeLatency = 0) } val logic = create late new Area{ val eu = setup.eu val writeback = setup.writeback val stage = eu.getExecute(stageId = 0) //Get the RISC-V RS1/RS2 values from the register file val rs1 = stage(eu(IntRegFile, RS1)).asUInt val rs2 = stage(eu(IntRegFile, RS2)).asUInt //Do some computation val rd = UInt(32 bits) rd( 7 downto 0) := rs1( 7 downto 0) + rs2( 7 downto 0) rd(16 downto 8) := rs1(16 downto 8) + rs2(16 downto 8) rd(23 downto 16) := rs1(23 downto 16) + rs2(23 downto 16) rd(31 downto 24) := rs1(31 downto 24) + rs2(31 downto 24) //Provide the computation value for the writeback writeback.valid := stage(SEL) writeback.payload := rd.asBits //Now the EU has every requirements set for the generation (from this plugin perspective) eu.release() } }