NaxRiscvのドキュメントを、改めて位置から読んでみることにしたいと思う。
Frontend
デコーダ
特になし。
物理レジスタ割り当て
物理レジスタ割り当ては、割り当てられていない物理レジスタのインデックスを含む循環バッファを実装することで行われる。 これは、分散RAMを搭載したFPGAにうまく適合する。
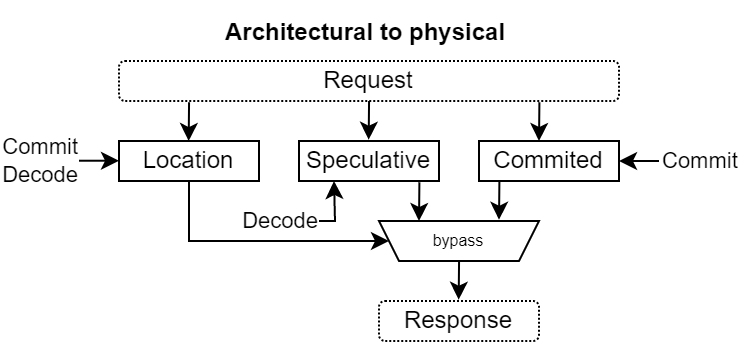
アーキテクチャ・レジスタから物理レジスタ
アーキテクチャ・レジスタファイルから物理レジスタへの変換は、以下の3つのテーブルを実装することで行われる。
- 投機的マッピング:アーキテクチャ・インデックスから物理インデックスへの変換。命令デコード後に更新され、分散RAMで実装される
- コミット後マッピング : アーキテクチャ・インデックスから物理インデックスへの変換。命令のコミット後に更新され、分散RAMで実装される
- Location : アーキテクチャ・インデックスから、使用すべきマッピング・テーブル(投機的マッピングテーブル またはコミット後マッピングテーブル)への変換。レジスタとして実装される(分岐の予測ミスが発生した場合はクリアする必要がある)。
これにより、パイプラインが分岐を誤って予測した場合に、変換の状態を即座に元に戻すことができる。
物理インデックスからROB ID
依存関係の物理レジスタファイルが計算されると、それらは依存するROB IDに変換される。これは次の2つの方法で行われる。
- ROBマッピング:物理インデックスからROB IDに変換する分散RAM
- ビジー:指定されたROB IDがまだ実行中であるかどうかを指定する。これは命令がディスパッチされたときに設定され、命令が完了したときにクリアされる。
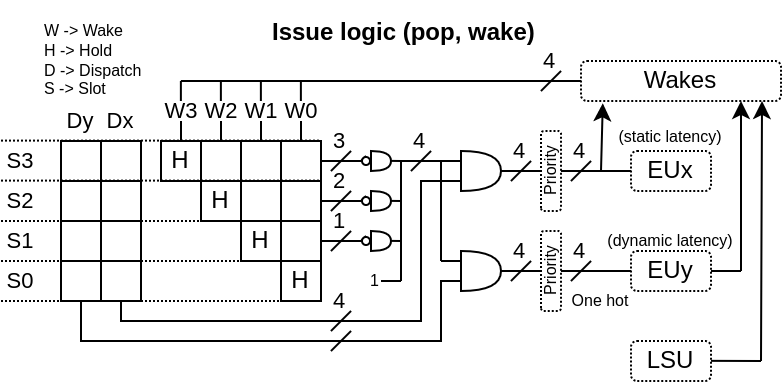
ディスパッチ/命令発行
現在の実装に関する具体的なポイントをいくつか挙げてみる。
- ユニファイドディスパッチ・命令発行:主に領域を節約するため、また各エントリーの使用頻度を最大限に高めるため
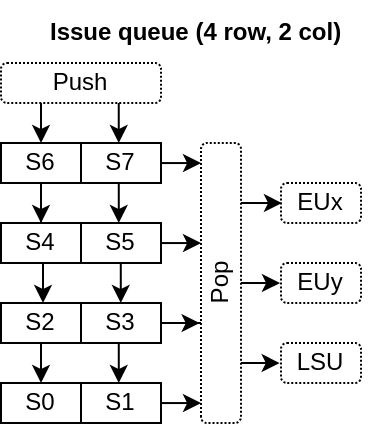
- 2Dキュー:エントリーはC=decodeCount列、L=slotCount/decodeCount行に配置される
- 行プッシュ : キューに何かがプッシュされると、その行全体が「消費」される。たとえその行が完全に使用されていない場合でも、行全体を消費する。
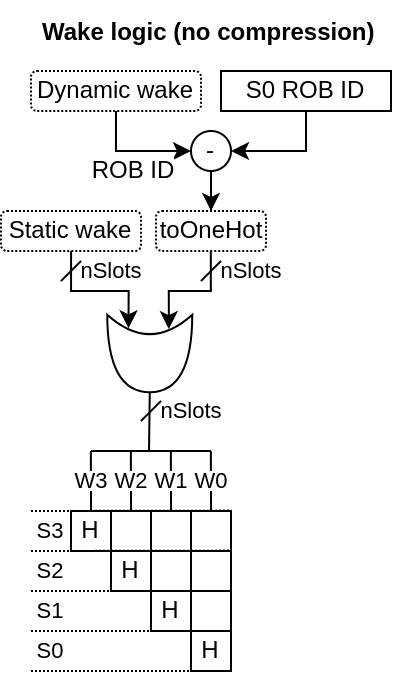
- 圧縮なし : 空行には圧縮が適用されない。プッシュが行われるごとに、ホワイトキューが1行シフトする。これにより、行列FFのより優れた推論と、より小さく高速なROB IDウェイクロジックが可能になる。
- マトリックスベース : どの命令を格納するかは、ハーフマトリックスとして実行される内容によって決まる
- 古い順 : 複数の命令が特定の実行ユニットで同時にディスパッチされる場合、古い命令が選択される
- ROB IDによるウェイクアップ : ダイナミックウェイクアップの場合、ROB IDが識別子として使用される(物理レジスタファイルIDではない)
そのため、全体的には、タイミングを維持するために超えないようにするには、32スロットのキューが限界のようだ。また、現在の設計では、キューの占有面積はCPU全体と比較してそれほど大きな問題ではないようだ。
以下にいくつかの図を示す: