
ちょっといくつか確認しなければならないことがあり、AArch64対応のGem5を試行してサイクル性能を測定している。
以下のようなループを作成して、FMLAのレイテンシがどのようになるのか観測したい。
for (int i = 0; i < N / 4; i++) { float32x4_t va, vb, vc, vd; va = vld1q_f32(p_a); vb = vld1q_f32(p_b); vc = vld1q_f32(p_c); vd = vmlaq_f32(va, vb, vc); vst1q_f32(p_d, vd); p_a += 4; p_b += 4; p_c += 4; p_d += 4; }
../build/ARM/gem5.debug \ --debug-flags=O3PipeView --debug-start=0 --debug-file saxpy_vec.aarch64.out ./configs/example/se.py --cpu-type=DerivO3CPU \ --caches --cmd=/home/msyksphinz/work/gem5/app/neon/main
Gem5のO3情報をトレースしてみると以下のようになった。
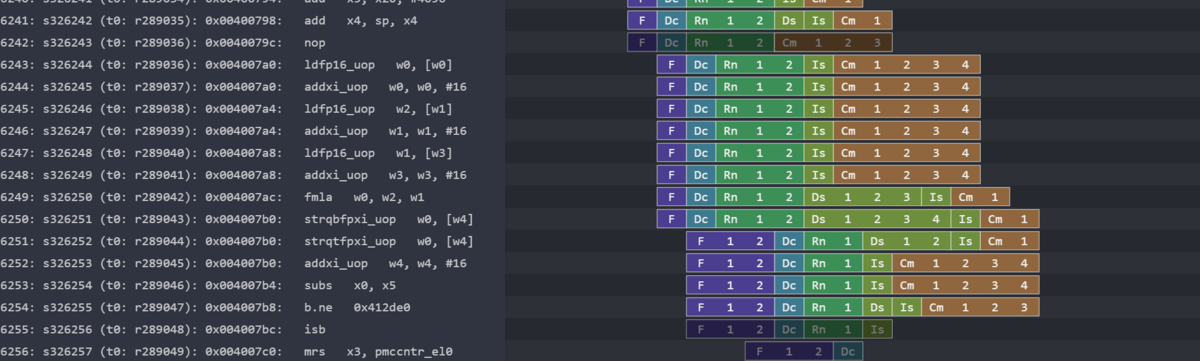
あれ?FMLAの実行が1サイクルで終わるようになっている。これはどういうコンフィグレーションで実行されているのかなあ?いろいろとGem5の中身を確認してみたい。