LLVM16になって、RISC-VのVectorizationの状態について確認していきたい。
Scalable Vectorizationの機能について、テストプログラムを動かしながら動作確認をしていきたい。 以下のような、簡単なプログラムを作ってどのようにコンパイルされるのかを見てみた。
- Scalar版の整数加算関数
void int_add_scalar (int *dest, const int *a, const int *b, size_t count) { for (size_t i = 0; i < count; i++) { dest[i] = a[i] + b[i]; } }
- Vector版の整数加算関数
void int_add_vector (int *dest, const int *a, const int *b, size_t count) { vint32m8_t vx, vy; size_t l = 0; for (; count > 0; count -= l) { l = __riscv_vsetvl_e32m8(count); { vint32m8_t vx, vy; vx = __riscv_vle32_v_i32m8(a, l); vy = __riscv_vle32_v_i32m8(b, l); vy = __riscv_vadd_vv_i32m8(vy, vx, l); __riscv_vse32_v_i32m8 (dest, vy, l); } a += l; b += l; dest += l; } }
-O3オプションのみ:まあ普通にコンパイルされた。-O3でもループアンローリングはされなかった。ループ数が読めないから?
int_add_scalar: # @int_add_scalar # %bb.0: beqz a3, .LBB0_2 .LBB0_1: # =>This Inner Loop Header: Depth=1 lw a4, 0(a1) lw a5, 0(a2) add a4, a4, a5 sw a4, 0(a0) addi a3, a3, -1 addi a0, a0, 4 addi a2, a2, 4 addi a1, a1, 4 bnez a3, .LBB0_1 .LBB0_2: ret
- ベクトル版のコンパイル結果:こちらはIntrinsicでガチガチに組み上げているので、そのままのコードが出てくる。
int_add_vector: # @int_add_vector # %bb.0: beqz a3, .LBB1_2 .LBB1_1: # =>This Inner Loop Header: Depth=1 vsetvli a4, a3, e32, m8, ta, mu vle32.v v8, (a1) vle32.v v16, (a2) vadd.vv v8, v16, v8 vse32.v v8, (a0) slli a5, a4, 2 add a1, a1, a5 add a2, a2, a5 sub a3, a3, a4 add a0, a0, a5 bnez a3, .LBB1_1 .LBB1_2: ret
- スカラ版に対してScalable Vectorizationを適用:具体的には
-mllvm --scalable-vectorization=onを適用した。
... .LBB0_9: srli t0, a4, 1 addi a6, t0, -1 and a7, a3, a6 sub a6, a3, a7 vsetvli t1, zero, e32, m1, ta, ma mv t1, a6 mv t2, a0 mv t3, a2 mv t4, a1 .LBB0_10: # =>This Inner Loop Header: Depth=1 vl1re32.v v8, (t4) add t5, t4, a4 vl1re32.v v9, (t5) vl1re32.v v10, (t3) add t5, t3, a4 vl1re32.v v11, (t5) vadd.vv v8, v10, v8 vadd.vv v9, v11, v9 vs1r.v v8, (t2) add t5, t2, a4 vs1r.v v9, (t5) add t4, t4, a5 ...
ただ、以下の記事を見るともっと賢くベクトル化できそうではあるのだが...
追記:いろいろ試すと、LLVM15だと記事通りになるようだ。
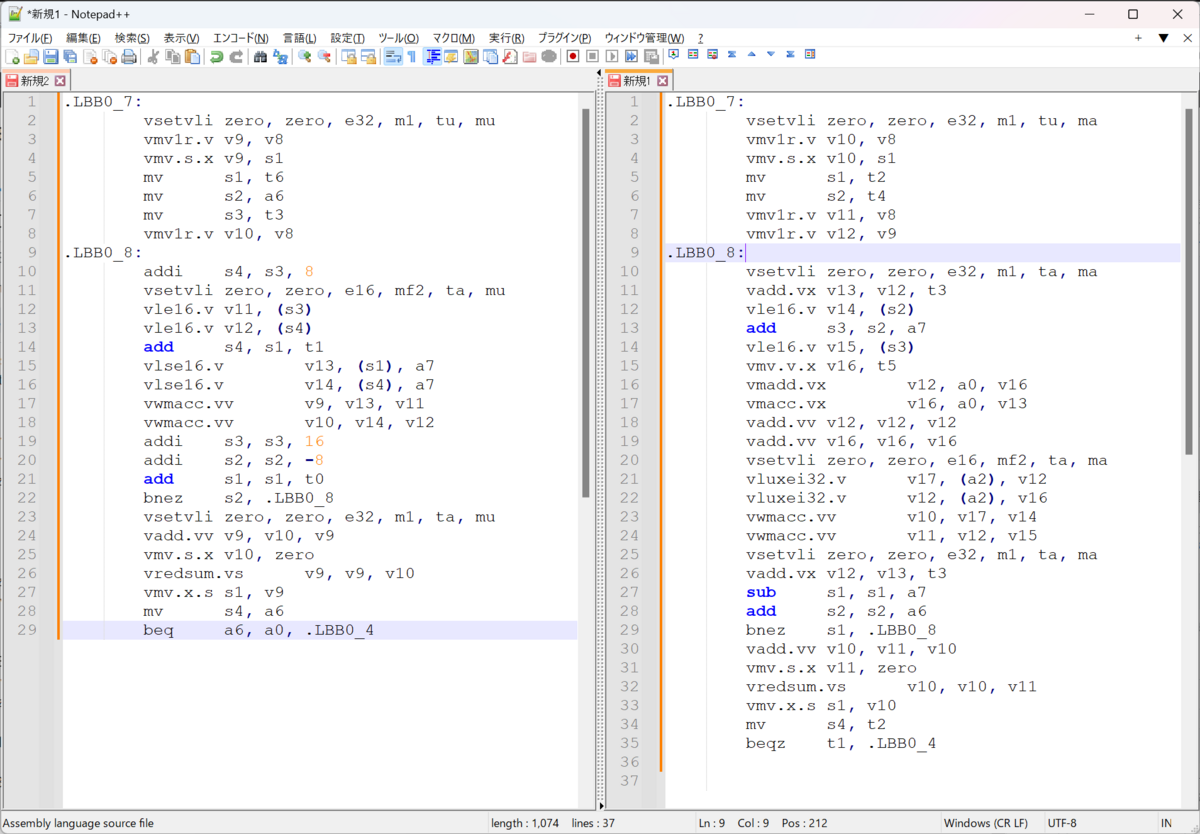
.LBB0_7: vsetvli zero, zero, e32, m1, tu, mu vmv1r.v v9, v8 vmv.s.x v9, s1 mv s1, t6 mv s2, a6 mv s3, t3 vmv1r.v v10, v8 .LBB0_8: addi s4, s3, 8 vsetvli zero, zero, e16, mf2, ta, mu vle16.v v11, (s3) vle16.v v12, (s4) add s4, s1, t1 vlse16.v v13, (s1), a7 vlse16.v v14, (s4), a7 vwmacc.vv v9, v13, v11 vwmacc.vv v10, v14, v12 addi s3, s3, 16 addi s2, s2, -8 add s1, s1, t0 bnez s2, .LBB0_8 vsetvli zero, zero, e32, m1, ta, mu vadd.vv v9, v10, v9 vmv.s.x v10, zero vredsum.vs v9, v9, v10 vmv.x.s s1, v9 mv s4, a6 beq a6, a0, .LBB0_4
LLVM16だと、VLUXEIが使われる。どちらがコストが大きいかというと微妙なところだが...
.LBB0_7: vsetvli zero, zero, e32, m1, tu, ma vmv1r.v v10, v8 vmv.s.x v10, s1 mv s1, t2 mv s2, t4 vmv1r.v v11, v8 vmv1r.v v12, v9 .LBB0_8: vsetvli zero, zero, e32, m1, ta, ma vadd.vx v13, v12, t3 vle16.v v14, (s2) add s3, s2, a7 vle16.v v15, (s3) vmv.v.x v16, t5 vmadd.vx v12, a0, v16 vmacc.vx v16, a0, v13 vadd.vv v12, v12, v12 vadd.vv v16, v16, v16 vsetvli zero, zero, e16, mf2, ta, ma vluxei32.v v17, (a2), v12 vluxei32.v v12, (a2), v16 vwmacc.vv v10, v17, v14 vwmacc.vv v11, v12, v15 vsetvli zero, zero, e32, m1, ta, ma vadd.vx v12, v13, t3 sub s1, s1, a7 add s2, s2, a6 bnez s1, .LBB0_8 vadd.vv v10, v11, v10 vmv.s.x v11, zero vredsum.vs v10, v10, v11 vmv.x.s s1, v10 mv s4, t2 beqz t1, .LBB0_4
比較するとこんな感じ。左がLLVM15, 右がLLVM16。LLVM15の方がコード量が少ないように見えるのだが...