Rocket-Chipにハイパーバイザ拡張実装するにあたり参考にされている論文があるので読んでみることにした。 2回目は、検証と評価についてのパート。
前回の記事はこちら。
A First Look at RISC-V Virtualization from an Embedded Systems Perspective
5.1 機能検証
ハードウェア機能検証については、VerilatorとZynq UltraScale+ MPSoC ZCU104 FPGAを使って行った。
ベアメタル・アプリケーションを実行するためのテストフレームワークを開発した。個々の機能ユニットをテストできるような環境を開発し、以下のような機能を持たせた。
- 各テストユニットの開始時にプロセッサの状態を完全にリセットする
- 特権モードを流動的かつ透過的に変更する
- 第1段階と第2段階の権限の組み合わせでゲストの仮想アドレスに簡単にアクセスする
- 例外を簡単に検出および回復し、その状態と原因を後で確認する
オープンソースのハイパーバイザとしてBaoとXVisorを使用し、その実行に成功した。XVisorにはMMUのテストスイートが用意されているが、このテストは完全にクリアされている。
5.2 ハードウェアオーバヘッド
ハードウェアオーバヘッドを測定するために、Hartの数を2、4、6として論理合成を行い面積を評価した。評価にはXilinx Vivado 2018.3を使用した。
ハイパーバイザの実装結果、ハードウェアのオーバヘッドはCSRとTLBモジュールが主たる要因であることが分かった。CSRはH拡張によるCSRレジスタの増加によるの、TLBは2段階変換によるデータストアの拡張と、特権レベルとパーミッションのチェック機能の実装によるものであった。
それ以外にもCLINTとPLICも面積が増加しているが、全体の面積に比べてこれは大きな影響を与えるものではない。
5.3 パフォーマンスとVM間干渉
性能面でのオーバヘッドを測定するためにMiBenchを使用して性能評価を行った。
それぞれのシステムにおいて以下の構成でベンチマークを実行した。
- ゲストによるネイティブ実行 (bare)
- ホストによる実行 (solo)
- VM 用のキャッシュカラーリングによるホスト実行 (solo-col)
- VM およびハイパーバイザ用のキャッシュカラーリングによるホスト実行 (solo-hypcol)
- コロケーションされた複数の VM からの干渉下でのホストされた実行(interf)
- VM 用のキャッシュ・カラーリングによる干渉下でのホストされた実行(interf-col)
- VM およびハイパーバイザ用のキャッシュ・カラーリングによる干渉下でのホストされた実行(interf-hypcol)。
実験はAWS EC2上で動作するFireSimを用いて実行した。その結果を図3に示す。
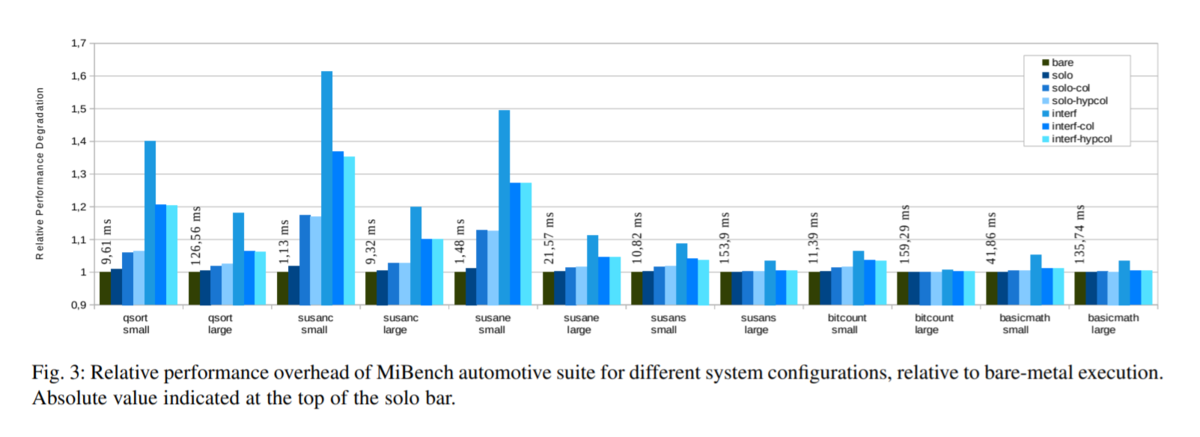
図3から得られる結論は以下の6つである。
- ホスト実行(solo)では,2 段階のアドレス変換による仮想化オーバヘッドのために,性能がわずかに低下する(平均 1% のオーバヘッド増加)
- カラーリング(solo-colおよびsolo-hypcol)を有効にすると、パフォーマンスのオーバーヘッドがさらに増加する
- この余分なオーバーヘッドは、L2 キャッシュの約半分しかターゲット VM で使用できないことと、カラーリングによってスーパーページが使用できなくなり,TLB の圧力が大幅に増加することが原因である。
- システムが大きな干渉を受けている場合、特にメモリを大量に消費するベンチマーク(qsort(小),susan corners(小),susan edges(小))では、性能が大幅に低下する。
- キャッシュのカラーリングによって、干渉(col間およびhypcol間)がほぼ50%削減され、ハイパーバイザーもカラーリングされている場合はわずかに有利になることが分かる。
- キャッシュのカラーリングは、それ自体が干渉に対する特効薬ではない。
- なぜなら,干渉を受けているカラーリングされた構成(inter-col および inter-hypcol)のパフォーマンスオーバーヘッドは,干渉を受けていない構成(solo-col および solo-hypcol)とは異なるからである。
- メモリ使用量の少ないベンチマーク(basicmath や bitcount など)はキャッシュ干渉の影響を受けにくく,小さいデータセットを扱うベンチマークは干渉の影響を受けやすい
5.4 割り込みレイテンシ
割り込みの待ち時間と干渉を測定するために、タイマーとPLICを使用して割り込みを発生させて測定を行った。
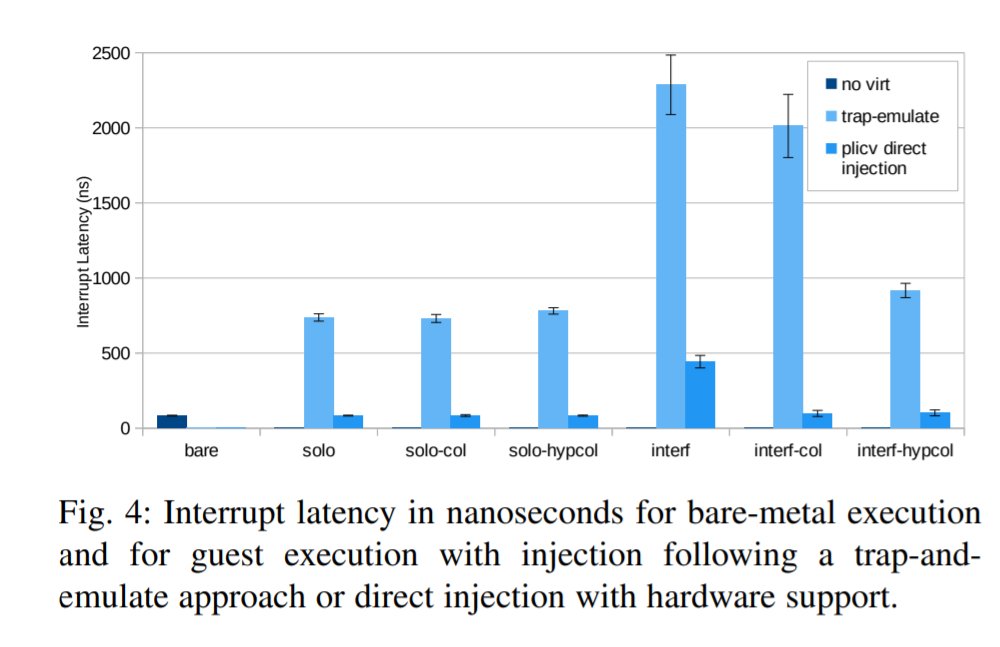
デフォルトの状態では割り込みの遅延は小さく安定している。トラップ&エミュレート方式では干渉時には大きな遅延となっており、ペナルティが発生する。
キャッシュをカラーリングにより分割することでこの影響は小さくなり、干渉のほとんどが共有L2 LLCで発生していることが分かる。
ゲスト外部割込みとPLIC仮想化サポートによるダイレクトインジェクションにより、割り込みレイテンシをネイティブ状態に殆ど近づけることができる。PLICの仮想化サポートにより、VMの外部割り込みレイテンシを大幅に改善することが可能である。
8. 結論
本論文では、RISC-VのH拡張をRocketコアに実装した。割り込みコントローラとタイマコントローラの一連のハードウェア拡張を提案し、レイテンシの削減のためにシステム要件に取り込むことを目的としている。
また、ハードウェア実装を評価するためにオープンソースのハイパーバイザーBaoをRISC-Vに移植して動作させた。また、VerilatorとZynq UltraScale+ MPSoC ZCU104 FPGAを用いて実装の機能検証と性能評価を行った。