RISC-VのアウトオブオーダコアであるBOOM (Berkely Out-of-Order Machine) について勉強を進めている。以下のドキュメントを日本語に訳しながら読んでいくことにした。
ロードストアユニット(LSU)
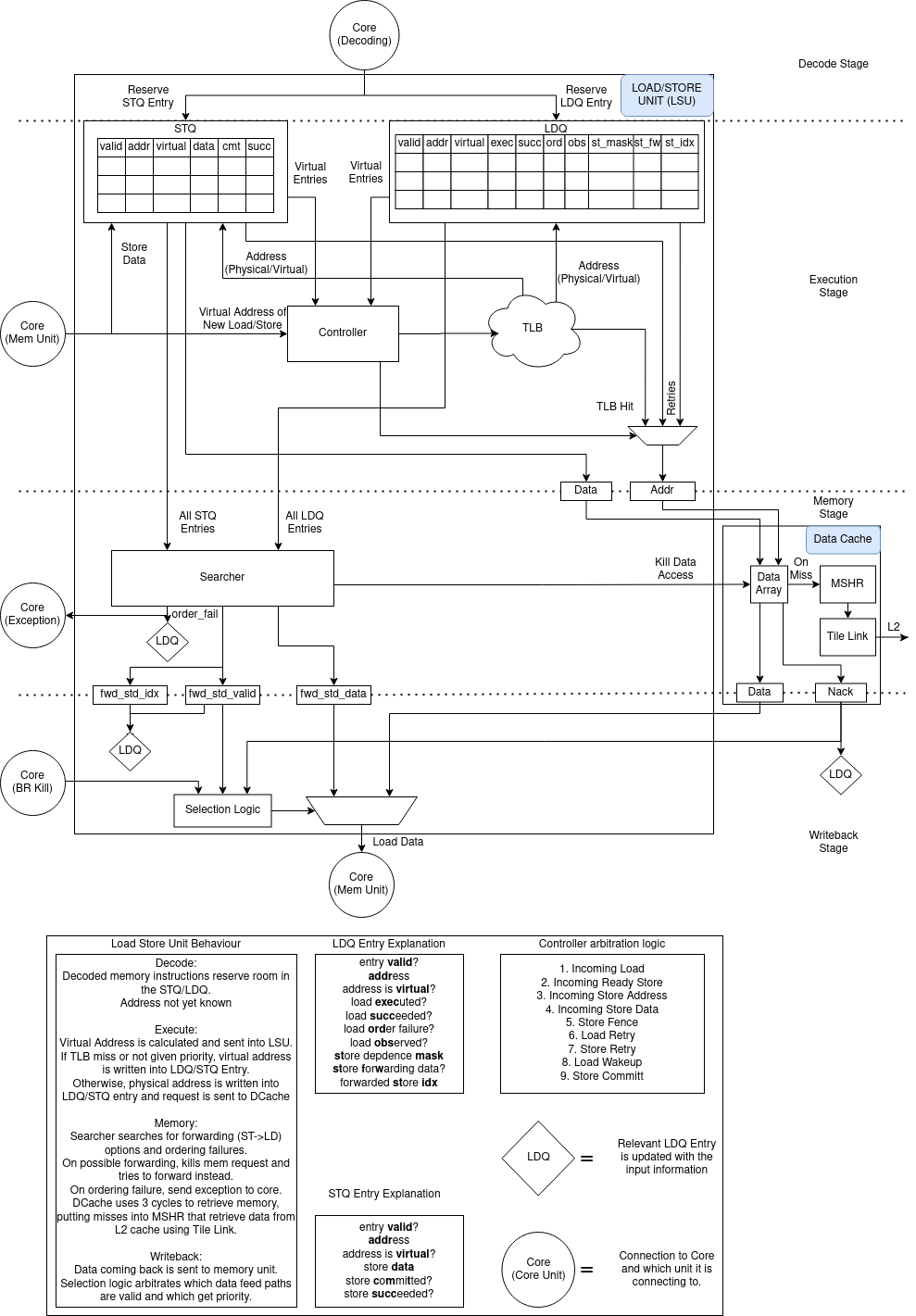
Fig. 24 ロードストアユニット
LSU(Load/Store Unit) は、メモリシステムへのメモリ操作の発火タイミングを決定する役割を担っています。 ロードキュー(LDQ) と ストアキュー(STQ) の2つのキューがあります。 ロード命令は、”uopLD” Micro-Op (UOP) を生成します。 uopLD は発行されるとロードアドレスを計算し、その結果をLDQに格納します。 ストア命令では、”uopSTA”(ストアアドレス生成)と”uopSTD”(ストアデータ生成)の 2つの UOPを生成します。 STA UOPは、ストアアドレスを計算し、STQエントリのアドレスを更新します。 STD UOPは、ストアデータをSTQエントリに移動させます。 これらの各 UOPは、オペランドの準備が整い次第、 命令発行ウィンドウ から発行されます。 ストアの UOPの仕様の詳細については、 Store Micro-Ops を参照してください。
ストア命令
ストアキューのエントリは、デコード時に確保されます(stq(i).validがセットされます)。 Validビットは、STQ内のエントリが有効なアドレスと有効なデータを保持していることを示します(stq(i).bits.addr.validおよびstq(i).bits.data.valid)。 ストア命令がコミットされると、ストアキューの対応するエントリがコミットされたとマークされます。 その後、ストアは自由にメモリシステムに送信されます。 ストアはプログラム順にメモリに投入されます。
ストア Micro-Ops
ストアは命令発行ウィンドウに1つの命令として挿入されます(別々のaddr-genおよびdata-gen UOP としてLSUに発行することができます。 これにより、ストア命令は2つのレジスタファイルリードポートにアクセスする必要がありますが、これはストアを多用するコードでパフォーマンスを半減させたくないという思いからです。 スタックへのストアを含むシーケンスは、IPC=1で動作しなければなりません。
しかし、ストア・アドレスはストア・データのかなり前から知っているのが普通です。 ストアアドレスはできるだけ早くSTQに移動させ、後でロードできるようにして、メモリ順序の失敗を回避する必要があります。 このように、命令発行ウィンドウは必要に応じてuopSTAまたはuopSTD UOPを発するが、 第2オペランドの準備が整うまでストアの残り半分を保持する。
ロード命令
ロードキュー(LDQ)のエントリは、 デコード の段階で割り当てられます (ldq(i).valid)。 デコード ステージ中に、書くロードエントリは ストアマスク (ldq(i).bits.st\_dep\_mask) が割り当てられます。 これはストアキュー内のどのストアに依存しているかを示すものです。 ストアがメモリに実行されてストアキューから離れると、 ストアマスク の適切なビットがクリアされます。
ロードアドレスが計算されてLDQに配置されると、対応するvalidビットが設定されます(ldq(i).addr.valid)。
ロードは、LSUに到着した時点で、最適な方法でメモリに実行されます(ロードが早期にファイアーされることは、アウトオブオーダー・パイプラインの大きなメリットです)。 同時に、ロード命令は自分のアドレスと、依存するすべてのストアアドレスを比較します。 一致した場合、そのメモリ要求はキャンセルされます。 対応するストアデータが存在すれば、そのストアデータはロードに 転送 され、ロードは 成功 したと判断します。 ストアデータが存在しない場合は、ロードは スリープ に入ります。スリープ状態になったロードは、後から再試行されます。1
BOOMのメモリモデル
BOOMはRVWMOメモリコンシステンシモデルに従います。
現在BOOMは以下のような動作をしています。
- 書き込み→読み込みの制約が緩和された(新しいロードが古いストアより先に実行されることがある 新しいロードが古いストアより先に実行される可能性があります)。
- 読み出し→読み出しの制約は維持されます(同じアドレスへのロードは 順番に現れる)。
- スレッドは自分の書き込みを早く読むことができます。
同一アドレスに対するロードの順序
RISC-VのWMOメモリモデルでは、同じアドレスへのロードは順番に行う必要があります。2 これにより、ロードはアドレス衝突の可能性がないか、他のロードに対して検索する必要があります。 アドレスが一致する古いロードの前に若いロードが実行された場合、若いロードは再生され、パイプライン内の後続の命令はフラッシュされなければなりません。 しかし、このシナリオが必要になるのは、キャッシュコヒーレンスのプローブイベントがコアのメモリをスヌープして、 他のスレッドに並び替えを暴露した場合だけです。 プローブイベントが発生しなければ、ロードリオーダリングは安全に行われるでしょう。
メモリのオーダリングの失敗
ロード/ストアユニットでは、ストア→ロードの依存関係に注意しなければなりません。 最高のパフォーマンスを得るためには、ロードをできるだけ早くメモリに投入する必要があります。
sw x1 -> 0(x2) ld x3 <- 0(x4)
しかし、x2とx4が同じメモリアドレスを参照している場合、この例のロードは、先に発行されたストアに 依存 しています。 ストアが発行される前にロードがメモリに発行された場合、ロードはメモリから間違った値を読み出すことになり、 メモリ順序付けの失敗 が発生します。 順番に失敗した場合、パイプラインをフラッシュし、リネームマップテーブルをリセットしなければなりません。これは非常に高価な処理です。
順番付けの失敗を発見するために、ストアがコミットするときに、LDQ全体でアドレスの一致をチェックします。 一致した場合、ストアはロードが実行されたかどうか、またデータがメモリから取得されたものか、古いストアから転送されたものかを確認します。 いずれの場合も、メモリオーダーの失敗が発生しています。
ロード/ストアユニットの詳細については、 Fig. 24 を参照してください。
1 : より高性能なプロセッサでは、ロードがスリープ状態になった原因を追跡し、 ロードをブロックしているされた原因が解消された時点で負荷を起こします。
2 : 技術的には、 fence.r.r を使用して、依存性のあるロードをリオーダするマシン上でのソフトウェアの正しい実行を提供することができます。 しかし、ISAが依存性ロードのリオーダリングを禁止する理由は2つあります。1)他のポピュラーなISAではこのような緩和を認めていないため、 ソフトウェアをRISC-Vに移植する際に、新たな課題が生じる可能性があること、 2)慎重なソフトウェアは、適切な fence 命令を自由に使いすぎて、ソフトウェアの速度低下を招く可能性があること、です。 ありがたいことに、順序付きの依存性ロードを強制することは、実際にはそれほどコストがかからないかもしれません。 まず、ロードアドレスは早い段階で判明しており、どのような場合でもインオーダーで実行される可能性があります。 第二に、順序違いのロードは、キャッシュコヒーレンスプローブのキャッシュ内でのみ問題となるため、パフォーマンス上のペナルティは無視できるでしょう。 ロードは、ストアが既に使用しているLAQのCAM検索ポートと同じものを使用できます。 1サイクルに1つのロードとストアのアドレス計算をサポートする場合には問題となる可能性がありますが、余分なCAMサーチポートはバンキングによって軽減されるか、 より多くのキャッシュバンド幅をサポートするために必要な他のハードウェアコストに比べて小さいものとなります。