- モチベーション
- なぜRustを選んだか?
- 私はQEMUは「アーキテクチャエミュレーション界のLLVM」だと思っている
- QEMUが高速な理由:TCG Binary Translation
- ゲスト命令(RISC-V) → TCG → ホスト命令(x86)の処理をRustで作ろう
- 実装結果
- Binary Translation実行を高速化するための様々なテクニック
- まだ完成していないところ
- Rustで作って良かったか?
- 不安要素:ポインタをゴリゴリに使う低レイヤプログラミングにRustは向きか不向きか
2020年の後半は、趣味ではQEMUの勉強をしていた。QEMUは高速動作を売りとするアーキテクチャエミュレーションツールで、x86のみならずRISC-V、ARM、それ以外の様々なアーキテクチャのエミュレーションをサポートしているツールだ。Linuxのブートや組み込み分野を生業としているエンジニアならば、一度は触ったことがあるはずだ。
QEMUは多くのアーキテクチャをサポートしているにもかかわらず非常に高速動作する。例えば、私の知っている分野だとRISC-Vの命令セットシミュレータとしてSpike(riscv-isa-sim)があるが、QEMUはおよそその10倍以上の速度でRISC-VバイナリをエミュレーションすることができるQEMUでRISC-VのLinuxをブートする場合にも、Spikeを使う場合とは比べ物にならないほどの速度でLinuxをブートすることができるため、組み込み屋さんやエミュレーション屋さんの間ではQEMUを非常に重宝している。
モチベーション
最初は、Linuxのブートシーケンスの勉強のためにQEMUをインストールして、RISC-Vを題材にLinuxがどのようにブートするのかを勉強していた。しかしその最中に、突如としてQEMUに興味が湧いてしまったわけである。一体全体どのようなアルゴリズムを使えばQEMUはSpikeよりも1桁違う速度でエミュレーションを行えるのであろうか。Linuxのブートよりも、そっちの方が気になってしょうがなくなってしまった。
という訳で、QEMUの内部構造を勉強した上で、さらに理解を深めるために別の言語で書き直すという、私お得意の非常に遠回りな手法での勉強をすることにした。
QEMUの本体は殆どC言語で書かれている。これを私の勉強中の言語であるRustで書き直してみることにした。
なぜRustを選んだか?
QEMUのバグは時としてセキュリティ上問題になるものが多く、以下のようなエントリが上がっていたりしてもうちょっとセキュアな言語を使うことは出来ないのか、という議論は以前から行われていたようだ。もちろん、私の作るQEMUのクローンが代替になるとは思ってもいないが、Rustの勉強にもなるし、ちょうど良いだろうということで選択することにした。
http://blog.vmsplice.net/2020/08/why-qemu-should-move-from-c-to-rust.html
私はQEMUは「アーキテクチャエミュレーション界のLLVM」だと思っている
上記の通り、QEMUは様々なアーキテクチャをサポートしており、また同様に様々なアーキテクチャ上で動作させることができる。いろいろ調査した感じでは、QEMUはアーキテクチャエミュレーション界のLLVMだと感じるようになった。つまり、複数のアーキテクチャをサポートして、中間言語を持っているというあたりがLLVMと構造がそっくりなのだ。私はQEMUはLLVMのようにもっと人気が出ても良いと思っているのだが、いかんせんC言語で書いてありModularityの部分にもまだ不安な要素がある。LLVMのように複数のライブラリを小分けして、もう少しSophisticatedになってくれれば格好いいし、自分もそういう所に貢献できればいいなと思っている。
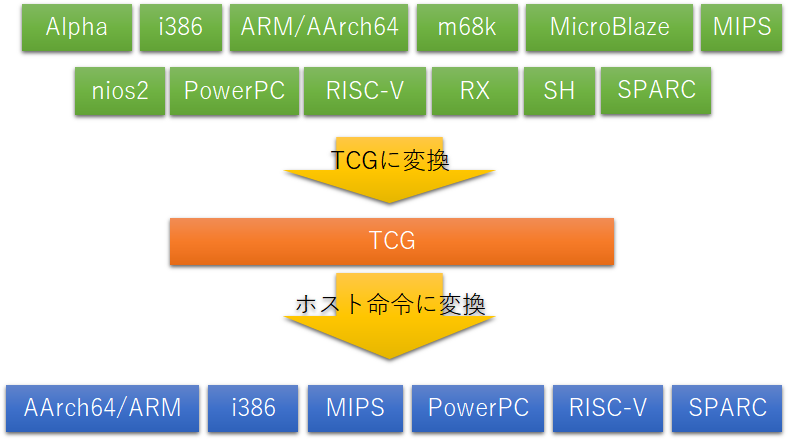
QEMUが高速な理由:TCG Binary Translation
一般的に命令セットシミュレータは、2種類に分けられる:「インタプリタ型」「Binary Translation型」だ。インタプリタ型はその名の通りエミュレーション対象となる命令(これを「ゲスト命令」と呼ぶ)を解釈し、そのエミュレータが使っている言語(例えばspikeの場合はC++)でゲスト命令をエミュレーションする。例えば、私のRISC-VシミュレータではADDI命令をどのようにエミュレーションしているのかというと、
void InstEnv::RISCV_INST_ADDI(InstWord_t inst_hex) { m_pe_thread->Func_R_RI<DWord_t, DWord_t> (inst_hex, [&](DWord_t op1, DWord_t op2, uint32_t round_mode, UWord_t *fflags) { return m_pe_thread->SExtXlen(op1 + op2); }); }
という処理が必要になるわけだ。これだけ書くと簡単だが、C言語でこれを書いてコンパイルすると結構な命令数を消費する。これは高級なプログラミング言語を使用しているならば当然のことだ。そしてインタプリタ型の場合、同じアドレスの同じ命令を繰り返す場合には何度もデコードし直して上記のリストを順番に実行しなければならないわけだ。これは面倒だ。
そこでQEMUは、ゲスト命令をTCG(Tiny Code Generator)という中間表現に変換するという一時的な処理を行う。TCGはホスト命令(エミュレータを実行する環境の命令、多くの場合はx86)に変換し、変換したx86命令は常にバッファに保存しておき、再度同じアドレスの同じ命令を実行するときは再デコードすることなくバッファから当該x86命令を読みだして実行する。これにより以下のメリットが生じる。
という訳でQEMUはインタプリタ型に対して非常に高速な動作を実現することができる。
しかしこれは良いことばかりではない。すべてのゲスト命令をTCGで表現する必要が生じるため、高級プログラミング言語の記法が使えず命令実装が非常におっくうとなる。実際、私が昔にRustで作ったインタプリタ型のRISC-VエミュレータではADDI命令を以下のように実装していた。非常に読みやすく簡単だ。
fn execute_addi (&mut self, inst: InstT) { let rs1 = Self::get_rs1_addr(inst); let rd = Self::get_rd_addr(inst); let rs1_data = self.read_reg(rs1); let imm_data = Self::extract_ifield(inst); let reg_data: Xlen64T = self.sext_xlen(rs1_data.wrapping_add(imm_data)); self.write_reg(rd, reg_data); }
しかしQEMUでは同じADDI命令でもTCGで以下のように記述されている。なんだか良く分からない。
qemu-5.1.0/target/riscv/insn_trans/trans_rvi.inc.c
static bool trans_addi(DisasContext *ctx, arg_addi *a) { return gen_arith_imm_fn(ctx, a, &tcg_gen_addi_tl); }
qemu-5.1.0/target/riscv/translate.c
static bool gen_arith_imm_fn(DisasContext *ctx, arg_i *a, void (*func)(TCGv, TCGv, target_long)) { TCGv source1; source1 = tcg_temp_new(); gen_get_gpr(source1, a->rs1); (*func)(source1, source1, a->imm); gen_set_gpr(a->rd, source1); tcg_temp_free(source1); return true; }
これでTCGが生成される。上記のtcg_temp_new()やtcg_temp_free()はTCGで使用する変数を確保していると考えて良い。これはいわゆる普通の変数ではなく、最終的にx86のレジスタにアサインするためのスタブと考えて良い。上記の例ならばsource1が何らかのx86のレジスタにアサインされてエミュレーションされる。
上記のADDI命令をTCGに変換すると、以下のようになる。何となくイメージが湧いてくるだろう。
0x0000000080004110: 81818793 addi a5,gp,-2024
---- 0000000080004110 mov_i64 tmp2,x3/gp movi_i64 tmp3,$0xfffffffffffff818 add_i64 tmp2,tmp2,tmp3 mov_i64 x15/a5,tmp2
そしてTCGがx86に変換される。以下がその結果だが、何となく意味は想像できるだろう。インタプリタではかなりの命令数を消費してしまうだろうが、これをわずか3命令で実現できてしまうあたりQEMUが高速な秘訣であろう。
// GPレジスタからデータをロードしてRBXに格納する(%rbpはベースアドレス) 0x7f47e803914b: 48 8b 5d 18 movq 0x18(%rbp), %rbx // -2024を加算する 0x7f47e803914f: 48 81 c3 18 f8 ff ff addq $-0x7e8, %rbx // RBXをA5レジスタにストアする(%rbpはベースアドレス) 0x7f47e8039156: 48 89 5d 78 movq %rbx, 0x78(%rbp)

ゲスト命令(RISC-V) → TCG → ホスト命令(x86)の処理をRustで作ろう
さて、TCGとQEMUの仕組みが理解できたところで、これをRustで実装しようと思う。現在の実装は以下のリポジトリで管理している。
QEMUと同じことをするためには、大きく分けて以下のことが必要だ。
RISC-Vの命令をフェッチしてデコードする
まず、RustでELFを読み込んで先頭からRISC-V命令を取り出していく部分を実装した。デコードの部分は以前インタプリタ型のエミュレータを作った時のものをそのままインポートしてきた。デコーダは自動生成するようにしているので、すぐに実装が完了した。
while true { self.loop_idx += 1; #[allow(unused_assignments)] let mut guest_phy_addr = 0; // 命令のフェッチ let guest_inst = self.read_mem_4byte(guest_phy_addr); // 命令のデコード let (id, inst_byte) = match decode_inst(guest_inst) { Some((id, inst_byte)) => (id, inst_byte), _ => panic!("Decode Failed. {:08x}", guest_inst), };
RISC-Vの命令をTCGに変換する
対象となる命令が決まれば、これをTCGに変換する。ADDI命令であれば、3種類のTCGノードに変換される。TCGリストはvec![]で格納される。
pub fn translate_addi(&mut self, inst: &InstrInfo) -> (bool, Vec<TCGOp>) { self.translate_rri(TCGOpcode::ADD_64BIT, inst) }
pub fn translate_rri(&mut self, op: TCGOpcode, inst: &InstrInfo) -> (bool, Vec<TCGOp>) { let rs1_addr= get_rs1_addr!(inst.inst); let rd_addr = get_rd_addr!(inst.inst); let imm_const: u64 = ((inst.inst as i32) >> 20) as u64; let tcg_imm = TCGv::new_imm(imm_const); if rd_addr == 0 { return (false, vec![]); } // TCG変数を確保する。これはx86に変換する際に特定のレジスタにアサインする let source1 = self.tcg_temp_new(); // GPRからデータをロードする let rs1_op = TCGOp::tcg_get_gpr(source1, rs1_addr); // TCGOpcode::ADDI_64BIT TCGを生成する。 let tcg_inst = TCGOp::new_3op(op, source1, source1, tcg_imm); // GPRにデータをストアする let rd_op = TCGOp::tcg_set_gpr(rd_addr, source1); self.tcg_temp_free(source1); // 3つのTCGをリストにして返す (false, vec![rs1_op, tcg_inst, rd_op]) }
TCGをx86に変換する
上記の3つのTCGをx86命令に変換するためのコードを記述する。それぞれTCGのOpcodeは、
TCGOpcode::GET_GPRTCGOpcode::ADD_64BITTCGOpcode::SET_GPR
なので、それぞれのTCGオペコードに応じてx86命令を生成する。
fn tcg_gen(emu: &EmuEnv, guest_init_pc: u64, host_pc_address: u64, tcg: &TCGOp, mc: &mut Vec<u8>) -> usize { match tcg.op { Some(op) => { return match op { TCGOpcode::GET_GPR => TCGX86::tcg_gen_get_gpr(emu, host_pc_address, tcg, mc), TCGOpcode::SET_GPR => TCGX86::tcg_gen_set_gpr(emu, host_pc_address, tcg, mc), ...
TCGOpcode::GET_GPRは以下のようなコードによりx86に変換される。
fn tcg_gen_get_gpr(emu: &EmuEnv, host_pc_address: u64, tcg: &tcg::TCGOp, mc: &mut Vec<u8>) -> usize { let dest_tmp = tcg.arg0.unwrap(); let src_reg = tcg.arg1.unwrap(); assert_eq!(dest_tmp.t, TCGvType::TCGTemp); assert_eq!(src_reg.t, TCGvType::Register); // 先ほど生成したTCG変数をx86のレジスタに変換する let target_x86reg = Self::convert_x86_reg(dest_tmp.value); let mut gen_size = host_pc_address as usize; let gpr_relat_address = emu.calc_gpr_relat_address(src_reg.value) as u64; // MOV命令を生成する // calc_gpr_relat_address()により、レジスタが配置されているメモリアドレスとEmuEnvの先頭からの差分を計算している if gpr_relat_address < 128 { gen_size += Self::tcg_modrm_64bit_out(X86Opcode::MOV_GV_EV, X86ModRM::MOD_01_DISP_RBP, target_x86reg, mc); gen_size += Self::tcg_out(gpr_relat_address, 1, mc); } else { gen_size += Self::tcg_modrm_64bit_out(X86Opcode::MOV_GV_EV, X86ModRM::MOD_10_DISP_RBP, target_x86reg, mc); gen_size += Self::tcg_out(gpr_relat_address, 4, mc); } return gen_size; }
TCGOpcode::ADDI_64BITは以下のようなコードにx86に変換される。
fn tcg_gen_add_64bit(_emu: &EmuEnv, host_pc_address: u64, tcg: &tcg::TCGOp, mc: &mut Vec<u8>) -> usize { if tcg.arg2.unwrap().t == TCGvType::Immediate { // 第2引数が即値の場合はtcg_gen_op_temp_imm()を呼び出す Self::tcg_gen_op_temp_imm(host_pc_address, X86Opcode::ADD_GV_IMM, tcg, mc) } else { // 第2引数がレジスタの場合はtcg_gen_op_temp()を呼び出す Self::tcg_gen_op_temp(host_pc_address, X86Opcode::ADD_GV_EV, tcg, mc) } } ... // tcg_gen_op_temp_immの本体 fn tcg_gen_op_temp_imm(host_pc_address: u64, op: X86Opcode, tcg: &tcg::TCGOp, mc: &mut Vec<u8>) -> usize { let dest_reg = tcg.arg0.unwrap(); let source1_reg = tcg.arg1.unwrap(); let source2_imm = tcg.arg2.unwrap(); assert_eq!(dest_reg.t, TCGvType::TCGTemp); assert_eq!(source1_reg.t, TCGvType::TCGTemp); assert_eq!(source2_imm.t, TCGvType::Immediate); let mut gen_size: usize = host_pc_address as usize; let target_x86reg = Self::convert_x86_reg(dest_reg.value); let source1_x86reg = Self::convert_x86_reg(source1_reg.value); if source2_imm.value >> 32 != 0 && op == X86Opcode::ADD_GV_IMM{ gen_size += Self::tcg_modrm_64bit_raw_out(X86Opcode::MOV_GV_EV, X86ModRM::MOD_11_DISP_RAX as u8 + source1_x86reg as u8, X86TargetRM::RAX as u8, mc); gen_size += Self::tcg_64bit_out(X86Opcode::ADD_EAX_IV, mc); gen_size += Self::tcg_out(source2_imm.value, 4, mc); gen_size += Self::tcg_modrm_64bit_raw_out(X86Opcode::MOV_GV_EV, X86ModRM::MOD_11_DISP_RAX as u8, source1_x86reg as u8, mc); } else { if dest_reg.value != source1_reg.value { gen_size += Self::tcg_modrm_64bit_raw_out(X86Opcode::MOV_GV_EV, X86ModRM::MOD_11_DISP_RAX as u8 + source1_x86reg as u8, target_x86reg as u8, mc); } gen_size += Self::tcg_modrm_64bit_raw_out(op, X86ModRM::MOD_11_DISP_RAX as u8 + target_x86reg as u8, 0, mc); gen_size += Self::tcg_out(source2_imm.value, 4, mc); } gen_size }
TCGOpcode::SET_GPRは以下のようなコードによりx86に変換される。
fn tcg_gen_set_gpr(emu: &EmuEnv, host_pc_address: u64, tcg: &tcg::TCGOp, mc: &mut Vec<u8>) -> usize { let dest_reg = tcg.arg0.unwrap(); let src_reg = tcg.arg1.unwrap(); assert_eq!(dest_reg.t, TCGvType::Register); assert_eq!(src_reg.t, TCGvType::TCGTemp); // 先ほど生成したTCG変数をx86のレジスタに変換する let source_x86reg = Self::convert_x86_reg(src_reg.value); let mut gen_size = host_pc_address as usize; let gpr_relat_diff = emu.calc_gpr_relat_address(dest_reg.value) as u64; // MOV命令を生成する // calc_gpr_relat_address()により、レジスタが配置されているメモリアドレスとEmuEnvの先頭からの差分を計算している if gpr_relat_diff < 128 { gen_size += Self::tcg_modrm_64bit_out(X86Opcode::MOV_EV_GV, X86ModRM::MOD_01_DISP_RBP, source_x86reg, mc); gen_size += Self::tcg_out(gpr_relat_diff, 1, mc); } else { gen_size += Self::tcg_modrm_64bit_out(X86Opcode::MOV_EV_GV, X86ModRM::MOD_10_DISP_RBP, source_x86reg, mc); gen_size += Self::tcg_out(gpr_relat_diff, 4, mc); } return gen_size; }
実装結果
一生懸命Rustで実装して、riscv-testsとDhrystoneが動作するところまで安定してきた。さっそくQEMUとの速度調査を行ってみる。以下はDhrystoneを実行した場合の速度比較。書き忘れたが単位は秒である。
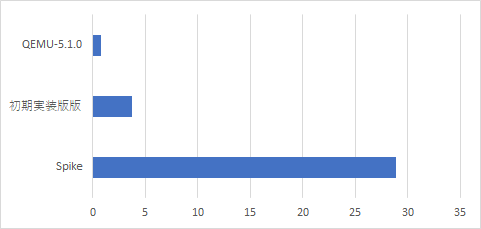
Spikeには完勝することができた。しかしQEMUには完敗している。ここから先はQEMUが採用しているいくつかの最適化のテクニックを紹介しながら、速度向上を図っていく。
Binary Translation実行を高速化するための様々なテクニック
上記のグラフで分かるように、ゲスト命令を単純にTCG→x86命令に変換するという方式をとってもQEMUほど速くはならない。ここではさらにBinary Translation実行を高速化するための技法を調査した。
BasicBlock分まで複数命令をまとめて変換
これは割とすぐに思いつくテクニックで、問題ない範囲で複数個のゲスト命令をホスト命令に変換して同じブロック内に入れておく。こうすることで1命令実行しては次の命令デコード→実行というフローが省略され、高速化を図ることができる。
しかしこれにはいくつか条件がある。単純な加減算命令ならば問題ははいだろうが、例えばジャンプ命令や条件分岐命令はどのように考えればよいのか。次にどこのブロックに飛べばよいのか、Binary Translationの段階では判別できないためホスト命令のジャンプ命令をどこにジャンプさせればよいのか判別できない。そこでジャンプ命令に到達するとそこでいったんBinary Translationを止め、以下のようなTCG(と最終的なホスト命令)を生成する。
デコード側は、ホスト命令が生成した最後のジャンプ先のPCアドレスを参照し、次にどの場所からデコード開始すればよいのかを検索し新たにTCGの作成を開始する(あるいはすでに一度実行したことがありゲスト命令列が生成できていた場合、その命令から実行を再開する)。
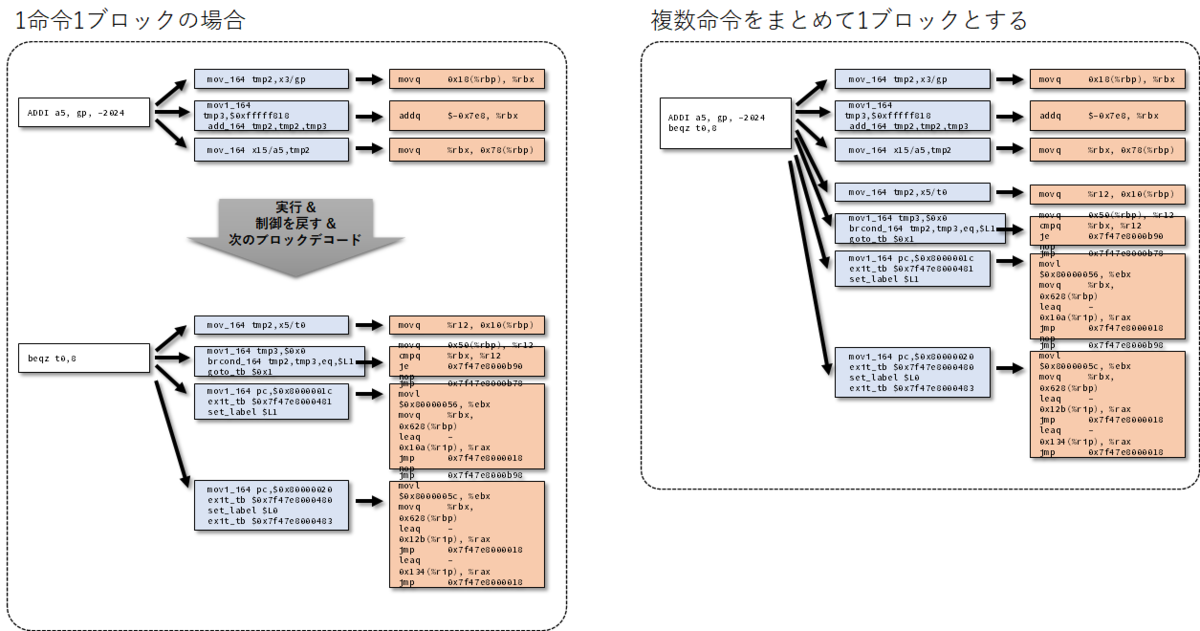
TCG Block Chainingの実装
たとえBasicBlockをまとめて一括して命令変換をしたとしても、まだそこまで高速化できない。次にボトルネックになるのはBasicBlockから戻ってきて次のBasicBlockにジャンプするのに必要な処理だ。上記のままだと分岐命令でいったん制御をゲスト命令実行から戻してしまうため、そこから再び
- 次のPCに対するゲスト命令列テーブルサーチ
- ゲスト命令を再実行
というのが面倒なのだ。特に以下のような条件において、もしすでにゲスト命令への変換が完了しているのならばわざわざテーブルサーチを行わずにすぐに次のブロックに飛びたい。特に以下のようなケースだ。
/* 前の処理 */ BEQ x10, x11, next_label /* 次の処理1 */ next_label: /* 次の処理2 */
この時「/* 前の処理 */」からBEQまででいったんBasicBlockが区切られる。次にジャンプするのは2つのケースがあり、1つが/* 次の処理1 */に飛ぶこと。そしてもう一つはnext_labelに飛ぶことだ。この処理はTCG Block Chainingを実装しない場合には以下のようにして実現される。
- BEQ命令がゲスト命令に変換される
- x10とx11を比較する命令を生成し、その結果に応じて設定する値を変える
- 条件成立の場合、次のPCを示す領域に
next_labelのアドレスを格納する - 条件不成立の場合、次のPCを示す領域に
BEQ+4のアドレスを格納する
- ホスト命令実行から制御を戻す
- PCの情報に基づいて次の命令のデコード・実行を開始する
このように一度ホスト命令実行から制御を戻すため、効率が悪い。しかし考えてみれば、次のブロック(/* 次の処理1 */とnext_label)がすでにゲスト命令に変換されているのであれば、そこに直接ジャンプしてしまえばよい。これがTCG Block Chainingという技法になる。
ただしこの技法はBEQのようにコンパイル時点でジャンプ先が判明している場合にのみ使用できる。レジスタ値ジャンプのようにコンパイル時にジャンプ先が分からないような場合には後述のTB Lookup and Jumpという技法を使うことになる。
TCG Block Chainingの基本的なフローは以下のようになる。
条件分岐命令のホスト命令生成時に「TCG Block Chainingによるジャンプ」を行うためのスタブを挿入する。
ホストに制御が戻り次のゲスト命令をホスト命令に変換する。
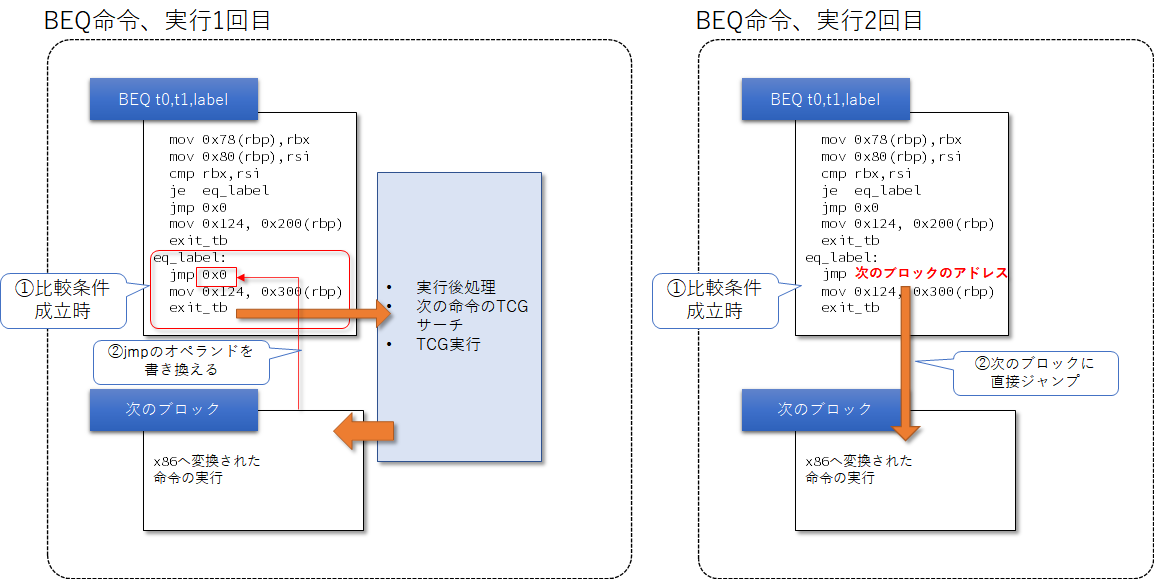
これを実装すると以下のようになった。まず、条件分岐命令をTCGに変換する際に、JMPのスタブを挿入する。
gen_size += Self::tcg_out(X86Opcode::JMP_JZ as u64, 1, mc); gen_size += Self::tcg_out(0x00, 4, mc);
そして、次のブロックをデコードしゲスト命令を生成し終えた後で、スタブの部分に次なるゲスト命令の格納されているアドレスを挿入する。
match self.last_text_mem { Some(mem) => { let text_diff = (tb_text_mem.borrow().data() as u64).wrapping_sub(mem as u64).wrapping_sub(self.last_host_update_address as u64).wrapping_sub(4); // 一つ前に実行したブロックのスタブに対して次のブロックの物理アドレスを挿入して置き換える。 unsafe { *mem.offset(self.last_host_update_address as isize + 0) = ((text_diff >> 0) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 1) = ((text_diff >> 8) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 2) = ((text_diff >> 16) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 3) = ((text_diff >> 24) & 0x0ff) as u8; } }, None => {}, }
これにより例えば以下のBEQ命令は最初にスタブ付きのx86命令に変換されるはずだ。
0000000080000018:0000000080000018 Hostcode 00028463 : beqz t0, pc + 8
00007F8F9E8C0078 48895530 mov %rdx,0x30(%rbp) 00007F8F9E8C007C 488B5530 mov 0x30(%rbp),%rdx 00007F8F9E8C0080 488B5D08 mov 8(%rbp),%rbx // BEQの比較操作を実行 00007F8F9E8C0084 483BD3 cmp %rbx,%rdx // 分岐成立ならば0x0000_7F8F_9E8C_00CBに飛ぶ 00007F8F9E8C0087 0F843E000000 je 0x0000_7F8F_9E8C_00CB 00007F8F9E8C008D 48B81C00008000000000 movabs $0x8000_001C,%rax 00007F8F9E8C0097 48898508020000 mov %rax,0x208(%rbp) 00007F8F9E8C009E 48B80000008000000000 movabs $0x8000_0000,%rax 00007F8F9E8C00A8 48898510020000 mov %rax,0x210(%rbp) 00007F8F9E8C00AF 48B8E902000000000000 movabs $0x2E9,%rax // 条件不成立時のスタブ // 現在オペランドは0x00だが次のブロックの物理アドレスが決定次第置き換えられる 00007F8F9E8C00B9 E900000000 jmp 0x0000_7F8F_9E8C_00BE // もしスタブが本物の物理アドレスに置き換わればここから先は実行されない 00007F8F9E8C00BE 48B90F00829E8F7F0000 movabs $0x7F8F_9E82_000F,%rcx 00007F8F9E8C00C8 48FFE1 jmp *%rcx 00007F8F9E8C00CB 48B82000008000000000 movabs $0x8000_0020,%rax 00007F8F9E8C00D5 48898508020000 mov %rax,0x208(%rbp) 00007F8F9E8C00DC 48B80000008000000000 movabs $0x8000_0000,%rax 00007F8F9E8C00E6 48898510020000 mov %rax,0x210(%rbp) 00007F8F9E8C00ED 48B8E103000000000000 movabs $0x3E1,%rax // 条件成立時のスタブ // 現在オペランドは0x00だが次のブロックの物理アドレスが決定次第置き換えられる 00007F8F9E8C00F7 E900000000 jmp 0x0000_7F8F_9E8C_00FC // もしスタブが本物の物理アドレスに置き換わればここから先は実行されない 00007F8F9E8C00FC 48B90F00829E8F7F0000 movabs $0x7F8F_9E82_000F,%rcx 00007F8F9E8C0106 48FFE1 jmp *%rcx
評価結果
TCG Block Chainingを実装して速度向上率を観測した。同じようにDhrystoneを使って実行速度を計測した。
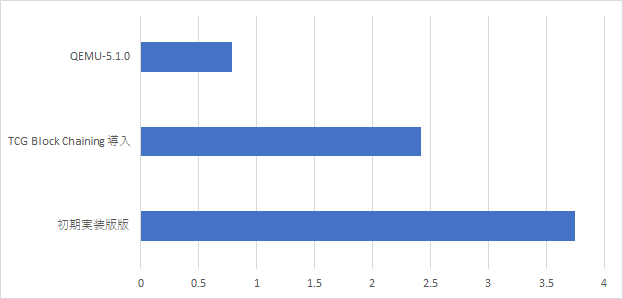
初期実装版に比べてかなり速くなったと思う。しかしまだまだQEMUにはかなわない。さらにボトルネックを解消するために次のTB Lookup and Jumpの実装に進もう。
TB Lookup and Jumpの実装
さて、上記のTCG Block Chainingだけではまだ足りない部分がある。Block Chainingは「ジャンプ先アドレスが常に固定」の場合には問題なく動作するが、そうでないときは使用できない。たとえば、レジスタジャンプなどコンパイル時ではなく実行時でないとジャンプ先が分からない場合、Block Chainingは適用できない。
しかしQEMUでは、Block Chainingが適用できなかったとしても、TB Lookup and Jump(これは私が作った造語で、実際にどのような技法なのかはわからない。おそらく名前のない技法なのだろう)を使って制御を戻さずに直接ジャンプすることができる。これは名前の通りゲスト命令ブロックのアドレスとホスト命令ブロックのアドレスを表にして管理しておき、レジスタジャンプの際にそのレジスタ値をキーとしてそのブロックすでにホスト名れに変換されているかどうかを検索する。もしヒットすればそのホスト命令の格納されているアドレスに直接ジャンプすれば良いし、そうでない場合には制御を戻してデコードから再スタートする。実際問題、RISC-VのJALR命令やRET命令などはレジスタジャンプのためこの手法の効果は絶大である。
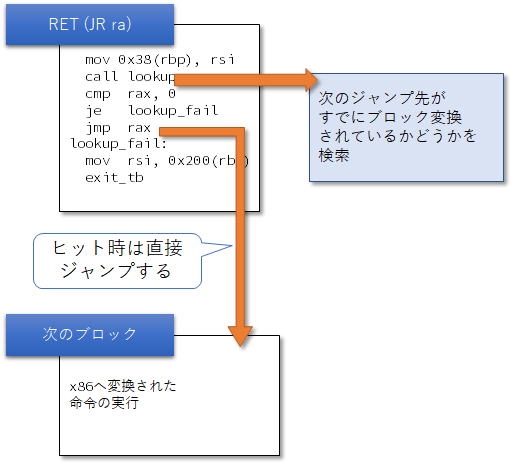
これを実装すると以下のようになった。まず、レジスタジャンプの命令において、TCGを生成する際に以下のTCGを追加する。
// TB lookup and Jump専用ノード tcg_lists.push(TCGOp::new_2op_with_label(TCGOpcode::LOOKUP_PC_AND_JMP, TCGv::new_reg(rs1_addr as u64), TCGv::new_imm(0), Rc::clone(&lookup_fail_label))); // もしLookupに失敗した場合にはここまでジャンプしてくる tcg_lists.push(TCGOp::new_label(Rc::clone(&lookup_fail_label)));
TCGOpcode::LOOKUP_PC_AND_JMPはx86命令に変換する際に以下のようにする。いろいろ書いているが、つまり、
- ヘルパー関数
lookup_func_address(emu_env, address)に飛ぶ。これはゲストのPCアドレスaddressがすでに変換しているかどうかLookup Tableに確認するための関数である。 - もし見つかれば、
lookup_func_address()は0以外を返す。0以外が返ってくれば戻り値(raxに格納されている)として返されている物理アドレスに直接ジャンプするためのJMP命令を生成する。
// Argument 0 : Env let self_ptr = emu.head.as_ptr() as *const u8; let self_diff = unsafe { self_ptr.offset(0) }; gen_size += Self::tcg_gen_imm_u64(X86TargetRM::RDI, self_diff as u64, mc); // Argument 1 : rd u32 gen_size += Self::tcg_gen_load_gpr_64bit(emu, X86TargetRM::RSI, source_reg.value, mc); if source_offset.value != 0 { gen_size += Self::tcg_modrm_64bit_raw_out(X86Opcode::ADD_GV_IMM, X86ModRM::MOD_11_DISP_RSI as u8, 0, mc); gen_size += Self::tcg_out(source_offset.value, 4, mc); } gen_size += Self::tcg_modrm_32bit_out( X86Opcode::CALL, X86ModRM::MOD_10_DISP_RBP, X86TargetRM::RDX, mc, ); gen_size += Self::tcg_out(emu.calc_lookup_func_address() as u64, 4, mc); // Compare result RAX with zero gen_size += Self::tcg_modrm_64bit_out( X86Opcode::CMP_GV_EV, X86ModRM::MOD_10_DISP_RBP, X86TargetRM::RAX, mc, ); gen_size += Self::tcg_out(emu.calc_gpr_relat_address(0) as u64, 4, mc); gen_size = Self::tcg_gen_jcc(gen_size, X86Opcode::JE_rel16_32, mc, &lookup_fail_label); gen_size += Self::tcg_modrm_64bit_raw_out(X86Opcode::JMP_R64_M64, X86ModRM::MOD_11_DISP_RAX as u8, X86TargetRM::RAX as u8, mc);
例えばRISC-VのRET命令は以下のように変換される。
000000008000226e:000000008000226e Hostcode 715d8082 : ret
// CPUモデルのポインタを第1引数に設置 00007F8F9E4C023C 48BFC8263FDFFF7F0000 movabs $0x7FFF_DF3F_26C8,%rdi // ジャンプアドレスが格納されているレジスタの値を第2引数に設置 (今回はRETなのでraレジスタ) 00007F8F9E4C0246 488BB510000000 mov 0x10(%rbp),%rsi // ヘルパー関数 lookup_func_address(emu_env, address) へジャンプ 00007F8F9E4C024D FF95F0040000 callq *0x4F0(%rbp) 00007F8F9E4C0253 483B8508000000 cmp 8(%rbp),%rax // TB探索結果、ゲスト命令ブロックが見つかったか? // 見つからなかった場合0x0000_7F8F_9E4C_0263へジャンプ(通常のジャンプ方式) 00007F8F9E4C025A 0F8403000000 je 0x0000_7F8F_9E4C_0263 // 見つかった場合、戻り値%raxの示すポインタへ直接ジャンプ (速いパス) 00007F8F9E4C0260 48FFE0 jmp *%rax // ブロックが見つからなかった場合の処理。ジャンプ先PCをCPUモデルに格納し // 制御を戻すことにより新たなブロックのデコードと実行が始まる(遅いパス) 00007F8F9E4C0263 488B5510 mov 0x10(%rbp),%rdx 00007F8F9E4C0267 488BC2 mov %rdx,%rax 00007F8F9E4C026A 480500000000 add $0,%rax 00007F8F9E4C0270 48898508020000 mov %rax,0x208(%rbp) 00007F8F9E4C0277 48B85E22008000000000 movabs $0x8000_225E,%rax 00007F8F9E4C0281 48898510020000 mov %rax,0x210(%rbp) 00007F8F9E4C0288 48B84C0A000000000000 movabs $0xA4C,%rax 00007F8F9E4C0292 E900000000 jmp 0x0000_7F8F_9E4C_0297 00007F8F9E4C0297 48B90F00829E8F7F0000 movabs $0x7F8F_9E82_000F,%rcx 00007F8F9E4C02A1 48FFE1 jmp *%rcx
評価結果
TB Lookup and Jumpを実装して速度向上率を計測した。
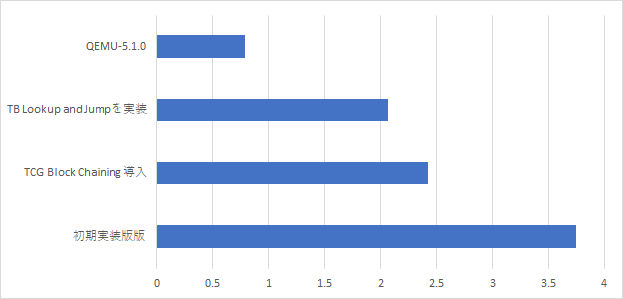
かなり頑張って2秒を切るか切らないかのところまできた。しかしQEMUは倍以上の速度で動作している。まだまだ最適化が足りないなあ...
まだ完成していないところ
一部の最適化はまだ未実装となっている
QEMUはゲスト命令生成時の最適化はもちろん、TCGでの最適化も行っている。例えば私が見つけたものはConstant Propagationにまつわるもので、以下のようなRISC-Vの命令をどのように変換するかを考えてみる。
.section .text _start: addi x1, x0, 10 addi x2, x1, 11 addi x3, x2, 12 addi x4, x3, 13 addi x5, x4, 14 ...
普通に考えれば依存関係が発生して大量のx86のADDが生成されハズだが、実際に生成されるx86命令は以下のようになっている。
0x7fbd1c0003cb: 48 c7 45 08 0a 00 00 00 movq $0xa, 8(%rbp) // x1に10を格納 0x7fbd1c0003d3: 48 c7 45 10 15 00 00 00 movq $0x15, 0x10(%rbp) // x2に10+11=21を格納 0x7fbd1c0003db: 48 c7 45 18 21 00 00 00 movq $0x21, 0x18(%rbp) // x3に21+12=33を格納 0x7fbd1c0003e3: 48 c7 45 20 2e 00 00 00 movq $0x2e, 0x20(%rbp) // x4に33+13=46を格納 0x7fbd1c0003eb: 48 c7 45 28 3c 00 00 00 movq $0x3c, 0x28(%rbp) // x5に46+14=60を格納 0x7fbd1c0003f3: 48 c7 45 30 4b 00 00 00 movq $0x4b, 0x30(%rbp) // .... 0x7fbd1c0003fb: 48 c7 45 38 5b 00 00 00 movq $0x5b, 0x38(%rbp) // ....
定数の加算のため、コンパイル時にすべて値が計算できるためADD命令が消されてしまい、すべてMOV命令(定数をレジスタに格納する命令)に置き換わってしまった。このような最適化が大量に生成されて、高速なQEMU動作を実現しているのだろう。
ゲストアーキテクチャがx86のみとなっている。TCGによる複数プラットフォーム対応として、まずは環境のそろっていそうなARMアーキテクチャへの移植をしたい
これはせっかく中間表現を実装したのだからやってみたい話。例えばAArch64向けに実装して、Raspberry-Piとかで動かしてみるのも面白そうだ。
Rustで作って良かったか?
Rustで書けばすべてが安全だ!ということはないだろう。特に今回私が実装したのはx86におんぶ抱っこであったり、メモリの「この場所のこのメモリを書き換える!」みたいなのが入っている。私のRustの知識はまだまだ浅いが、果たしてこれほどまでに低レイヤにおんぶ抱っこなQEMUをRustで本当に安全に書けるのかというのは結構不安になってくる。
最終的に「ゴリゴリにメモリの内容を書き換える」処理が必要になった。果たしてこれは安全か?
先ほど紹介したとおり、QEMUはジャンプ命令のジャンプ先などの情報を、いったんラベル付けをした後最終命令アドレスが判明してからメモリを書き換える、のような割とごり押しなことをしている。私がRustでこれを再現すると以下のようになってしまった。
// ジャンプ先メモリアドレスの書き換え unsafe { *mem.offset(self.last_host_update_address as isize + 0) = ((text_diff >> 0) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 1) = ((text_diff >> 8) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 2) = ((text_diff >> 16) & 0x0ff) as u8; *mem.offset(self.last_host_update_address as isize + 3) = ((text_diff >> 24) & 0x0ff) as u8; } ... // ラベル部分の差し替え for v_off in &l.code_ptr_vec { let diff = l.offset as usize - v_off - 4; if self.m_arg_config.debug { eprintln!( "replacement target is {:x}, data = {:x}", v_off, diff ); } let s = tb_text_mem.borrow().data(); unsafe { *s.offset(*v_off as isize) = (diff & 0xff) as u8; }; }
unsafeとかを使っているあたり、非常にイマイチだ。結局この結果unsafeだらけになってしまい、どうも「果たしてこれは安全か?」みたいなことになってしまっている。
mutで渡していない構造体を、アセンブリ命令で受け取った挙句mutを付けて別の関数に渡した。果たしてこれは安全か?
これもやっちゃった系。エミュレーション対象のCPUをRustの構造体で管理していたのだが、ホスト命令実行時に(レジスタ位置などの取得のため)どうしてもこの構造体を引数として渡してやる必要がある。でも、そこから先はアセンブリ命令だし、その構造体のOwnerになるわけではないのでReferenceとして渡すわけだ。
しかしゲスト命令実行中に関数ジャンプよろしくRustの関数に戻ることもできる。この時、引数としてその構造体のポインタを指定するのだが受け取り先のRustの関数は、その構造体をOwnerとして指定できるわけだ。これはRustが文法的な観点から権限のチェックを行っているためで、一度アセンブリまで落ちた後に「俺権限持ってるし」みたいな顔をすればmutでデータを受け取ることができる。これは果たして安全なプログラミングといえるのか、不安になってしまった。
// 第1引数RBPにCPUの状態を管理する構造体を渡す execute_guest_insts (emu_env, guest_insnt_addr); // このときにemu_envはmut付きで渡していない。ので変更は不可能なはず // ... // ゲスト命令を実行する。 // その中でヘルパー関数呼び出しにより構造体を第1引数として渡す // ... helper_func (&mut emu_env, helper_idx) // execute_guest_instsとhelper_funcの関係性がアセンブリ命令上でしか表現されないため、第1引数emu_envを`mut`で取れてしまった!
不安要素:ポインタをゴリゴリに使う低レイヤプログラミングにRustは向きか不向きか
私のRustの実力はまだまだだ。しかし今回いろいろ試行を重ねるにつれ、今回のアドレスを直接書き換えるという荒業を実現するためには、ポインタをフル活用して特定の場所を無理やり書き換えるという方式が必須であった。このような「ゴリゴリにポインタを利用する」デザインでは、果たしてRustの安全性を最大限活用できるのか、私自身不安が残る。しかしこれはQEMUのアルゴリズムをそのままRustで置き換えてしまったから生じる話であって、もう少しRust向けに最適化した方式を使えば安全に実装できるのかもしれない。
また、ラベルの置き換えなどについてはメモリアドレスに対する参照において所有権が1人しか持てないというRustの制約により非常に苦しめられることになった。最終的に結局RcとRefCellを活用して参照カウンタ方式を導入することにより事なきを得たが、果たしてここまで参照カウンタ方式を導入しなければならないアーキテクチャにおいて、Rustを使用しなければならなかったのか、我ながら疑問に思ってしまった。
しかしとにもかくにもTCGの非常に低レイヤの部分以外で、ドライバの部分や制御部分はRustで書くことができるのでその部分は安全に実装できているはずだ。そういったくだらないバグを防ぐためには良いかもしれない。しかし、それがQEMUがRustに置き換えられなければならない直接的な理由になるだろうか?QEMUとRust、まだまだ私自身理解が中途半端だ。勉強を続けていこう。