前回QEMUを解析しながら、QEMUがBlock Chainingという技術で直接TCG間をジャンプしていること、そしてメインスレッドとモニタスレッドが別に走っておりメインスレッドを高速化していることを見た。これを私のエミュレータでも実装してみたい。まずはマルチスレッド化から挑戦してみよう(というかマルチスレッド化をまず先に行わないと、Block Chainingを実装しても止まる手段がない)。
Rustにおけるマルチスレッドの実装については前回調査したので、それに従って実装を行ってみる。まず、メインスレッドとモニタスレッドが共有する変数をm_notify_exitとしている。この変数に対してメインスレッドが1を書き込むと、それに応じて全プログラムが停止する。まあ全プログラムが停止するのは乱暴な気もするけど、QEMUはどうしているんだろう。今ブログを書きながらふと疑問に思った。
pub m_notify_exit: Arc<AtomicBool>,
- メインスレッド側:
if emu.m_arg_config.machine == MachineEnum::RiscvSiFiveU && (guest_phy_addr & !0xfff) == 0x10_0000 { emu.m_notify_exit.store(true, Ordering::Relaxed); return MemResult::NoExcept as usize; }
- モニタスレッド側:
thread::spawn({ let notify_stop = Arc::clone(&self.m_notify_exit); let time_start = Arc::clone(&self.m_time_start); // let machine = Arc::clone(&self.m_arg_config.machine); move || loop { thread::sleep(Duration::from_millis(10)); // if machine == MachineEnum::RiscvVirt && self.get_mem(0x1000) != 0 { // if self.get_mem(0x1000) & 0x01 == 1 { // std::process::exit(0); // } // } if /* machine == MachineEnum::RiscvSiFiveU && */ notify_stop.load(Ordering::Relaxed) { let end = time_start.elapsed(); eprintln!("{}.{:03} finished", end.as_secs(), end.subsec_nanos() / 1_000_000); std::process::exit(0); } // if machine == MachineEnum::RiscvVirt && self.get_mem(0x3000) != 0 { // if self.get_mem(0x3000) & 0x01 == 1 { // eprintln!("0x3000 finished."); // break; // } // } } });
いろいろコメントアウトしまくっている。スレッドを立ち上げると、オプション変数などのこれまでアクセスしていたものが簡単に参照できなくなる(アップデートしないのに!)
とりあえずこんな簡単な実装でマルチスレッド化を行った。速度向上率を実験してみる。
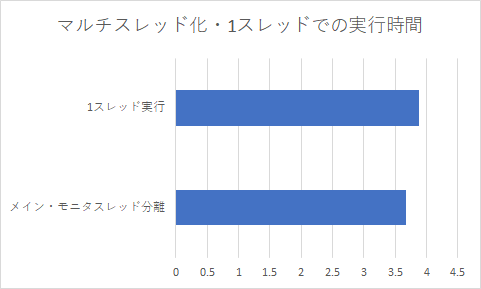
数パーセント速くなったかな?まあマルチスレッド化の目的は速度向上ではなく、次のTCG Block Chainingのための土台だから、ここまでは良しとしよう。つぎはいよいよBlock Chainingの検討に入る。