
(2016/04/25 一部誤字修正、コメント追加)
昨日の日記の続き。
次は、Tesla P100のハードウェア詳細について見て行く。
注意:GPU初心者が書いている文章のため、間違いが含まれている可能性があります。間違いがあれば、指摘いただければ嬉しいです。
GP100 GPU Hardware Architecture In-Depth
GP100の特徴として大量の計算リソースがあげられるのだが、P100で搭載されているのは、
- Graphics Processing Clusters(GPC) : 6個
- Texture Processing Clusters (TPC) : 30個
- Streaming Multiprocessors (SMs) : 60個
となっている。図を見ればわかるのだが、それぞれ各GPCの中に5つのTPCが入っており、各TPCの中に2つのSMが入っているというイメージだ。 さらにSM内には64個のCUDAコアが入っており、全体で 64 * 60 = 3840個のCUDAコアが入っている計算になる。
さらにこれに加えて、8個の512-bitのメモリコントローラが入っており、L2キャッシュのサイズは4096kBとなっている。
画像はhttp://wccftech.com/nvidia-pascal-tesla-p100-gp100-gpu/より引用。

さらに、過去のGPUとの性能の違いを示すための表が掲載されているのだが、SM数が56個。、TPC数が28個となっており、なぜか文中のものと比べて少ない。これはなぜだかよくわからない。
画像はhttp://www.hpcwire.com/2016/04/05/nvidia-monster-pascal-gpu-card-gtc16/より引用。
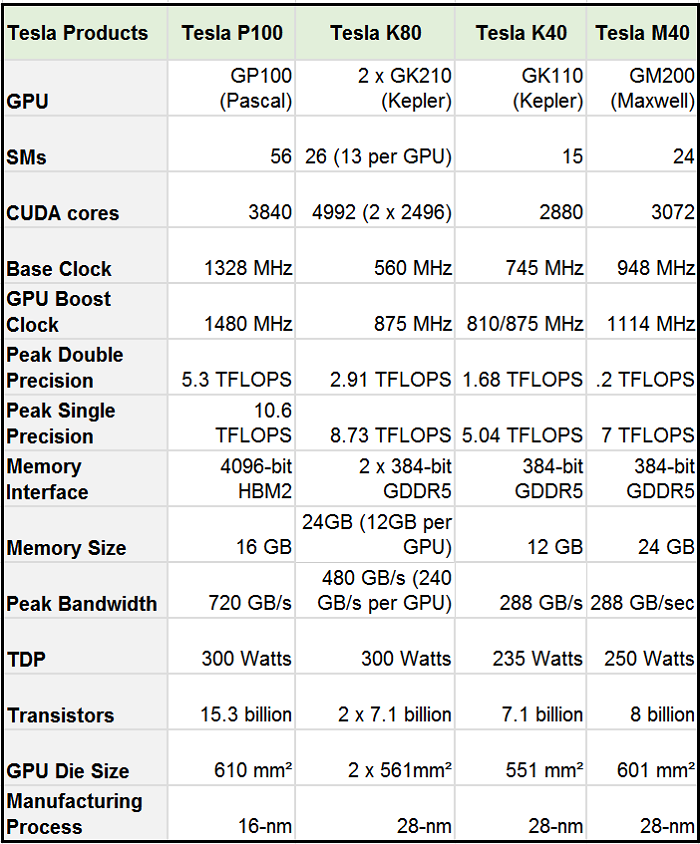
これを比較すると、SM数はTesla M40に比べて倍以上になっているのだが、SM内のFP32コアの数が半分に減っているため、計算リソースが倍増となっているわけではない。 FP32のコア数はTesla M40では3072個であったのが、GP100では3584となっており若干増加した程度だ。 一方で、FP64の演算器の数は全体でTesla M40での96個から、1792個に大幅に増強されていた。つまり単精度の演算よりも、倍精度、あるいは半精度の演算の方がよく使われるという見通しの下、こういう配分になっているのかもしれない。
GP100では半精度の演算器の数の資料がなかった。バンド幅は倍増しているものの、サイクル数を減らしているのか、演算器を倍積んでいるのかは良く分からない。
さらに、アトミック命令系も強化されている。GP100ではメモリ空間が各コアからフラットに見えるようになっているらしい。 また、NVLink経由でのGPU間通信も強化されていることから、アトミック演算も高速になるとしている。これについては具体的に何が要因に高速化されているのかわからない。 NVLinkの高速化により担保された性能なのか、そもそも内部バスの向上により担保されている能力なのかは不明だった。 ただし、アトミック演算はこれまでのFP32での演算から、FP64の演算にまで拡張されているとのことだった。
Tesla P100: World's First GPU with HBM2
HBM2(High Bandwidth Memory version 2)はメモリをチップの外に置くのではなく、ダイのすぐ傍に配置することで高速な伝送を可能にする技術。
GP100チップは、まずPassive Silicon Interposerと呼ばれるシリコンに乗せられ、そのすぐ傍に同様にHBM2メモリが配置される。HBM2メモリはGP100の場合は4段にスタックされ、それらがDRAMとなっている。
図はホワイトペーパーより抜粋。4枚目のDRAMは残り3枚と比較して厚くなっている。これはHBM2のスタックメモリの高さをGP100のチップと同じにすることで、ヒートシンクを平坦に構成することができるようになっている。

HBMの性能は、DRAMダイあたり8Gbの容量を積むことができる。GP100では4つのスタック、つまり16枚のダイとなるので、全体では16GBのメモリを積んでいる。 性能としては、P100はスタック当たり180GB/secとのことなので、4スタックだと180×4で720GB/secというところだろうか。速いな。。。