キャッシュの置き換えアルゴリズムというのはいろいろあるけれども、ここではそういう話ではなくて「どうアトミックにキャッシュを置き換えるか」ということを考えた。 つまり、キャッシュを掃き出してロードするまでには間隔があくわけで、それをきちんと実行しないとキャッシュラインを吐き出した後に残っているCPUキャッシュラインに 誤ってデータをストアしてしまう可能性がある。
L1Dのデータ置き換え操作についてフローを考えたので、備忘録として残しておく。 以下はメモ。
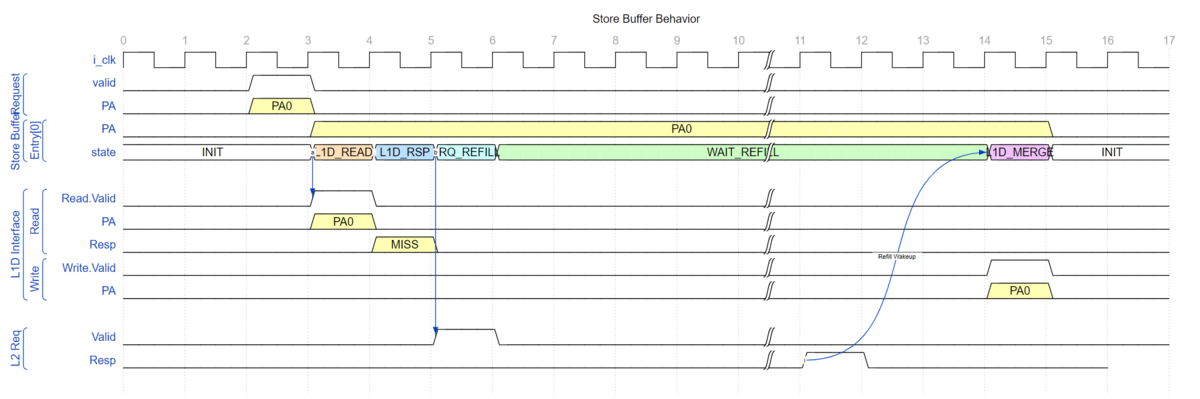
L1Dデータの掃き出し
L1Dデータの掃き出し(eviction)は、以下の条件で実行されます。 1. ロード命令パイプライン実行中にL1Dキャッシュを確認した際、L1Dミス発生かつ当該キャッシュラインに空きがない場合 2. ストア命令が完了後にL1Dキャッシュに書き込む際、L1Dミス発生かつ当該キャッシュラインに空きがない場合
掃き出し行うキャッシュラインの管理は、LRQ内で行われます。
の場合、L1DキャッシュリクエストがLRQ内のエントリに格納されると同時に、 同じエントリに掃き出し対象のキャッシュラインの情報が格納されます。 このとき、L1Dキャッシュのタグ情報は更新されないため、LRQ内のエントリは、そのエントリが有効である間、LSUパイプラインを監視し、 同じアドレス範囲のメモリアクセスが発生するとハザードを通知し、LRQの処理とL1Dキャッシュの完全な入れ替えが完了するまでは 当該後続命令の再実行を禁止します。
の場合、ストア命令のコミット終了後にL1Dキャッシュラインの存在確認が行われ、もし2. の条件を満たした場合は 掃き出し対象のキャッシュラインがLRQに取得されます。
LRQはミスを発生したキャッシュラインを取得するためにCPU外部にリードリクエストを送出しますが、 同時に掃き出し対象のキャッシュラインもCPU外部にライトリクエストで放出します。
"同じアドレス範囲のメモリアクセスが発生すると完全な入れ替えが完了するまでは当該命令の再実行を禁止する"理由は、 L1Dキャッシュのタグ情報は置き換え対象となるキャッシュラインの情報にまだ置き換わっていないため、 もし後続の命令が吐き出されるキャッシュラインに対して書き込みを行っても、すでにキャッシュラインがCPU外部に吐き出されてしまっているためです。
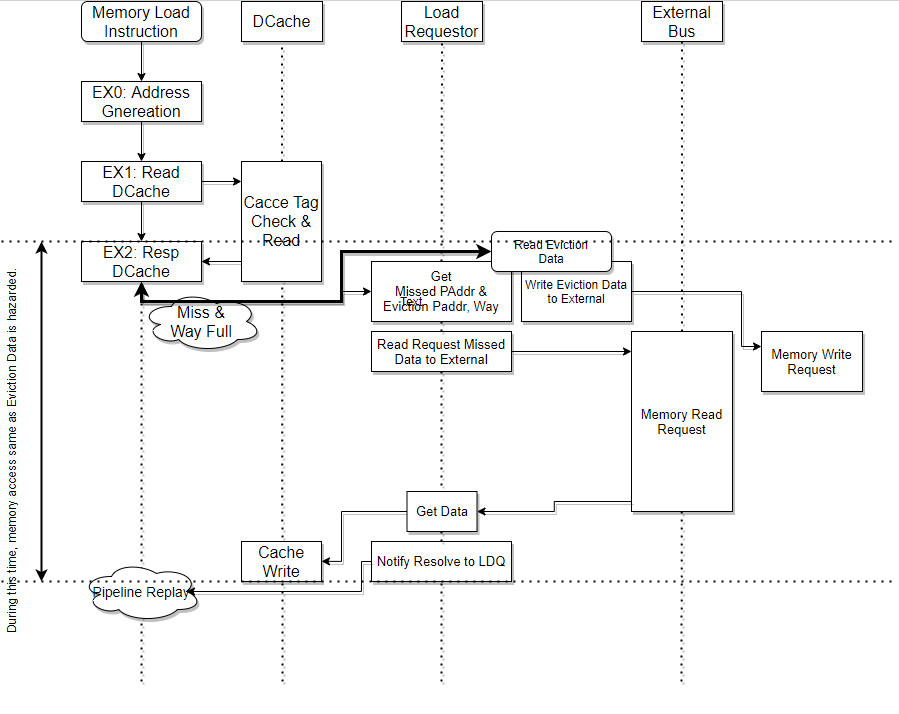
")

![ディジタル回路設計とコンピュータアーキテクチャ[ARM版]](https://m.media-amazon.com/images/I/51HrwEwLrGL._SL500_.jpg "ディジタル回路設計とコンピュータアーキテクチャ[ARM版]")