ハードウェア設計において、複数のリクエストが同時に発生した際に、どのリクエストを優先するかを決定するアービタは非常に重要なコンポーネントだ。
ETH Zurichのcommon_cellsライブラリに含まれるrr_arb_tree.svの実装について詳しく見ていくことにした。
このモジュールは、ラウンドロビン方式によるnon-starvingのアービトレーションを実現し、対数的な遅延でスケーラブルな設計となっている。
Non-starving とは、どのリクエストも永続的に無視されることがなく、必ず処理される機会が与えられることを意味する。 従来の固定優先度方式では低優先度のリクエストが高優先度のリクエストによって永続的にブロックされる「飢餓状態」が発生する可能性があるが、ラウンドロビン方式では優先度が循環的に変更されるため、すべてのリクエストが公平に処理される。
ちなみに、最後まで見ていってこのモジュールはもっと効率化できるのではないかという気分になってきた。
一端 rr_q をインデックスで保持しているが、ワンホットで保持しているともっと楽になるはずだ。それについては、次に考えてみよう。
モジュールの概要
基本機能
rr_arb_treeは以下の機能を提供する:
- Non-starvingラウンドロビンアービトレーション: 各サイクルで優先度が回転し、すべてのリクエストが公平に処理される
- 対数的スケーラビリティ: 入力数に対してO(log N)の遅延で動作する
- 柔軟な設定オプション: 外部優先度制御、AXI準拠のハンドシェイク、ロック機能など
主要パラメータ
parameter int unsigned NumIn = 64, // 入力数 parameter int unsigned DataWidth = 32, // データ幅 parameter type DataType = logic [DataWidth-1:0], // データ型 parameter bit ExtPrio = 1'b0, // 外部優先度制御 parameter bit AxiVldRdy = 1'b0, // AXI準拠ハンドシェイク parameter bit LockIn = 1'b0, // ロック機能 parameter bit FairArb = 1'b1 // 公平アービトレーション
アーキテクチャの詳細
1. ツリー構造の実装
アービタは対数的なツリー構造を採用している:
localparam int unsigned NumLevels = unsigned'($clog2(NumIn));
各レベルでは2つの入力から1つの出力を選択する基本的なアービタが使用される。 これにより、64入力の場合でも6レベル(log₂(64) = 6)で実現できる。
2. ラウンドロビン優先度の管理
内部優先度制御(ExtPrio = 0)
idx_t rr_q; // 現在の最高優先度インデックス
内部状態rr_qが各サイクルで更新され、優先度が回転する。
何も考えずに、 ExtPrio と LockIn が有効でないとして、 req_d がそのまま req_i を受け入れる:
assign req_d = req_i;
公平アービトレーション vs 不公平アービトレーション
不公平アービトレーション(FairArb = 0):
assign rr_d = (gnt_i && req_o) ? // アービトレーションした結果出力に成功 (gnt_i はだいたいの場合Validと考えて良い) ((rr_q == idx_t'(NumIn-1)) ? '0 : rr_q + 1'b1) : rr_q;
単純にインデックスを1つ進める方式である。アクティブでないリクエストも考慮されるため、不公平なスループット分布になる可能性がある。
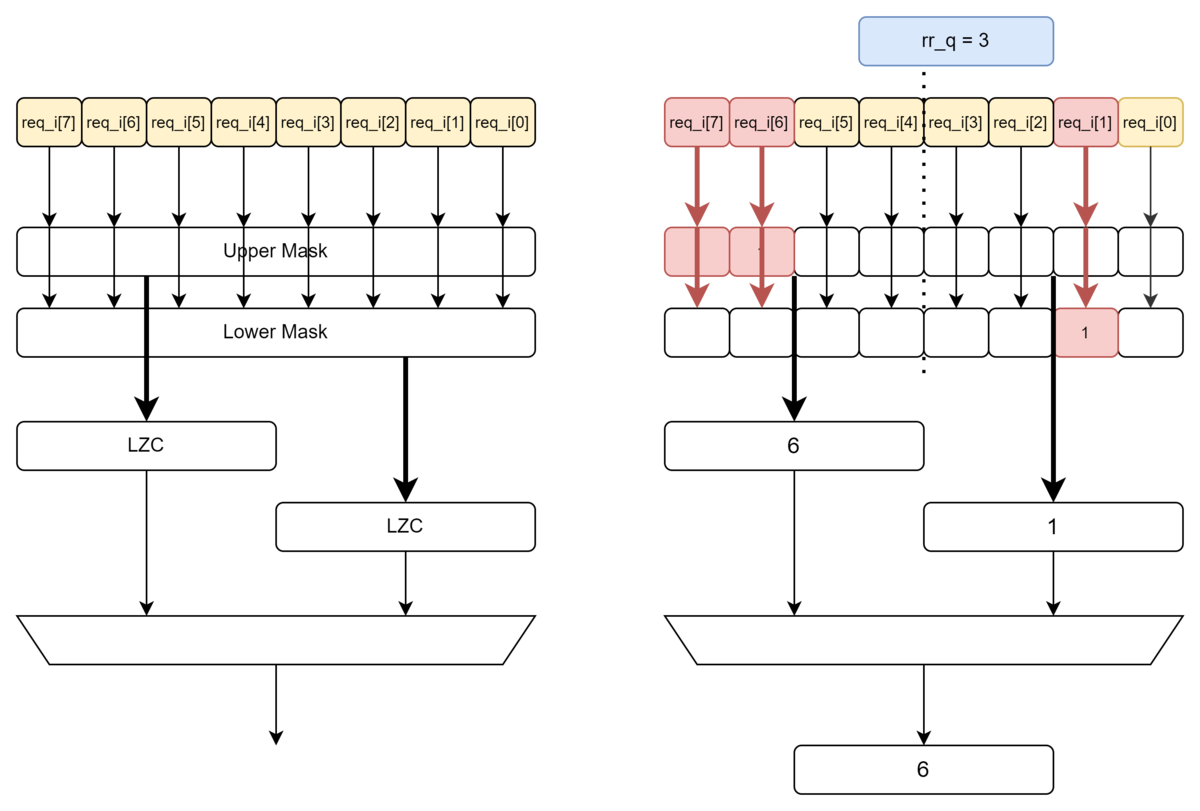
公平アービトレーション(FairArb = 1):
// 上位マスク: 現在の優先度より高いインデックス for (genvar i = 0; i < NumIn; i++) begin : gen_mask assign upper_mask[i] = (i > rr_q) ? req_d[i] : 1'b0; assign lower_mask[i] = (i <= rr_q) ? req_d[i] : 1'b0; end
upper_mask の意味は、現在の優先度よりもインデックスの大きな信号で req_d[i] を upper_mask[i] に値が設定される。
lower_mask の意味は、現在の優先度よりもインデックスの小さな信号で req_d[i] を lower_mask[i] に値が設定される。
この状態で、LZC (Leading Zero Count) を適用する。
// 2つのLZC(Leading Zero Counter)を使用 lzc #(.WIDTH(NumIn), .MODE(1'b0)) i_lzc_upper (.in_i (upper_mask), .cnt_o (upper_idx), .empty_o(upper_empty)); lzc #(.WIDTH(NumIn), .MODE(1'b0)) i_lzc_lower (.in_i (lower_mask), .cnt_o (lower_idx), .empty_o( )); assign next_idx = upper_empty ? lower_idx : upper_idx;
LZCを使用して、もっとも低い位置の req_i 信号を特定する。
2つ実行したうえで1つを選んでいるのは、 現在の優先度 rr_q よりも高いところでリクエストを生成している req_i が存在しているか、そうでない場合は rr_q よりも低いところでリクエストを生成している櫃がいるかを別々に判定し、それを洗濯している。
3. LZC(Leading Zero Counter)の活用
公平アービトレーションでは、lzcモジュールが重要な役割を果たす:
module lzc #( parameter int unsigned WIDTH = 2, parameter bit MODE = 1'b0 // 0: trailing zero, 1: leading zero ) ( input logic [WIDTH-1:0] in_i, output logic [CNT_WIDTH-1:0] cnt_o, output logic empty_o );
LZCは入力ベクトル内の最初の'1'の位置を効率的に検出し、 の遅延で動作する。
4. ロック機能(LockIn)
リクエストが承認されなかった場合、アービトレーション決定を保持する機能:
if (LockIn) begin : gen_lock logic lock_d, lock_q; logic [NumIn-1:0] req_q; assign lock_d = req_o & ~gnt_i; assign req_d = (lock_q) ? req_q : req_i;
この機能により、下流がビジーの場合でもアービトレーション決定が変更されない。
実装の詳細解析
0. 現在の優先度を rr_q に保持している。
typedef idx_t = logic [IdxWidth-1:0]; /* lint_off */ idx_t rr_q; // 現在の優先度を保持している logic [NumIn-1:0] req_d;
1. ツリーの構築
for (genvar level = 0; unsigned'(level) < NumLevels; level++) begin : gen_levels for (genvar l = 0; l < 2**level; l++) begin : gen_level // index calcs localparam int unsigned Idx0 = 2**level-1+l;// current node localparam int unsigned Idx1 = 2**(level+1)-1+l*2; // 各ノードでのアービトレーションロジック assign sel = ~req_nodes[Idx1] | req_nodes[Idx1+1] & rr_q[NumLevels-1-level];
各レベルで、ラウンドロビン状態の対応するビットを使用して選択信号を生成する。
Idx0 はツリーの中のノードの位置を一意に決めるためのインデックスで、Idx1はその子供を特定するためのインデックスだ。
Level = 3: [7] [6] [5] [4] [3] [2] [1] [0]
\ / \ / \ / \ /
Level = 2: [3] [2] [1] [0] (Idx0=3,4,5,6; l=0,1,2,3)
\ / \ /
Level = 1: [1] [0] (Idx0=1,2; l=0,1)
\ /
Level = 0: [0] (Idx0=0, l=0)
最上位 Level = 3 での動作
req_nodesは次の階層でマージされる2つのノードのうち、どちらかがreq_iをアサートされている場合 1となる。assign req_nodes[Idx0] = req_d[l*2] | req_d[l*2+1];つまり、回路全体としてreq_iをアサートしているノードが存在しているかを示している。selは、ペアとなる2つの入力のどちら側がリクエストを受け付けるかを示している。 偶数側がreq_i[i]をアサートしていない OR 奇数側がreq_i[i]をアサートしている ANDrr_qの下位1ビットが1である (つまり優先度のインデックスが奇数である) のときにsel=1となる。
それ以外の階層 での動作
req_nodesは下位の階層でマージされたリクエストを、さらにマージする。回路全体としてはreq_iをアサートしているノードが存在しているかを示している。selは、どちら側のリクエストを受け付けるかを示している。 Level=3の時と同様に、 偶数側がreq_i[i]をアサートしていない OR 奇数側がreq_i[i]をアサートしている ANDrr_qの該当するレベルのビットが1である (つまり優先度のインデックスが奇数である) のときにsel=1となる。
assign gnt_nodes[Idx1] = gnt_nodes[Idx0] & ~sel; assign gnt_nodes[Idx1+1] = gnt_nodes[Idx0] & sel;
2. インデックスの伝播
assign index_nodes[Idx0] = (sel) ? idx_t'({1'b1, index_nodes[Idx1+1][NumLevels-unsigned'(level)-2:0]}) : idx_t'({1'b0, index_nodes[Idx1][NumLevels-unsigned'(level)-2:0]});
選択された入力のインデックスを上位レベルに伝播させる。
3. グラント信号の逆伝播
上記の論理で、入力側から出力側にツリーを縮退させながらインデックスを特定していったわけだが、今度はこれを逆方向にたどって、入力側にGntしたノードを通知する。
Idx1を子ノード側のインデックスとして、selされたノード結果を上位ノードから下位ノードへ伝搬していく。
assign gnt_nodes[Idx1] = gnt_nodes[Idx0] & ~sel; assign gnt_nodes[Idx1+1] = gnt_nodes[Idx0] & sel;
出力からのグラント信号を選択された入力に逆伝播させる。