Weak Memory Modelについてもう少し知識をつけたかったので、論文を読んでみることにした。
基本的にDeepLに翻訳してもらったものを、自分で読み直しながら直しているだけなので、自分でまとめているわけではない。 冗長なのは無編集でブログに貼っている、ということで。
II. 背景と関連研究
A. メモリモデルの形式的定義
ここでは、SC[31]を例にして、操作的定義と公理的定義の概念を説明する。
SCの運用上の定義:図1はSCの抽象的なマシンを示しており、すべてのプロセッサはモノリシック・メモリに直接接続されている。このマシンの動作は単純で、1ステップで任意のプロセッサを選び、そのプロセッサ上で次の命令をアトミックに実行する。つまり、命令がreg-to-reg(すなわちALU演算)または分岐命令であれば、プロセッサのローカルレジスタの状態を変更するだけであり、ロードであれば、モノリシックメモリから瞬時に読み出し、レジスタの状態を更新し、ストアであれば、モノリシックメモリを瞬時に更新し、PCをインクリメントする。2つのプロセッサが同じステップで命令を実行することはないことに注意すべきである。

例として、図2のリトマス・テスト・Dekkerを考えてみよう。I1→I2→I3→I4の順に命令を実行して抽象マシンを動作させると、SCの合法的な動作r1=0、r2=1が得られるが、マシンを動作させてもr1=r2=0は得られない。

リトマス・テスト: 本稿の残りの部分では、図2のようなリトマス・テストを使って、メモリ・モデルの特性を示したり、2つのメモリ・モデルを区別したりする。リトマス・テストはプログラムのスニペットであり、このプログラムの特定の動作が各メモリ・モデルで許容されるかどうかに注目する。我々はウィーク・メモリ・モデルを研究しているので、非SC動作(例えば、図2のr1 = 0, r2 = 0)に興味がある。
SCの公理的定義:SCが許容するプログラム動作が満たさなければならない公理を与える前に、まず、公理的設定におけるプログラム動作とは何かを定義する必要がある。
本稿のすべての公理的定義において、プログラム動作は以下の3つの関係によって特徴付けられる:
- プログラム順序$<_{po}$: プログラム論理に従って1つのプロセッサ上で実行される命令の局所的順序。
- グローバル・メモリ順序$<_{mo}$: 全プロセッサからの全メモリ命令の総順序であり、メモリ命令の実際の実行順序を反映する。
- リードフロム関係 $rf →$: 各ロードが読み出すストアを特定する関係(すなわち、ストア$rf→$ロード)。
$<{po}$, $<{mo}$, $rf→i$ で表されるプログラム動作は、メモリモデルの公理をすべて満たす場合、メモリモデルによって許容される。
図3にSCの公理を示す。公理InstOrderSCは、すべてのメモリ命令のペア(I1とI2)間のローカル順序は、グローバル順序で保存されなければならない、すなわち、SCではリローダリングはない。公理LoadValueSCは、各ロードの値を指定する。ロードは、$<_{mo}$のロードより古いストアの中で最も若いストア、すなわちmax<mo{ストアの集合}しか読み出すことができない。
B. アトミック・メモリと非アトミック・メモリ
実装におけるコヒーレント・メモリ・システムは、アトミック・メモリ・システムと非アトミック・メモリ・システムの2種類に分類することができるので、別々に説明する。
アトミック・メモリ: アトミック・メモリ・システムでは、発行されたストアはすべてのプロセッサに同時に通知される。
このようなメモリシステムは、ロードとストアを瞬時に処理するモノリシック・メモリに抽象化できる。アトミック・メモリ・システムの実装はよく理解されており、実際に広く使われている。例えば、MSI/MESIプロトコルを持つコヒーレントなライトバック・キャッシュ階層は、アトミック・メモリ・システムとなり得る[32]、[33]。このようなキャッシュ階層では、ストア要求がL1データ・アレイに書き込まれた瞬間が、モノリシック・メモリ抽象におけるストアの瞬時処理に相当し、ロード要求がその値を取得した瞬間が、モノリシック・メモリにおけるロードの瞬時処理に相当する。
アトミック・メモリの抽象化は、コヒーレント・キャッシュ階層の上にプロセッサごとにプライベート・ストア・バッファを追加すれば、少し緩和できる。ストア・バッファリングにより、ストアの発行元プロセッサは他のどのプロセッサよりも先にストアを見ることができるが、発行元プロセッサ以外のプロセッサからも同時にストアが見えるようになる。
非アトミック・メモリー:非アトミックメモリシステムでは、1つのストアが異なるタイミングで異なるプロセッサから見えるようになる。
我々の知る限り、現在ではPOWERプロセッサーのメモリ・システムのみが非アトミックである。(GPUにも非アトミック・メモリがあるかもしれないが、CPUのメモリモデルのみを扱う本稿の範囲外である)。メモリ・システムが非アトミックになるのは、通常、共有ストア・バッファや共有ライトスルー・キャッシュがあるためである。
図4aのマルチプロセッサを考えてみよう。2つの物理コアC1とC2が2レベルのキャッシュ階層を介して接続されている。L1キャッシュは各物理コアのプライベートであり、L2は最終レベルの共有キャッシュである。各物理コアは同時マルチスレッディング(SMT)を有効にしており、プログラマには2つの論理プロセッサとして見える。つまり、論理プロセッサP1とP2はC1とそのストアバッファを共有し、論理プロセッサP3とP4はC2を共有する。P1がストアを発行すると、ストアはC1のストア・バッファにバッファリングされる。この場合、P2はストアの値を読み出すことができるが、P3とP4は読み出すことができない。さらに、P3またはP4が同じアドレスに対してストアを発行した場合、P1によるストアがストア・バッファに残っている間に、この新しいストアがC2のL1にヒットする可能性がある。従って、P3またはP4による新たなストアは、ストア・アドレスのコヒーレンス順序において、P1によるストアよりも前に順序付けられる。その結果、共有ストア・バッファはキャッシュ階層とともに非アトミック・メモリ・システムを形成する。
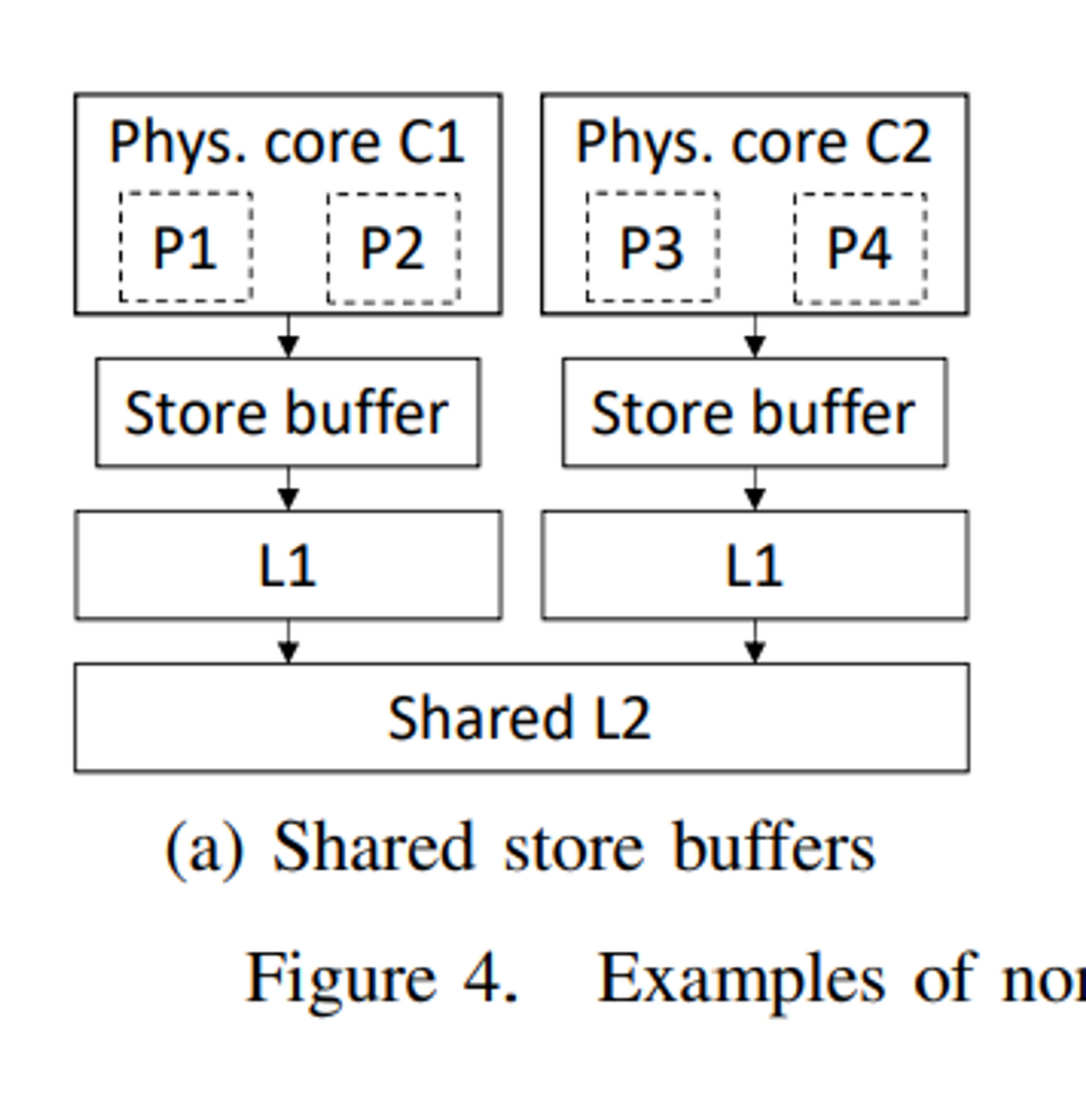
各論理プロセッサに、共有ストア・バッファ内のストアにタグを付けさせ、他のプロセッサがストア・バッファ内のストアを読み出さないようにすることができる。しかし、L1がライトスルー・キャッシュの場合、同様の理由でメモリシステムは非アトミックとなり、L1に値をタグ付けすることは現実的ではない。
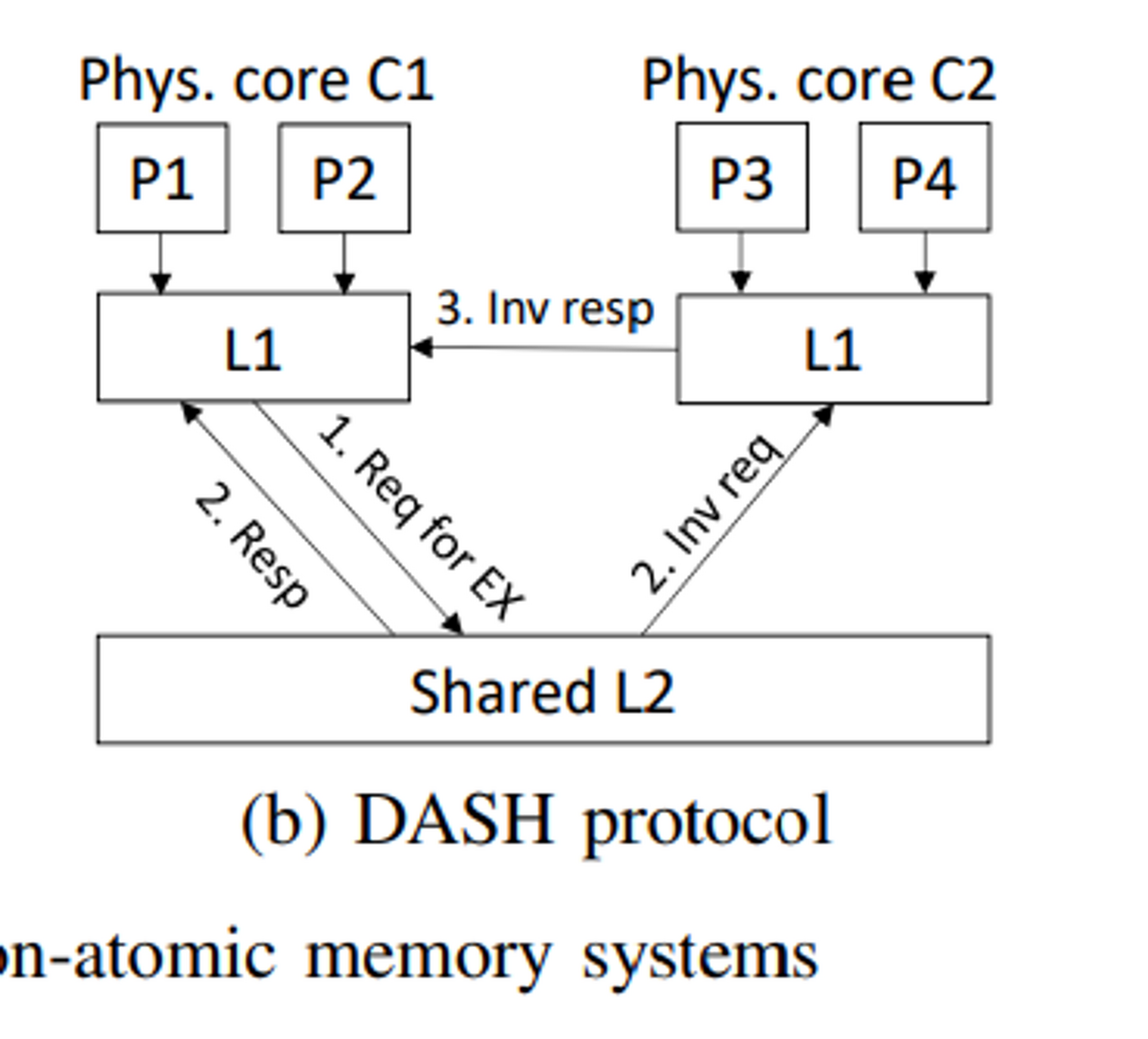
L1をライトバックにしたとしても、図4bに示すようにDASHコヒーレンス・プロトコル[34]を使用すれば、メモリ・システムはアトミック・メモリ・システムにならない可能性がある。両方のL1がアドレスaを共有状態に保持し、P1がaへのストアを発行している場合を考える。この場合、コアC1のL1は、共有されているL2に対して排他的許可のリクエストを送信する。この要求を見たL2は、C1への応答とC2への無効化要求を同時に送信する。C1のL1は応答を受け取ると、C2からの無効化応答を待つことなく、直接キャッシュにストアデータを書き込むことができる。この瞬間、P2はC1のL1から最新のストアデータを読み出すことができるが、P3はaの元のメモリ値しか読み出すことができない。この瞬間、P3またはP4がaに対して別のストアを発行した場合、この新しいストアは、アドレスaのコヒーレンス順序において、P1によるストアの後に順序付けられなければならない。これは、共有ストア・バッファや共有ライトスルー・キャッシュを持つ非アトミック・メモリ・システムとは異なる。
アトミック・メモリ・モデルと非アトミック・メモリ・モデル:ほとんどのメモリ・モデルはアトミック・メモリ・モデルであり、例えばSC、TSO、RMO、Alpha、ARMv8などがある。現在、非アトミック・メモリ・モデルは POWERメモリモデルだけである。一般に、非アトミック・メモリ・モデルははるかに複雑である。実際、ARMは最近、バージョン8でメモリ・モデルを非アトミックからアトミックに変更した。アトミック・メモリ・モデルが普及しているため、本稿ではアトミック・メモリ・モデルのみを取り上げる。
C.既存のメモリ・モデルの問題点
ここで、既存のウィーク・メモリ・モデルを概観し、その問題点を説明する。
データ・レース・フリー(DRF)のSC: データ・レース・フリー0(DRF0)は、共有変数のレースがロックに制限されるソフトウェア・プログラムの重要なクラスである[35]。Adveら[35]は、DRF0プログラムの動作がSCに含まれることを示した。DRF0は、DRF-1[36]、DRFx[37]、DRF-rlx[38]に拡張され、より多くのプログラミングパターンをカバーしている。
また、DRFプログラムを高速化するハードウェア方式[39]~[41]もある。DRFは非常に有用なプログラミング・パラダイムであるが、ISAのメモリモデルは、非DRFプログラムを含むすべてのプログラムの動作を規定する必要がある。
リリース・コンシステンシ(RC): RC [42]も重要なソフトウェア・プログラミング・モデルである。プログラマは、同期メモリ・アクセスを通常のものと区別し、同期アクセスにacquireまたはreleaseというラベルを付ける必要がある。
直感的には、プロセッサP1のロード・acquireがプロセッサP2のストア・releaseの値を読み出す場合、P1のロード・acquireより若いメモリ・アクセスは、P2のストア・releaseより古いメモリ・アクセスの後に発生する。Gharachorlooら[42]は、適切にラベル付けされたプログラムとは何かを定義し、そのようなプログラムの動作がSCであることを示した。
RCの定義は、全てのプログラムの動作をイベントの並び替えで定義しようとするものであり、イベントとはプロセッサに対してメモリ・アクセスを行うことを指す。しかし、特にプログラムが適切にラベル付けされていない場合、イベントの順序に基づいて各負荷が得るべき値を導出することは容易ではない。Zhangら[43]は、RC定義(RCSCとRCPCの両方)が非アトミック・メモリ・モデルに特有な動作をいくつか認めていることを示したが、それでも実装上、すべての非アトミック・メモリ・システムをサポートしているわけではない(例えば、共有ストア・バッファや共有ライトスルー・キャッシュをサポートしていない)。 RMOとAlpha: RMO[44]とAlpha[45]は、アトミック・メモリ・モデルのクラスにおけるRCの亜種と見なすことができる。
両者とも4つのロード/ストアの並べ替えをすべて許容する。しかし、依存する命令の順序に関しては、両者には異なる問題がある。RMOは特定のケースで依存命令のリオーダリングを意図しているが、その定義は、実装が投機的ロード実行とストア転送を同時に実行することを禁じている[43]。Alphaは、依存命令のリオーダリングができる点でより自由である。しかし、これはOOTA(out-of-thin-air)問題を引き起こす[46]。図5は、値42が空中から生成されるOOTA動作の例を示している。すべてのロード/ストアのリオーダリングを許可することが、単にSCの公理的定義からInstOrderSC公理を削除することであるならば、この動作は合法である。このような問題を回避するために、Alphaは複雑な公理を導入している。この公理は、周期的な依存関係を回避するために、若いストアが古いロードと一緒に並び替えられるべきでないかどうかを判断するために、すべての可能な実行パスを調べることを要求している[45, Chapter 5.6.1.7]。
依存性とOOTAの問題に対処するために、最近提案されたウィーク・メモリ・モデルWMM [43]は、依存性を指定する際の複雑さを避けるために、依存性の順序付けを完全に緩和しているが、OOTAの問題を避けるために、常にロードからストアへの順序付けを強制している。これに対して本稿では、GAMの構築手順を通じて、依存関係の順序制約がどこから来るかを説明する。
ARM:セクションIで述べたように、ARMはメモリモデルを変更し続けている。加えて、ARMのメモリモデルは、同じアドレスに対するロードの順序に複雑さをもたらしている。
D. その他の関連研究
Adveらによるチュートリアル[47]は、上記で説明したいくつかのモデルと、その他のモデル [48]、[49]の関係を説明している。最近では、GPU[50]~[55]や不揮発性メモリ[56]~[59]などの新しいコンピューティング・リソースのためのプログラミング・モデルに関する研究が盛んである。また、C/C++[1]、[29]、[60]~[64]、Java[65]~[67]などの高級言語のセマンティクスを規定する取り組みも行われている。本稿では、CPU のメモリモデルについてのみ述べる。モデル検査ツールは、メモリ・モデルに関連するバグを発見するのに有用である。[23]、 [28]、[68]~[71]は、メモリ・モデル・テストの様々な側面のためのツールを提示している。