内容的に興味があったので、以下の論文をざっと読んでみた。
- Complexity-effective superscalar processors
https://dl.acm.org/doi/10.1145/384286.264201
論文の概要:スーパ・スカラ・マイクロアーキテクチャの各コンポーネントを分析し、どの部分がもっとも複雑で回路遅延に影響を与えるのかを分析した。初期分析の結果、命令のWakeup/Selectionの論理が最も遅延が大きくなることが明らかになった。
そこで、本研究では、Wakeup/Selectionの論理を簡略化するためのマイクロアーキテクチャを提案する。Wakeup/Selectionの論理を、依存関係のある命令毎にグループ化しFIFO形式にすることで、性能の減退を最小限に防ぎつつ論理を簡略化することを考える。
スーパー・スカラ・マイクロアーキテクチャは、アウト・オブ・オーダ実行を実現するために幾つかの複雑な回路コンポーネントが存在する。
- レジスタ・リネーミング
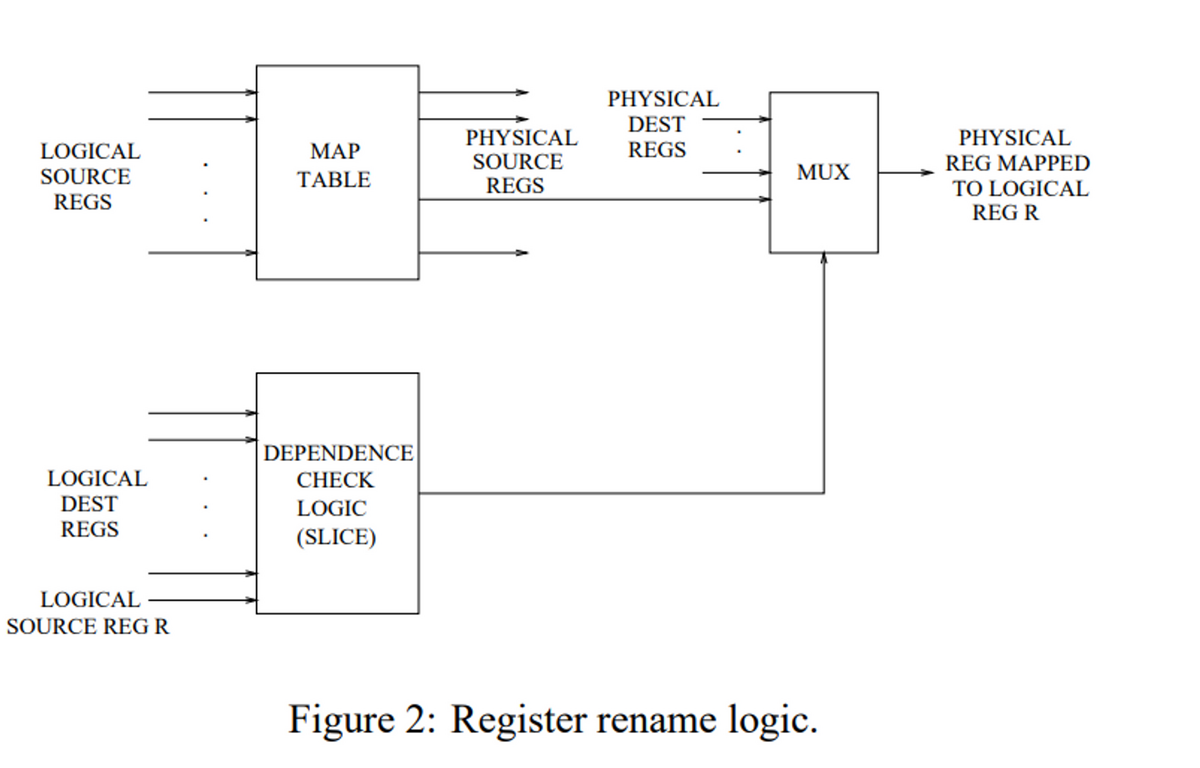
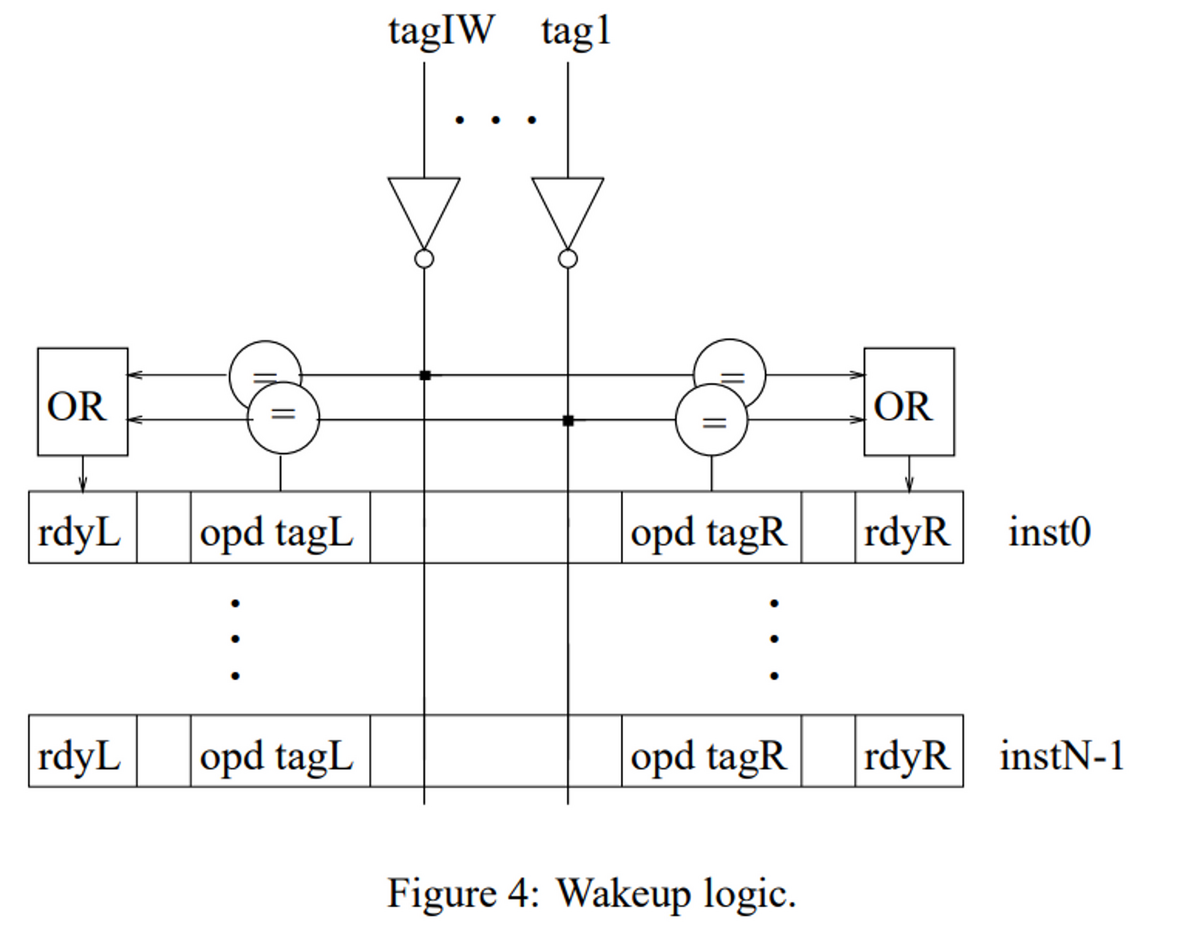
- Wakeup論理
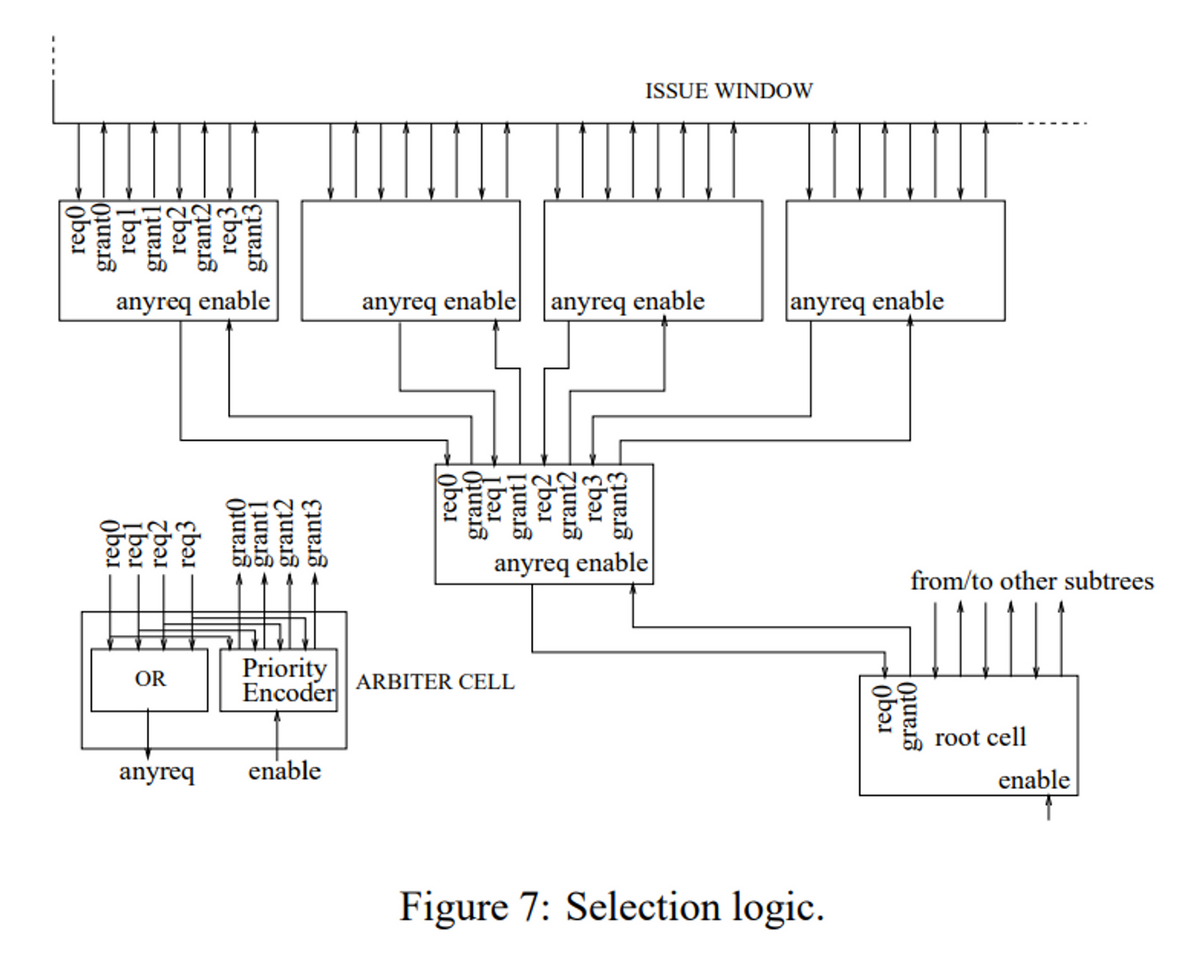
- Selection論理
- Wakeup論理にて発行可能な命令から、実際に発行する命令を選択する
- 発行可能な命令から、発行するパイプライン(Functional Unit: FU)への選択信号を挿入し、プライオリティ・エンコーダにて適切な命令を選択する
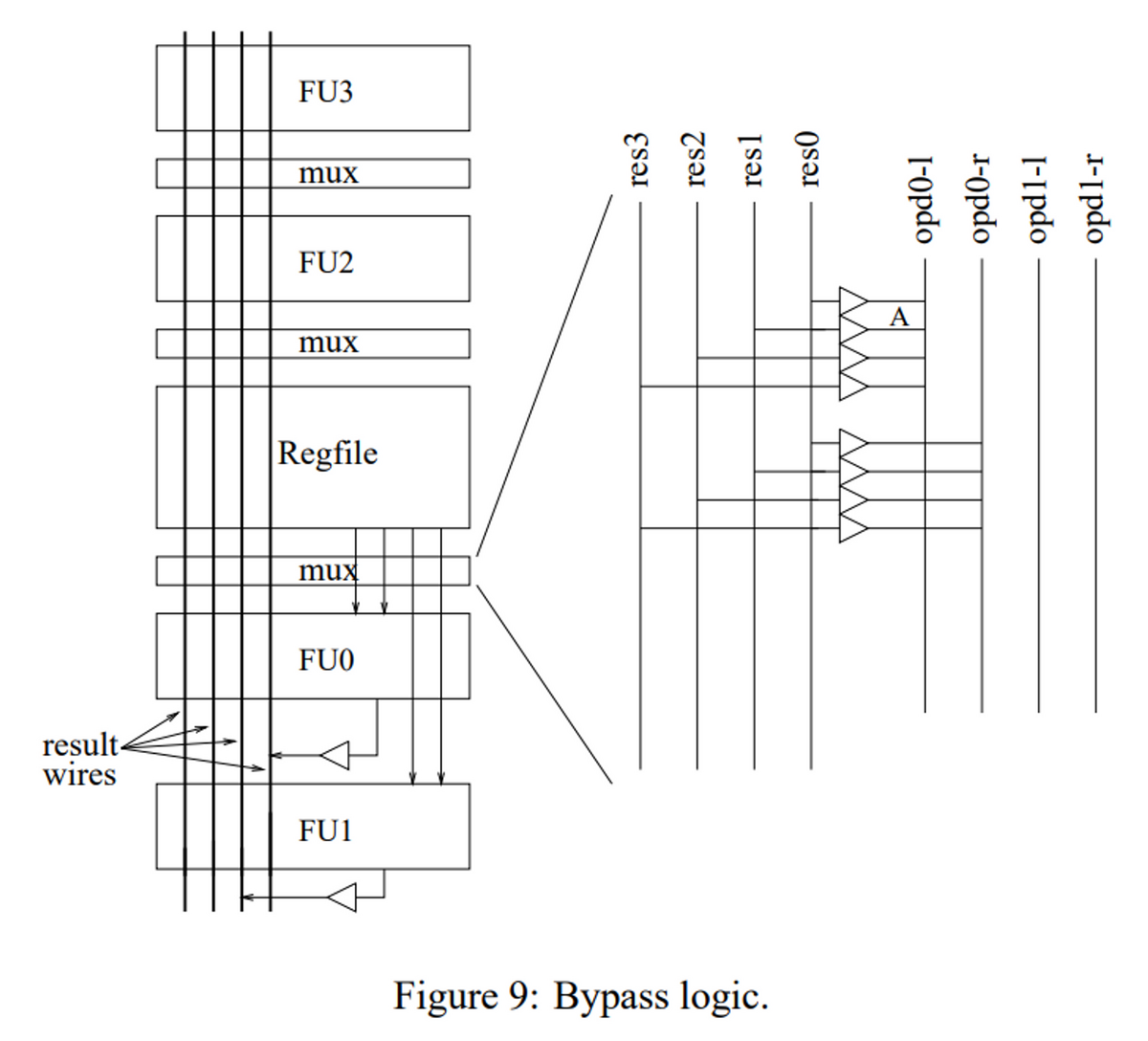
- バイパス論理
全体として、それぞれのユニットの遅延をリストアップすると、以下のようになる。ここでポイントとなるのは、Wakeup+Select論理が最も大きいということで、ここの遅延を削減することがポイントになる。
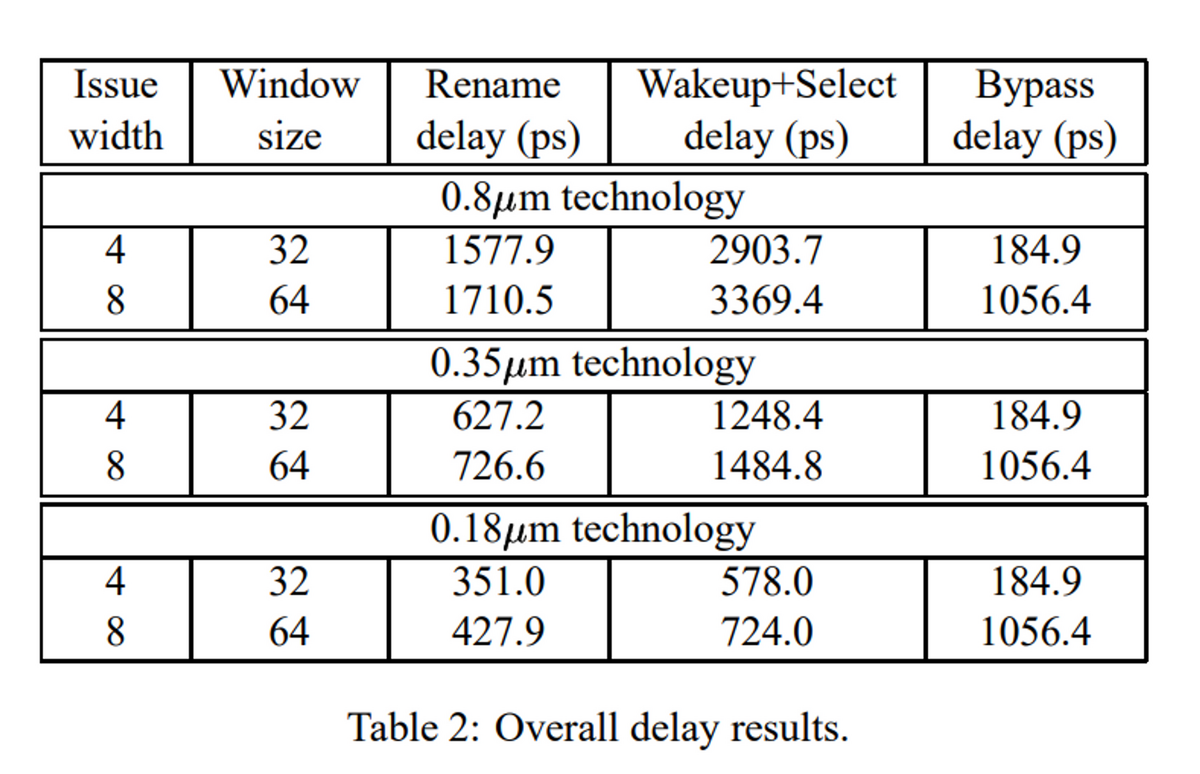
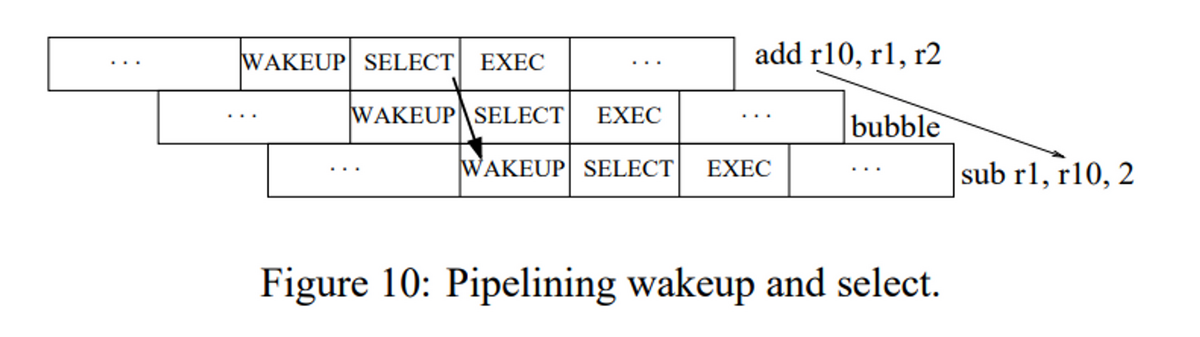
個々のWakeup+Selectの論理はパイプラインで分割することはできなくて、これを分割するといぞする命令のWakeupが1サイクル空いてしまい、性能に影響を与えてしまうからである。以下がその例である。add r10, r1, r2とsub r1, r10, 2の依存は、Wakeup+Selectの論理に1サイクル消費するとそれだけで1命令分のバブルが必要となる。
そこで、ここの命令発行部分を簡略化して、複数の分散したFIFOとして構成することを提案する。
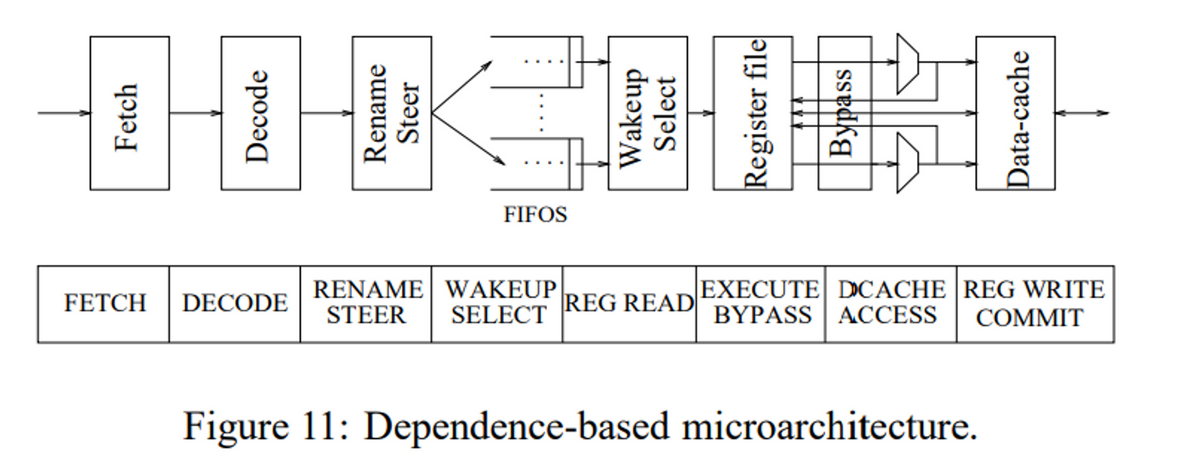
依存のある命令同士を同じFIFOに挿入することで、同時に発行されることのない命令同士で依存関係をチェックする必要をなくす。また、FIFOの先頭のみ依存関係をチェックする論理を挿入することで、Wakeupの論理を削減する。
これにより、性能は若干低下する。
FIFOの先頭の命令のみ依存関係を解析するため、Reservation Tableを使用して、物理レジスタ番号がReady状態になっているかを監視する。このためには、物理レジスタ番号の数だけビットを用意し、発行された命令が、計算結果を生成するたびにReservation Tableを更新する。FIFOの先頭の命令は、自分が必要なオペランドの物理レジスタ番号がReservation TableでReady状態になっているのかを確認し、すべてのオペランドがReady状態であれば発行する。
次に、マイクロ・アーキテクチャ全体のクラスタ化を考える。上記のアイデアにより命令発行部を簡略化することは可能だが、命令の発行幅を倍増して8命令発行にすると、依然として動作周波数が悪くなる。
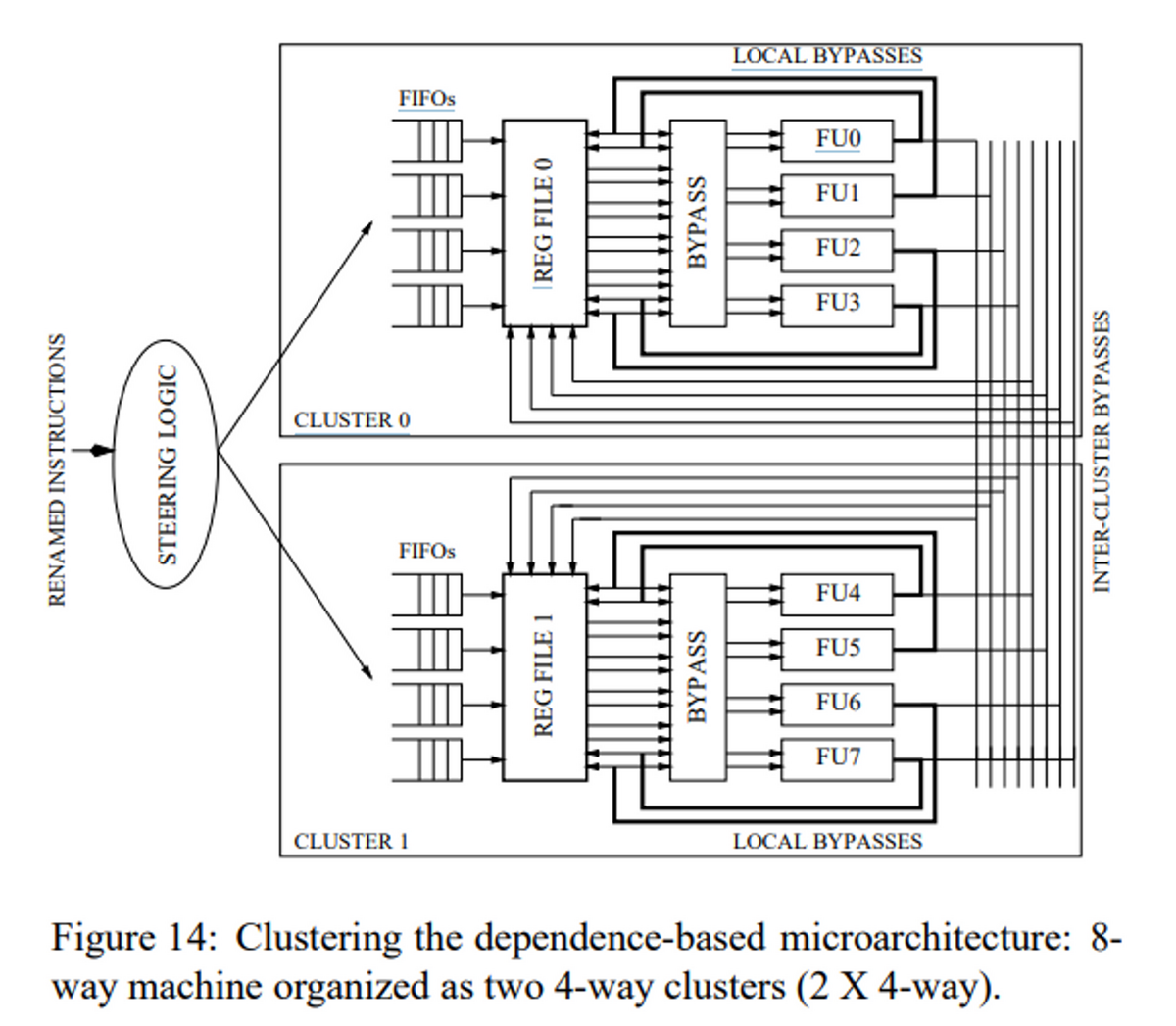
そこで、8命令発行部を4命令発行x2にクラスタ化することにより、命令発行部をシンプルに保ち、命令発行幅を増やすことを考える。
各クラスタは4つのFIFOを持っており、1つのレジスタ・ファイルのコピーと、4つのFUが含まれている。同一クラスタ内であれば、計算結果をすぐにFUにバイパスすることができるが、別のクラスタ間のバイパスには1サイクルを要する。
レジスタファイルは、各クラスタにコピーを持っているが、これの更新はバイパスユニットと同様に行われ、クラスタを跨ぐレジスタの書き込みには、さらに1サイクルが必要になる。
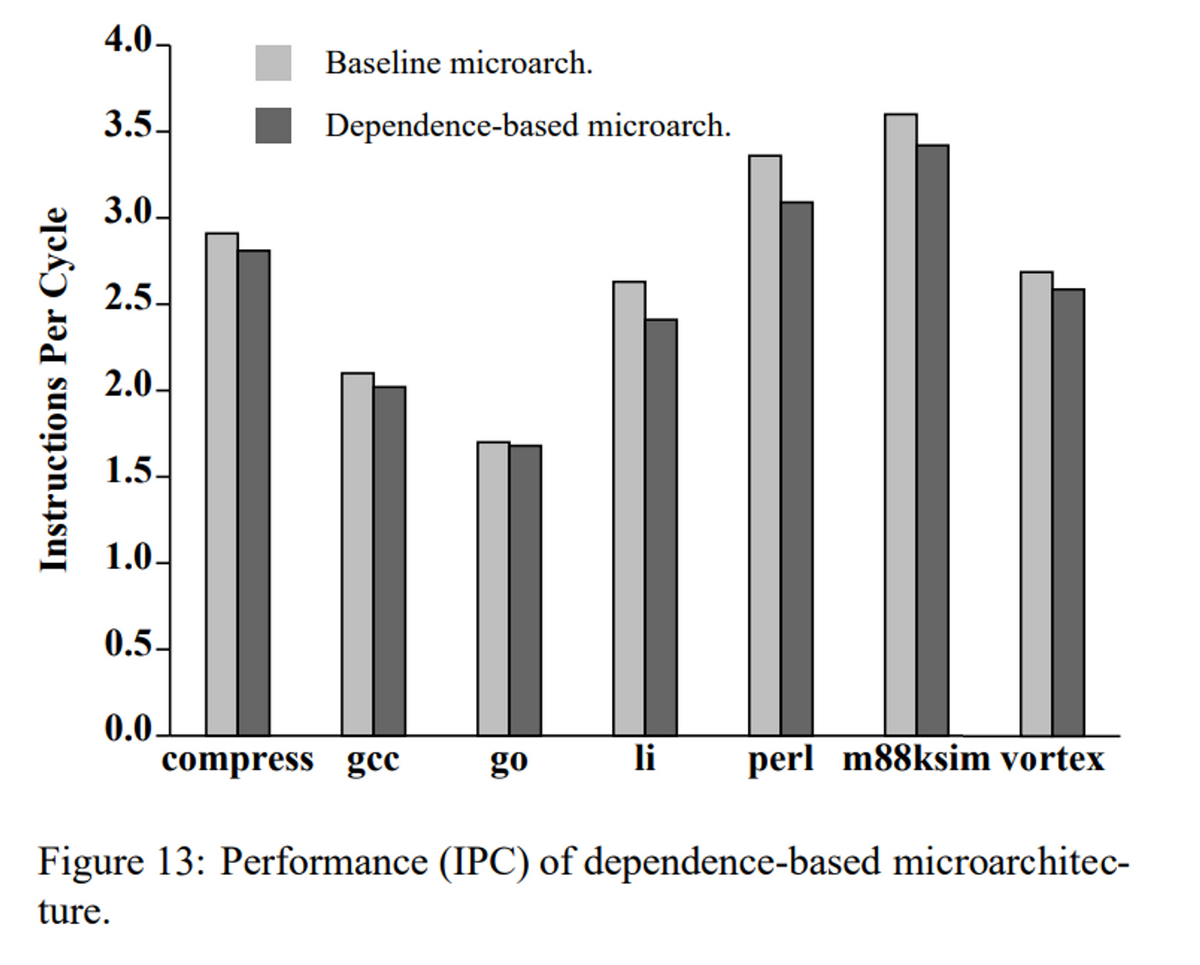
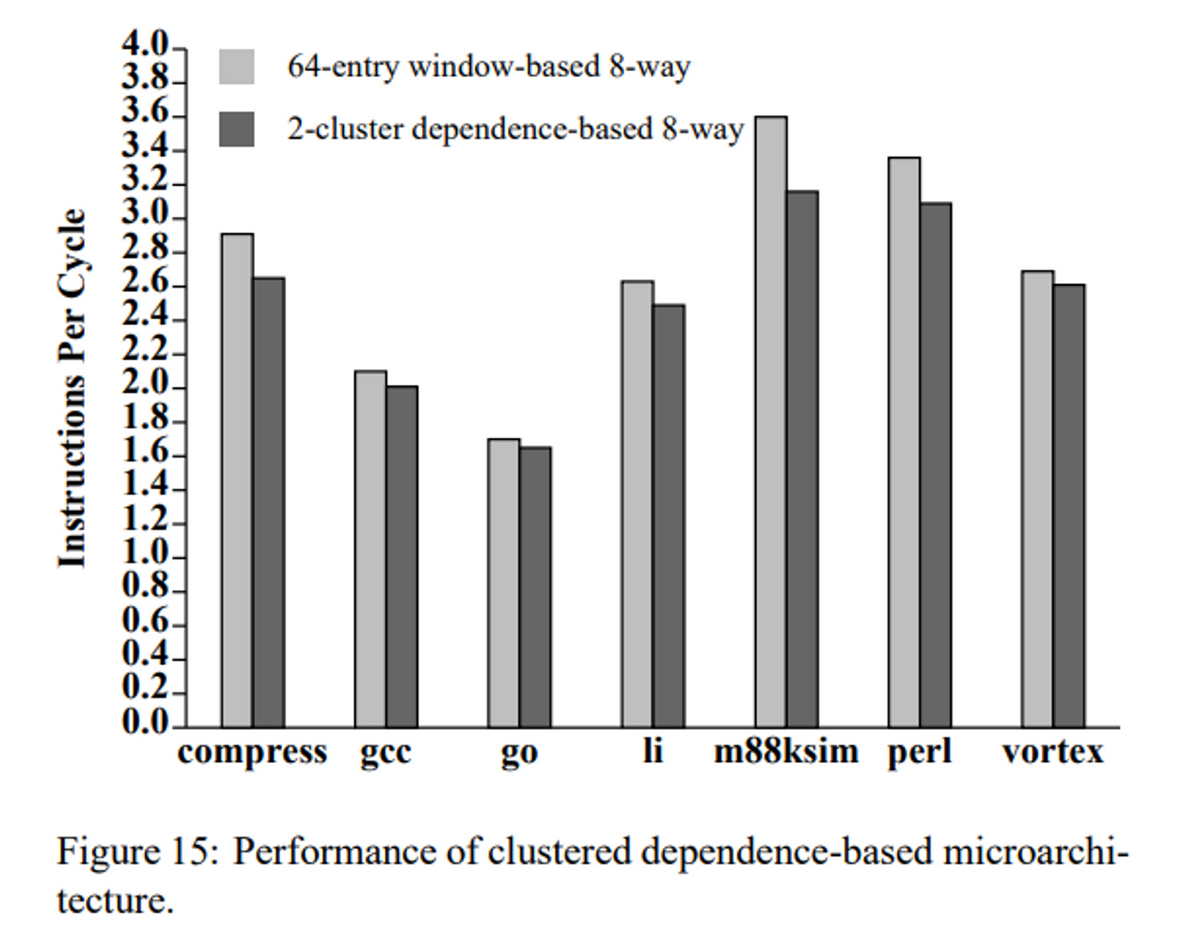
以下が、8命令発行かつ2つのクラスタを用意した場合の性能比較となる。ベースに対して、わずかに性能が低下する。
まとめ:
スーパ・スカラ・プロセッサにおいて、より命令発行幅が広くなることにより配線遅延が大きくなるという観点に基づき、命令発行幅を大きくしても遅延が小さくならないDependence-Basedマイクロ・アーキテクチャを提案した。
2x4-wayのDependence-Basedのマイクロ・アーキテクチャの性能を、8-wayスーパースカラと比較した。その結果、2つのことがわかった。