自作CPUの命令発行スケジューラをMatrix Schedulerに置き換えたくて、論文を読み直している。
Matrix Schedulerは行列のサイズが、命令ウィンドウの数だけ必要 (ROB 32エントリ x 5命令だと160x160くらいの行列が必要?) というのが基本だと思っていて、これを削減するためにIntelのMatrix Scheduler Reloadedを読み直している。
https://dl.acm.org/doi/10.1145/1250662.1250704
Abstract
- スケジューラは大規模でシングルサイクルにする必要がある
- Matrixスケジューラの実装に2つの簡単な変更を加える
- ウェイクアップ行列とピッカー行列は小さいサイズでも疎である
- 小さなインダイレクトテーブルを使用して、行列の幅とレイテンシを大幅に削減する
- 性能の改善
- クリティカルパスを17〜58%短縮
- IPCを7〜26%向上
追加ハードウェアの増加分は、Matrixの縮小とCAMの機能を削減することにより相殺される
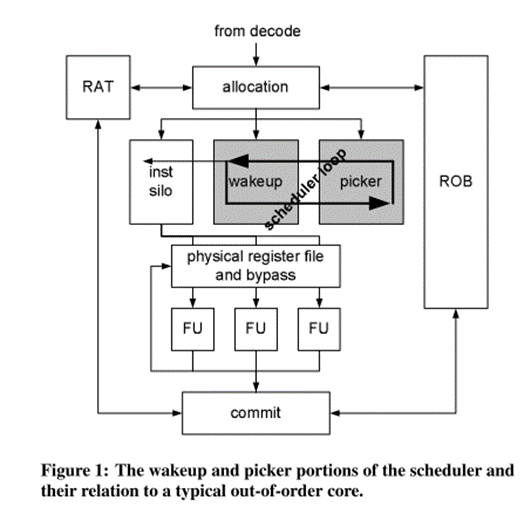
スケジューラの構成
- Wakeup側 : データフローのオーダリングを担当
- Picker側 : リソースの割り当てとAgeトラッキングを担当
スケジューラによる性能律速
Wakeup側の拡張
- オンデマンドで演算を消費することで、Wakeup Matrixの列を予約する
- 大規模なスケジューラでも、20個程度のブロードキャストを追跡するだけで良い
- Picker側の拡張
- 行列サイズを大幅に縮小するためのインダイレクト技術
- すべての命令ではなく、12個のグループを追跡する
- 全体として、Matrixスケジューラのループ遅延を17~58%短縮できると推定される
- 遅延を従来の設計と同じにすると、7~26%性能を向上させることができる
2. Wakeup
2.1 Background Wakeup Matrix
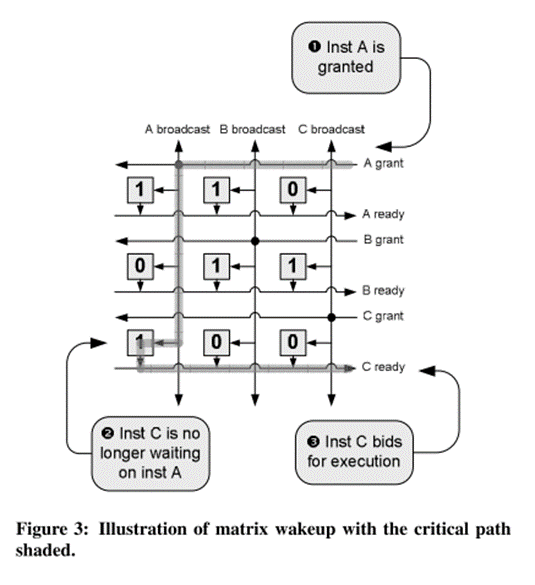
- 1命令につきMatrixの1行と1列を消費する
- 各行に対応する命令が、どの列に割り当てられている命令に依存しているかを示す
- 対応する行がその結果タグを生成する
- 命令が準備完了になると、その命令の列をクリアする (当該列のすべてのビットを0にする)
- この方式は行列が𝑁2となるため、大規模スケジューラを実装するのは困難
- 既存手法の解決策
- Dataflow prescheduling / Dependence Collapsing
- どちらも、複雑な解析による電力消費が必要となる
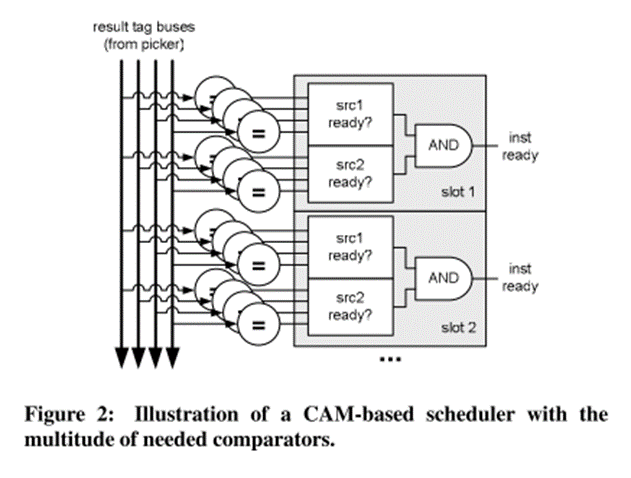
- CAMベースの場合 : Tag除去
- 2つのソースオペランドをWakeupすることはまれ
- コンパレータの数を削減する
- Dataflow prescheduling / Dependence Collapsing
2.2 Wasted Broadcasts
- Matrixは、情報密度が非常に低い
- 依存関係は、通常10~20程度しか使用されていない
- 命令を3つのカテゴリに分けて分析した
- Broadcast命令
- 命令がBroadcastを生成し、それをListenしているConsumerが存在している
- Broadcast Wait命令
- 命令がBroadcastを生成するが、それをListenするConsumerが存在していない
- No Broadcast命令
- リネームされたDestinationを生成しない
- 分岐命令、ストア命令、制御命令
- Broadcast命令
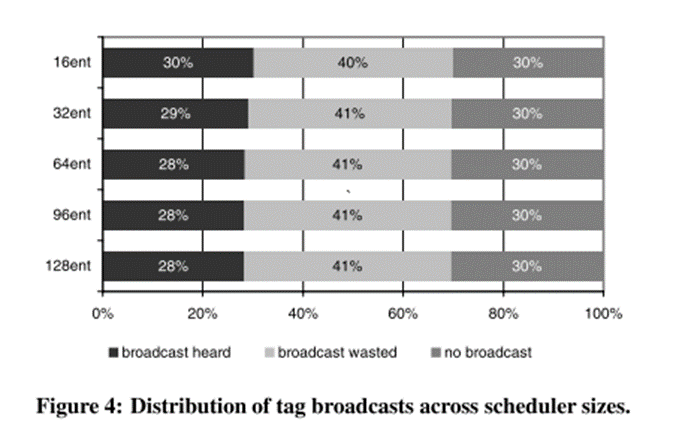
- 図4. スケジューラのサイズを変えて、ブロードキャストの状態を表示したもの
- 無駄なブロードキャスト・ブロードキャスト無し : 70~71%
- 殆どの命令はブロードキャストが必要ない
- ブロードキャストからWakeupに必要な通信チャネル数が多くないというのも納得できる