RISC-VのアウトオブオーダコアであるBOOM (Berkely Out-of-Order Machine) について勉強を進めている。以下のドキュメントを日本語に訳しながら読んでいくことにした。
グローバルヒストリレジスタ(GHR)の管理
Global History Register (GHR)は、分岐予測器の重要な部分です。 これは、前の N 個の分岐の結果を含んでいます(ここで、Nは GHRのサイズです)。12
ブランチ i をフェッチする際には、正確な予測ができるように、前の i-N 個のブランチの方向性が利用できることが重要です。 コミット 段階まで待って GHRを更新するのでは遅すぎます(何十ものブランチが飛んでいるのに反映されていません!)。 したがって、分岐がフェッチされて予測されると、 GHRを 投機的に 更新しなければなりません。
予測ミスが発生した場合は、 GHR をリセットして、 実際の履歴を反映するように更新しなければなりません。 つまり、各分岐命令(より正確には、各 フェッチパケット )は、 予測が外れた場合に備えて GHRをスナップショットを取らなければなりません。13
最後にもう1つ、例外的なパイプラインの動作があります。 各分岐には GHRのスナップショットが含まれていますが、 どの命令も フロントエンド リダイレクトの原因となる例外を発生させる可能性があります。 このようなイベントは、 GHRが破損する原因となります。 例外については、これは許容できると思われるかもしれません - 例外はまれであるべきで、 トラップハンドラは(ユーザーコードの観点から)いずれにしても GHRの汚染を引き起こします。 しかし、例外的なイベントとして”パイプライン再実行”があります。 これは、ある命令がパイプライン・フラッシュを引き起こし、 その命令がリフェッチされて再実行されるイベントです。14 このため、 GHRの コミットコピー はBPDによっても維持され、 あらゆる種類のパイプライン・フラッシュ・イベントでリセットされます。
分岐予測のためのフェッチターゲットキュー(FTQ)
リオーダバッファ( リオーダバッファ (ROB) とディスパッチステージ 参照)は、すべてのインフライト命令の記録を保持します。 同様に、FTQは、すべてのインフライトの分岐予測とPC情報の記録を保持します。 これらの2つの構造は、FTQのエントリが非常に高価であり、 すべてのROBエントリに分岐命令が含まれるわけではないため、切り離されています。 また、ROBのすべてのエントリに分岐命令が含まれているわけではありません。 分岐命令は6つの命令のうちおよそ1つだけなので、FTQはROBよりもエントリ数を少なくして、 さらなる節約を図ることができます。
各FTQエントリーは、1 フェッチ サイクルに対応します。 予測を行うたびに、分岐予測器は後で更新を行う際に必要となるデータをパックアップします。 例えば、分岐予測器は、予測がどの インデックス から来たかを覚えておき、 後でそのインデックスのカウンターを更新できるようにします。 このデータは、FTQに格納されます。
term:Fetch Packet の最後の命令がコミットされると、FTQのエントリは解放され、 分岐予測器に戻されます。FTQエントリに格納されたデータを使用して、 分岐予測器はその予測状態に対して任意の所望の更新を行うことができます。
コミット の後に分岐予測器を更新する理由はいくつかあります。 予測器が 正しい 情報だけを学習することは非常に重要です。 データキャッシュでは、間違ったパスの実行からフェッチされたメモリは、 後の実行が別のパスになったときに最終的に役に立つかもしれません。 しかし、分岐予測器では、間違ったパスの更新は、純粋な汚染である情報をエンコードします。 つまり、有用ではなく、決して有用ではない情報を保存することで、有用なエントリを占有してしまうのです。 後のイテレーションで別のパスを取ることになっても、そこに至るまでの履歴は異なります。 最後に、キャッシュは完全にタグ付けされていますが、分岐予測器は(もしあれば)部分的なタグを使用するため、 脱構築的なエイリアシングに悩まされることになります。
もちろん、フェッチ と コミット の間のレイテンシーは不便ですし、 複数のループイテレーションが行われている場合には、余計な分岐予測が発生する可能性があります。 しかし、FTQを使えば、 分岐予測をバイパスしてこの問題を軽減することができます。 現在、BOOMではこのバイパス動作はサポートされていません。
リネームスナップショットステート
FTQ を正しい値にリセットする必要があります。
この状態は非常に高価なものですが、 実行 ステージで分岐が解決されると、解放することができます。 したがって、この状態は 分岐りネームスナップショット と並行して保存されます。 デコード と リネーム の間、各分岐に 分岐タグ が割り当てられ、 予測違いが発生した場合に1サイクルでロールバックできるように、 リネームテーブルのスナップショットが作成されます。 分岐タグと リネームマップテーブル のスナップショットと同様に、 対応するBranch Rename Snapshotは、実行 の分岐ユニットでブランチが解決されると、割り当て解除されます。

Fig. 9 Branch Predictor Pipeline(分岐予測パイプライン)。シンプルな図ですが、Branch Prediction Pipeline内のI/Oを示すのに役立ちます。フロントエンドは、 F0 ステージのパイプラインに「次のPC」 ( req と表示 )を送ります。 “Abstract Predictor”の中では、”Abstract Predictor”のラッパーによってハッシュが管理されます。 “Abstract Predictor”は、”BPD(Backing Predictor)”レスポンス、つまり “フェッチパケット “内の各命令に対する予測を返します。
抽象分岐予測器クラス
さまざまなグローバルヒストリベースのBPDデザインの検討を容易にするために、 抽象的な “BrPredictor” クラスが提供されます。 このクラスは、BPDとグローバルヒストリレジスターを管理するための制御ロジックへの標準的なインターフェースを提供します。 この抽象クラスは Fig. 9 の中にある “Abstract Predictor” という名前のクラスです。 分岐予測器の詳細や例については、 gshire-predictor-pipeline を参照してください。
グローバルヒストリ
グローバルヒストリレジスタの管理 で説明したように、 グローバルヒストリは分岐予測器の重要な要素です。 そのため、抽象クラスである BranchPredictor クラスで処理されます。 抽象クラスである BranchPredictor を拡張するすべての分岐予測器は、 スナップショット、アップデート、バイパスを処理することなく、グローバルヒストリにアクセスすることができます。
オペレーティングシステムを意識したグローバルヒストリ
その効果についてのデータは予備的なものですが、 BOOMはOSを意識したグローバルヒストリをサポートしています。 通常のグローバルヒストリは、すべての権限レベルのすべての命令を追跡します。 2つ目の ユーザーのみのグローバルヒストリ は、ユーザーレベルの命令のみを追跡します。
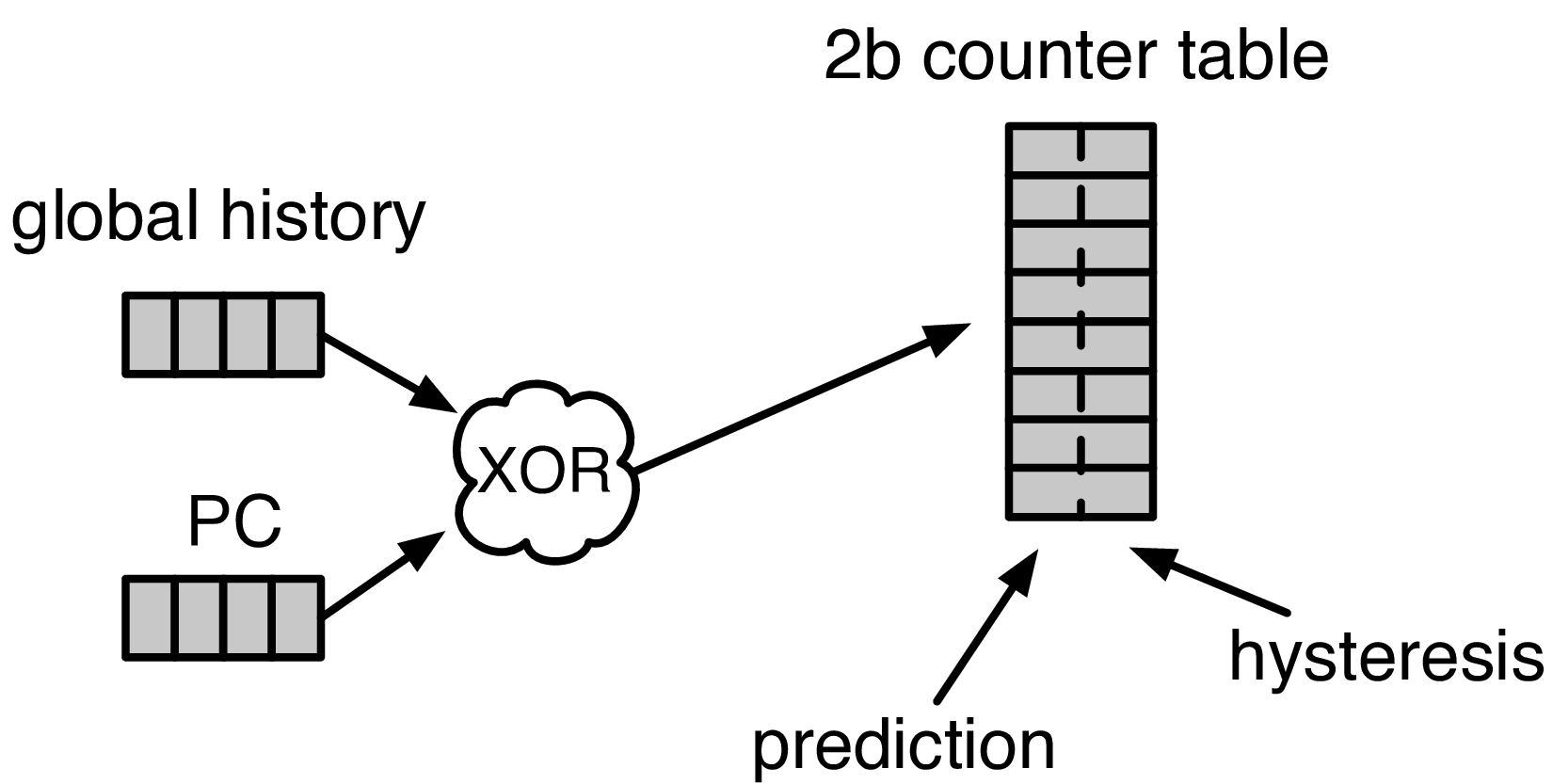
2ビットカウンタテーブル
ほとんどの分岐予測器の基本的な構成要素は、”2ビットカウンターテーブル”(2BC)です。 特定の分岐が繰り返し実行されると、カウンターは最大値の3(0b11)、 つまり”強く実行された”状態にまで飽和します。 同様に、繰り返し取られていないブランチは、0に向かって飽和していきます(0b00)。 上位のビットは”予測”を、低次のビットは”ヒステリシス”(予測の”強さ”)を指定します。
 ](https://docs.boom-core.org/en/latest/_images/2bc-prediction.png)
](https://docs.boom-core.org/en/latest/_images/2bc-prediction.png)
Fig. 10 A GShare Predictor uses the global history hashed with the PC to index into a table of 2-bit counters (2BCs). The high-order bit makes the prediction.
これらの2ビットのカウンターはテーブルに集約されます。 理想的には、優れた分岐予測器は、どのカウンターにインデックスを付ければ最良の予測ができるかを知っています。 しかし、これらの2ビットカウンタを高密度のSRAMに収めるために、2BC有限状態機械に変更が加えられます。 すなわち、 弱い分岐不成立 状態で行われた予測の間違いは、2BCを強い分岐成立状態に移動させます( 弱い分岐成立 が予測の間違いの場合はその逆)。 この FSM の動作は Fig. 11 に示されています。
もはや厳密には”カウンター”ではありませんが、この変更により、 prediction ビットと hystersis ビットの読み取りと書き込みの要件を分離し、 それらを別々のシーケンシャルメモリテーブルに配置することができます。 ハードウェアでは、2BCテーブルは次のように実装できます。
Pビット: * Read - 毎サイクル予測を実行する * Write - 分岐予測に失敗したときのみ(h-bitの値)
Hビット:
- Read - 分岐予測に失敗したときのみ
- Write - 分岐が解決したとき (分岐の方向を書き込む)

Fig. 11 The Two-bit Counter (2BC) State Machine
高次のpビットと低次のhビットを分離することで、 それぞれを1リード/1ライトのSRAMに配置することができます。 さらにいくつかの仮定を設けることで、より良い結果を得ることができます。 予測を誤ることは稀であり、分岐の解決がすべてのサイクルで行われるとは限りません。 また、書き込みが遅れたり、完全に取りこぼしたりすることもあります。 そのため、書き込みをキューに入れておき、読み出しが行われていないときに書き込みを排出することで、 1つの1RWポートのSRAMを使って hテーブル を実装することができます。 同様に、 p-table は、書き込みをバッファリングし、 読み取りが競合していないときにドレインすることで、1RWポートのSRAMを使って実装することができます。
最後に、SRAMは、2BCテーブルが必要とする”背が高くて背が低い”アスペクト比に満足していません。 しかし、解決策は簡単です。”背が高くて背が低い”、長方形のメモリ構造に簡単に変換できます。 インデックスの高次ビットはSRAMの行に対応し、 低次ビットは行内の特定のビットを取り出すために使用することができます。