QEMUのRustでの再実装、どうにも最適化の方向が良く分からなくなってきた。そこで一度立ち戻ってQEMUがどのような方式でTCGを高速化しているのかを確認してみることにする。
そもそもの疑問は、QEMUを-d in_asmで実行していると途中でログの生成が止まってしまうということだ。明らかに処理が進んでいるのだが、ログは生成されないという謎があった。これについて調査していこうと思う。
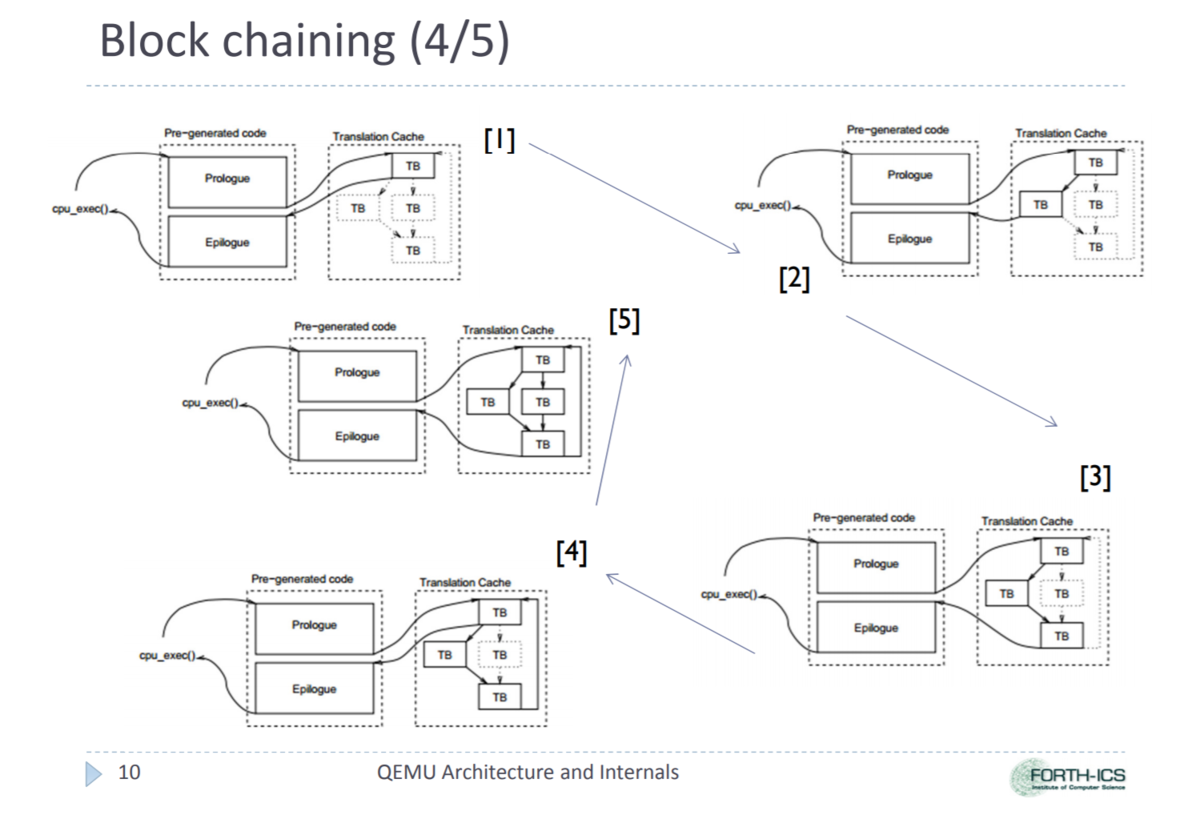
QEMUのTCG同士をつなげる仕組み
QEMUはゲスト命令をTCGを通じてホスト命令に変換している。ホスト命令の1ブロックを実行し終えると、いったんホスト側に戻って次のブロックを探索して再度実行を開始する。しかし、これでは効率が悪いので、すでに生成されているブロックについては直接ジャンプしてしまうのが良い。これを実現するために、生成されたx86命令に対して後でパッチを当てる操作が実行されている。
一つの例を出してみる。RISC-Vの以下の命令がTCGに変換されてx86で実行される。
IN: _start Priv: 3; Virt: 0 0x0000000080000212: 00033023 sd zero,0(t1) 0x0000000080000216: 0321 addi t1,t1,8 0x0000000080000218: fe734de3 bgt t2,t1,-6 # 0x80000212
0x7f119c001c80: 8b 5d f0 movl -0x10(%rbp), %ebx [tb header & initial instruction] 0x7f119c001c83: 85 db testl %ebx, %ebx 0x7f119c001c85: 0f 8c 89 00 00 00 jl 0x7f119c001d14 0x7f119c001c8b: 33 db xorl %ebx, %ebx 0x7f119c001c8d: 4c 8b 65 30 movq 0x30(%rbp), %r12 0x7f119c001c91: 49 8b fc movq %r12, %rdi 0x7f119c001c94: 48 c1 ef 07 shrq $7, %rdi 0x7f119c001c98: 48 23 7d e0 andq -0x20(%rbp), %rdi 0x7f119c001c9c: 48 03 7d e8 addq -0x18(%rbp), %rdi 0x7f119c001ca0: 49 8d 74 24 07 leaq 7(%r12), %rsi 0x7f119c001ca5: 48 81 e6 00 f0 ff ff andq $0xfffffffffffff000, %rsi 0x7f119c001cac: 48 3b 77 08 cmpq 8(%rdi), %rsi 0x7f119c001cb0: 49 8b f4 movq %r12, %rsi 0x7f119c001cb3: 0f 85 67 00 00 00 jne 0x7f119c001d20 0x7f119c001cb9: 48 03 77 18 addq 0x18(%rdi), %rsi 0x7f119c001cbd: 48 89 1e movq %rbx, (%rsi) 0x7f119c001cc0: 49 8d 5c 24 08 leaq 8(%r12), %rbx [guest addr: 0000000080000216] 0x7f119c001cc5: 48 89 5d 30 movq %rbx, 0x30(%rbp) 0x7f119c001cc9: 4c 8b 65 38 movq 0x38(%rbp), %r12 [guest addr: 0000000080000218] 0x7f119c001ccd: 49 3b dc cmpq %r12, %rbx 0x7f119c001cd0: 0f 8c 1e 00 00 00 jl 0x7f119c001cf4 0x7f119c001cd6: 90 nop 0x7f119c001cd7: e9 00 00 00 00 jmp 0x7f119c001cdc 0x7f119c001cdc: bb 1c 02 00 80 movl $0x8000021c, %ebx 0x7f119c001ce1: 48 89 9d 28 06 00 00 movq %rbx, 0x628(%rbp) 0x7f119c001ce8: 48 8d 05 d2 fe ff ff leaq -0x12e(%rip), %rax 0x7f119c001cef: e9 24 e3 ff ff jmp 0x7f119c000018 0x7f119c001cf4: 66 66 90 nop 0x7f119c001cf7: e9 00 00 00 00 jmp 0x7f119c001cfc 0x7f119c001cfc: bb 12 02 00 80 movl $0x80000212, %ebx 0x7f119c001d01: 48 89 9d 28 06 00 00 movq %rbx, 0x628(%rbp) 0x7f119c001d08: 48 8d 05 b1 fe ff ff leaq -0x14f(%rip), %rax 0x7f119c001d0f: e9 04 e3 ff ff jmp 0x7f119c000018 0x7f119c001d14: 48 8d 05 a8 fe ff ff leaq -0x158(%rip), %rax 0x7f119c001d1b: e9 f8 e2 ff ff jmp 0x7f119c000018
分岐命令に相当する部分について抽出してみる。ホスト命令において分岐に関連する命令は以下である。
0x7f119c001ccd: 49 3b dc cmpq %r12, %rbx 0x7f119c001cd0: 0f 8c 1e 00 00 00 jl 0x7f119c001cf4 0x7f119c001cd6: 90 nop 0x7f119c001cd7: e9 00 00 00 00 jmp 0x7f119c001cdc 0x7f119c001cdc: bb 1c 02 00 80 movl $0x8000021c, %ebx 0x7f119c001ce1: 48 89 9d 28 06 00 00 movq %rbx, 0x628(%rbp) # 戻り値: 0x7F119C001BC0 0x7f119c001ce8: 48 8d 05 d2 fe ff ff leaq -0x12e(%rip), %rax # ホストに戻る 0x7f119c001cef: e9 24 e3 ff ff jmp 0x7f119c000018 0x7f119c001cf4: 66 66 90 nop # 単純に次の命令に移るための命令が挿入されている 0x7f119c001cf7: e9 00 00 00 00 jmp 0x7f119c001cfc 0x7f119c001cfc: bb 12 02 00 80 movl $0x80000212, %ebx 0x7f119c001d01: 48 89 9d 28 06 00 00 movq %rbx, 0x628(%rbp) # 戻り値: 0x7F119C001BBF 0x7f119c001d08: 48 8d 05 b1 fe ff ff leaq -0x14f(%rip), %rax # ホストに戻る 0x7f119c001d0f: e9 04 e3 ff ff jmp 0x7f119c000018 # 戻り値: 0x7F119C001BC2 0x7f119c001d14: 48 8d 05 a8 fe ff ff leaq -0x158(%rip), %rax # ホストに戻る 0x7f119c001d1b: e9 f8 e2 ff ff jmp 0x7f119c000018
この時、0x7f119c001cf7に注目すると、単純に次の命令にジャンプするための命令が挿入されている。実は、次にジャンプするTCGのメモリアドレスが決定された段階で、この命令が置き換えられて次のブロックに直接ジャンプする命令が挿入されることになる。
置き換え後の命令は以下のようになっていた。
... 0x7f8c5c001ce8: 48 8d 05 d2 fe ff ff leaq -0x12e(%rip), %rax 0x7f8c5c001cef: e9 24 e3 ff ff jmp 0x7f8c5c000018 0x7f8c5c001cf4: 66 66 90 nop # 0x7f8c5c001c80にジャンプする命令に置き換えられる # 0x7f8c5c001c80はこのブロックの先頭、つまり、このブロックを何度も実行する命令が完成する 0x7f8c5c001cf7: e9 84 ff ff ff jmp 0x7f8c5c001c80 0x7f8c5c001cfc: bb 12 02 00 80 movl $0x80000212, %ebx 0x7f8c5c001d01: 48 89 9d 28 06 00 00 movq %rbx, 0x628(%rbp) 0x7f8c5c001d08: 48 8d 05 b1 fe ff ff leaq -0x14f(%rip), %rax 0x7f8c5c001d0f: e9 04 e3 ff ff jmp 0x7f8c5c000018 0x7f8c5c001d14: 48 8d 05 a8 fe ff ff leaq -0x158(%rip), %rax ...
これにより、ホストに戻すことなく常にエミュレーションを実行することができるようになっていることが分かった。これをTCGのBlock Chainingと言うらしい。なるほど、上手くできている。