"The MIPS R10000 Superscalar Microprocessor" の論文をもう一度読み直してみている。
1. 概要
MIPS R10000 は、シリコン・グラフィックス社 (Silicon Graphics, Inc.) によって開発された 64 ビットスーパースカラマイクロプロセッサである。動的アウトオブオーダ実行機能を備え、MIPS IV 命令セットアーキテクチャを実装しており、複雑な実アプリケーションにおいて高いパフォーマンスを発揮するよう設計されている。
主要な特徴
- アウトオブオーダ・スーパースカラ: キャッシュミスによる停止を回避し、先行命令を継続的に実行することでレイテンシを隠蔽する。
- MIPS IV ISA の 64 ビット実装: フル 64 ビットの命令セットを実現。
- 高帯域幅の命令フェッチ: サイクルあたり 4 命令をフェッチ・デコードし、5 本の低レイテンシ実行ユニットへ発行する。
- 投機的実行: 分岐予測を用いた投機的フェッチと実行を可能とする。
- 順序通りのグラデュエーション: 実行はアウトオブオーダだが、完了は順序通りに処理される。
- 正確な例外処理とメモリ一貫性: シーケンシャルメモリ一貫性と正確な例外を保証。
- 階層型ノンブロッキングキャッシュ: 2 レベルのライトバックキャッシュによりメモリレイテンシを軽減。
- モジュラーデザイン: アクティブリスト、レジスタマップテーブル、命令キューを規則的構造に組み込み、設計の複雑さを軽減。
- 製造技術: 0.35μm CMOS 技術、680 万トランジスタ (うち 440 万はキャッシュアレイ)、ダイサイズ 16.64 × 17.934 mm。
2. 設計理念
R10000 はメモリ帯域幅およびレイテンシが性能を律することを前提に設計された。
- レジスタマッピングとノンブロッキングキャッシュ: キャッシュミス中でも他命令を継続実行可能とし、リソース効率を最大化する。
- 動的命令リオーダ: オペランドの準備状況に基づき実行順を変更し、キャッシュミス時も即座に適応する。
- 命令ウィンドウ: 最大 32 命令を先読みし並列実行機会を探索、セカンダリキャッシュレイテンシをほぼ隠蔽する。
3. パイプラインと命令実行
R10000 は 6 本の独立パイプラインを備える。
- 整数パイプライン × 2 (レイテンシ 1)
- 浮動小数点パイプライン × 2 (レイテンシ 2–3)
- ロード・ストアパイプライン × 2 (レイテンシ 1–2)
Figure.2 にそれぞれのパイプラインが図示されている。
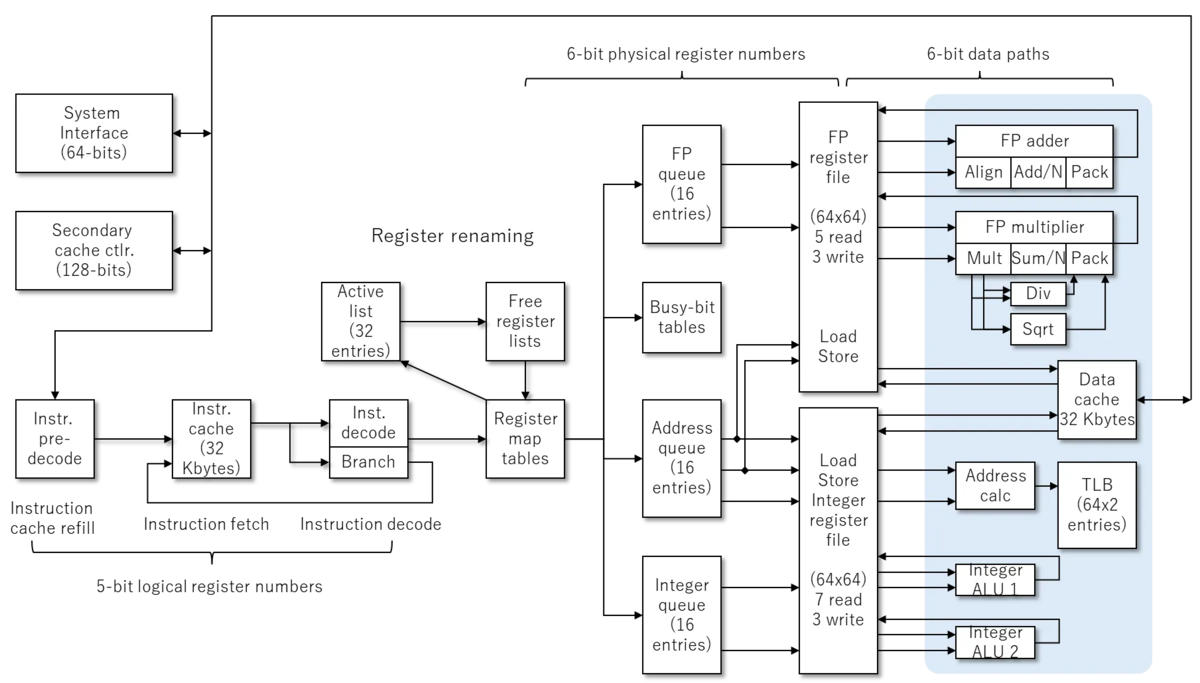
- 浮動小数点パイプライン1
- FPキュー(16エントリ)に格納され、発行されるとFPレジスタファイルにアクセスする。2つのデータを読み込んで、FP adderに渡され、その結果をFPレジスタに書き込む
- 浮動小数点パイプライン2
- FPキュー(16エントリ)に格納され、発行されるとFPレジスタファイルにアクセスする。2つのデータを読み込んで、FP multiplierに渡され、その結果をFPレジスタに書き込む
- 浮動小数点メモリアクセス命令
- Address Queue (16エントリ) に格納され、FPレジスタファイルにアクセスしている(2ポート使われているが、これはなんで?)。その後、データキャッシュにアクセスしている。
- 整数メモリアクセス命令
- Address Queue (16エントリ) に格納され、整数レジスタファイルにアクセスしたのち、Address Calculationを行い、TLBにアクセスしている。
- 整数命令1
- Integer Queue (16エントリ) に格納され、整数レジスタファイルにアクセスしたのち、Integer ALU1に格納し、整数レジスタファイルに書き込む。
- 整数命令2
- Integer Queue (16エントリ) に格納され、整数レジスタファイルにアクセスしたのち、Integer ALU2に格納し、整数レジスタファイルに書き込む。