NVDLAの内部構造についてもう少し詳しく解析したいのだが、割としっかりと解説してあるページがあったので読み進めていこう。
参考ににしたのは以下。っていうかNVDLA本家のページである。
- Unit Description (NVDLA)
Unit Description — NVDLA Documentation
ブリッジDMA
概要
入力画像と、処理後の画像は外部DRAMに格納されているが、外部DRAMのバンド幅とレイテンシはNVDLAのMACアレイの性能を最大限に発揮するのには不十分である。したがってNVDLAはセカンダリオンチップSRAMのインタフェースと一緒に構成されている。
オンチップSRAMを活用するためには、NVDLAはデータを外部DRAMからSRAMへ移動する必要がある。ブリッジDMAはこの目的のために実装されたものである。ブリッジDMAは2つの独立したパスを持っており、データを外部DRAMから内部SRAMへ、データを内部SRAMから外部DRAMへ移動させることができる。両方のパスを同時に動かすことはできない。BDMAは外部メモリ間でのデータ移動や内部メモリ間でのデータ移動にも使用できる。
ブリッジDMAは2つのDMAインタフェースを持っており、それぞれ外部DRAMと内部SRAMに接続されている。それぞれのインタフェースはReadとWriteリクエストをサポートしている。どちらのインタフェースもデータ幅は512ビットであり、最大バースト長は4である。
キューブのデータを移動するため、BDMAはアドレスが飛んでいる複数のラインをフェッチするラインリピート機能をサポートしている。 これによりサーフェイスを構成できる。 また、BDMAは複数のレイヤの繰り返し転送をサポートする予定である。 これにより複数のラインをフェッチしてリピートすることにより複数のサーフェイスを構成し、キューブ形状を移動できる。
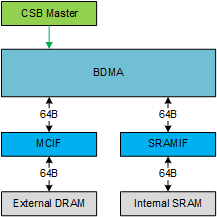
図39. ブリッジDMA
畳み込みパイプライン
概要
畳み込みパイプラインはNVDLAコア論理の中のパイプラインの1つである。これは畳み込みアルゴリズム高速化するために使用される。様々なサイズの畳み込みをサポートするためにプログラマブルなパラメータをサポートしている。WinogradやMulti-Batchといった手法を畳み込みパイプラインに適用し、MACの動作効率を向上させることができる。
畳み込みパイプラインは5つのステージを持っている。
- 畳み込みDMA
- 畳み込みバッファ
- 畳み込みシーケンスコントローラ
- 畳み込みMAC
- 畳み込みアキュムレータ
これらはそれぞれCDMA、CBUF、CSC、CMAC、CACCと呼ばれる。 各ステージは独自のCSBスレーブポートを持ち合わせており、制御CPUからコンフィグレーションデータを受け取ることができる。全てのステージでは同一クロックが使用される。
畳み込みパイプラインは3種類の操作をサポートしている。
- DCモード : 特徴データのダイレクトな畳み込み操作
- 画像入力モード : 入力画像の畳み込み
- Winogradモード : Winograd畳み込み
畳み込みパイプラインはint16およびfp16を実行できる1024個のMACを含んでおり、部分輪を格納するために32個のアキュムレータアレイを持っている。MACの資源は2048個のint8として構成することもできる。加えて、畳み込みバッファとして512KBのSRAMを持っており、このバッファから入力の重みとアクティベーションを読み込む。本ドキュメントの後半で、このユニットの詳細を説明する。
以下は畳み込みパイプラインのダイアグラムである。

ダイレクトな畳み込み
畳み込みパイプラインは、常に2種類の入力データを処理する。1つはアクティベーションデータ、もう1つは重みデータである。NVDLAは以下の入力パラメータを持っている。
- 特徴データキューブのサイズ:
- 1つの重みカーネルのサイズ:
- カーネルの数:
- ゼロパディングのサイズ: 左側の境界LP, 右側の境界RP, 上側の境界TP, 下側の境界BP
- 畳み込みストライド: X軸方向DX, Y軸方向DY
- 出力データキューブのサイズ

図41. 畳み込み操作
下記の図は畳み込みのストライドとゼロパディングを示したものである。
 図42. 畳み込みの
図42. 畳み込みのこれらのパラメータは以下の関係式を持つ:
出力データキューブ内の各エレメントと、入力特徴データキューブの各エレメント
と、重みカーネルの各エレメント
には以下の関係がある。
[tex: y{w, h, k} = \sum{r=0}^{R−1}\sum{s=0}^{S−1}\sum{c=0}^{C−1}x(wSX−LP+r),(hSY−TP+s) c} * wt{r,s, c,k}]
上記の式中に登場するはすべて0からスタートする。
上記の指揮の畳み込みを実行するために、畳み込みパイプラインはダイレクトな畳み込み(direct convolution)という手法を使用する。この手法のカギとなるアイデアは、各畳み込みカーネルの乗算の操作を、各グループが64個の乗算を含むようなグループに分割することである。基本的なルールは:
- 全てのMACユニットを16個のサブユニットに分割する。各サブユニットはMAC Cellと呼ばれ、64個のint16/fp16ハードウェアMACか、128個のint8ハードウェアMACを持っている。
- MAC Cellを複数構成することをMAC Cellアレイと呼ぶ。
- 全ての入力データキューブをint16, fp16, int8のための
個の小さなキューブに分割する。
- 全ての重みデータキューブをint16, fp16, int8のための
- 1つの小さな入力データキューブと1つの小さな重みデータキューブを掛け合わせ、累積する。これらの乗算と加算は1つのMAC cell上で行われる。
- 上記の計算操作を4つの演算レベル、アトミック操作、ストライプ操作、ブロック操作、チャネル操作、で組み合わせる。
4つの演算については、int6の演算モードを例にして以下で説明する。
アトミック操作
アトミック操作は直接畳み込みのベースとなるステップである。1つのアトミック操作で、各MAC cellは1つのの重みキューブを1つの重みカーネルからキャッシュする。16個のMAC cellは、int16/fp16の場合は16個のカーネルを持つか、int8の場合は32個のカーネルを持つ。1つの
の特徴データのアトミックキューブはすべてのMAC cellで共有される。MAC cellは上記のルール5に即して演算が行われる。各MAC cellの出力は部分和(partial sum)と呼ばれる。各演算は1サイクルで実行され、各サイクルで16個の部分和が生成される。部分輪は畳み込みアキュムレータモジュールに送られ、さらなる演算に使用される。
部分和の式は、以下のように示される:
[tex:PS{w, h,k,r,s, c}= \sum{i=c}^{min(c+63, C−1)}x{(wSX−LP+r),(hSY−TP+s), i} * wt{r, s, i,kPSw, h,k}]
上記の式におけるPSは部分和を指している。変数は常に64で割り切れる数字である。
アトミック操作のダイアグラムを以下に示す。

図43. アトミック操作
ストライプ操作
ストライプ操作は複数の畳み込みから生成されたアトミック操作のグループを組み合わせる。1つのストライプ操作の間には、MAC cellアレイ内の重みデータは変化しない。入力データはキューブ中でスライドしながら進んでいく。
1つのストライプ操作内では、出力キューブの位置が異なるため、それぞれの部分和を加算することができない。
ストライプ操作の長さには限界がある。最小値は16であり、これは内部で重みをフェッチするバンド幅に依存するためである。最大値は32であり、これはアキュムレータのバッファサイズに依存する。いくつかの極端な例では、操作の長さは下限値を下回る可能性がある。
以下の図では、16個のアトミック操作を含むストライプ操作の例である。パディングの大きさは0である。これは入力データキューブの革新的なスキャニングではないということを注意すること。しかし一般的には、ストライプではwの次元を先に読み込む。下記の図ではパディングが存在しないため最後の2行は最初のストライプ範囲には入らない(3x3のカーネルでパディングが存在せず、w=6である場合は出力のwは4となる)。

図44. ストライプ操作
ブロック操作
ブロック操作は高レベルの処理であり、複数のストライプ操作から構成されている。ブロック操作中には、カーネルグループ中の各カーネルは$R\times S\times 64$個の重みエレメントを使用する。この重みは入力特徴データの小さなキューブであり、大きさは演算の結果をストライプ操作間で加算できることを保証できるサイズである。これらの値は16-32エレメントのアキュムレータである。

図45. ブロック操作
1つのブロック操作中のすべてのストライプ操作は、同じ数のアトミック操作を行っている。同一ブロック操作からの部分和は畳み込みアキュムレータでストライプ操作毎に加算される。この結果は累積和と呼ばれる。
累積和は以下の等式で表現される:
[tex: AS{w,h,k,c}= \sum{r=0}^{R−1}\sum{s=0}^{S−1}\sum{i=c}^{min(c+63, C−1)}x{(wSX−LP+r),(hSY−TP+s), i} * wt{r,s,i,k}]
上記の等式において、ASは累積和である。変数は常に64で割り切れる数である。
チャネル操作
チャネル操作も高次元の操作である。この操作には個のブロック操作が含まれている。1チャネル当たりのブロック操作は似ているが、チャネルの操作方向だけが異なっている。以下の図を参照のこと。

図46. チャネル操作
1チャネル中のすべての部分和はストライプ操作により加算される。チャネル操作の後は、畳み込みアキュムレータの結果は畳み込み操作の結果となる。
チャネル操作は、以下の等式で表現される。
[tex: y{w, h,k}= \sum{i=0}^{⌊C/64⌋−1}\sum{r=0}^{R−1}\sum{s=0}^{S−1}\sum{j=c}^{min(c+63, C−1)} x{(wSX−LP+r),(hSY−TP+s), (i64+j)}wt_{r, s, (i*64+j),k}]
上記の等式はストライプが16-32としたときの最初の畳み込みの等式と同一である。1チャネルの操作が完了すると、アキュムレータの値は書きだされて後処理に渡され、次のチャネル操作の準備に入る。
グループ操作
上記の処理は主に入力特徴データと重みデータについてであったが、出力データに対する処理が残っている。出力データに対する処理は非常にシンプルである。C’(K’)->W->H->C(K)の順番で処理を行っていく。ここでC'とK'はカーネルのグループサイズであり、int16/fp16の場合は16、int8の場合は32である。
ダイレクト畳み込みの出力の順番は特徴メモリのマッピングの順番である。

int8とfp16の操作
上記の説明はint16の精度をもとに説明を行っている。fp16の処理も同様であるが、int8はビット処理が異なる。
畳み込みパイプラインでは、int16/fp16用の積和演算器をint8用に2つのMACに分割する。従ってint8でのスループットはint16のスループットに対して倍増する。
下記の表は、1アトミック操作あたりのパラメータである。
| 畳み込み精度 | 有力データの要素数 | カーネル当たりの重み数 | カーネル数 | 出力要素数 |
|---|---|---|---|---|
| int16 | 64 | 1024 | 16 | 16 |
| fp16 | 64 | 1024 | 16 | 16 |
| int8 | 64 | 2048 | 32 | 32 |
Winograd 畳み込み
Winograd畳み込みはダイレクト畳み込みの性能を最適化するアルゴリズムである。畳み込みパイプラインはのサイズのカーネルでのみサポートしている。
Winograd畳み込みの目的は、演算に必要な乗算の数を減らし、結果として与えられたMACハードウェアの数のなかで性能を大幅に向上させる効果がある。
Winograd畳み込みでは、入力と出力アクティベーションデータに対して変形を行うための加算器が余分に必要になる。
Winograd畳み込みで使用される畳み込みパイプラインの等式は以下の通りである:
[tex:\begin{equation}S= AT\left[(GgGT)⊙(CTdC)\right]A\end{equation}]
ここで、⊙は要素毎の乗算である。シンボルは
のカーネルであり、
は
の入力データキューブのタイルである。シンボル
は
と
の畳み込み演算の結果である。これは
の行列である。

$A, G, C$は重み及び入力特徴データを変形したものである。

[tex:U=GgGT]および[tex:V=CtdC]と仮定すると、上記の等式は
A]
上記の等式によると、$A,G,C$乗算は加算器を使って構成できる。のカーネルで4つの結果を計算するのに、16個の乗算器のみ必要である。一方でダイレクト畳み込みを使用すると、36個の乗算気が必要である。従ってWinogradのアルゴリズムはダイレクト畳み込みを実行すると2.25倍の乗算器を削減できる。
$U=GgGT$のステップでは、$3\times 3$のカーネルを$4\times 4$のカーネルに変換し、入力アクティベーションキューブの$4\times 4$パッチxxx。ソフトウェアは、NVDLAを実行する前に重みの情報を変換しておく必要がある。畳み込みパイプラインは入力特徴データおよび乗算の結果の変換を行う。
ダイレクト畳み込みと異なり、Winograd畳み込みパイプラインはカーネルと入力特徴データを$4\times 4\times 4$の要素の小さなデータキューブに分割する。MAC cellに渡す前に、別の加算器を使用してこれらのキューブを$CT$と$C$に変換する。このステップはPRAと呼ばれる。
Winogradアトミック操作では、MAC cellでの64回の乗算は、ダイレクト畳み込みのように単純に加算することはできない。加算は3つのフェーズで構成される。
- フェーズ1. チャネル内の4つの乗算の結果をそれぞれ加算する。このフェーズの出力は16個の部分和であり、$4\times 4$の行列として表現される。
- フェーズ2. $4\times 4$の部分和の行列は、$AT$と行列積を実行する。フェーズ2の出力は8つの部分和であり、$4\times 2$の行列である。
- フェーズ3. $4\times 2$の部分和の行列は、行列$A$と行列積を実行する。出力は4つの部分和である。
したがって、4つの部分和がアキュムレータに格納され、さらなる計算に使用される。フェーズ2とフェーズ3はPOAと呼ばれる。
Winogradモードは、さらに5つの操作を持っている。必要なパラメータを以下のテーブルに示す。
| mode | direct convolution | direct convolution | Winograd | Winograd |
|---|---|---|---|---|
| formats | int16/fp16 | int8 | int16/fp16 | int8 |
| small data cube per MAC cell | 1x1x64 | 1x1x64 | 4x4x4 | 4x4x4 |
| kernels per atomic operation | 16 | 32 | 16 | 32 |
| atomics operation per stripe operation | 16~32 | 16~32 | 16~32 | 16~32 |
| strips operation per block operation | R*S | R*S | 1 | 1 |
| blocks operation per channel operation | C/64 | C/64 | C/4 | C/4 |
Winograd畳み込みの出力シーケンスはダイレクト畳み込みと似ている。Winogradとの違いは以下の通りである:
- Winograd操作では、出力の幅と高さは4で割り切れる。これは必須の条件である。これは特殊なスキャンの順番によるものである。
- Winograd畳み込みのストライプ操作のスキャンの順番は、ダイレクト畳み込みと異なる。下記の図を参照のこと。
- ブロック操作は1つのストライプ操作のみで構成される。
- Winogradレイヤは常に並列に4つのラインを出力する。SDPは出力データキューブのメモリマッピングの集合であることが保証される。

Deconvolution
Deconvolutionは畳み込みの特殊な形である。通常の畳み込みの逆操作のようなものである。通常の畳み込みとは異なり、deconvolutionレイヤは計算後にデータキューブを拡大する。
NVDLAアーキテクチャでは、deconvolutionはソフトウェアの機能である。HWの観点からは、SW deconvolutionレイヤは、シリアルな畳み込みレイヤとRUBIKユニットによりサポートされたcontractレイヤから構成される。
図.49 は1次元のdeconvolutionレイヤの例である。入力データキューブは$W\times 1\times 1$であり、カーネルサイズは$3\times 1\times 1$である。計算フローは畳み込みとは異なるが、最終的な結果は
$DAOUT_i = \sum{j-0}^{2}DAIN{i+j-2} * W_{2-j}$
この式は畳み込みとよく似ているが、重みの$R/S$の順番が逆である。より一般的には、$W\times H\times C$の入力データキューブと$K S\times R\times C$の式は:
$DAOUT{(w,\ h,\ k)} = \sum{x = 0}^{S - 1}{\sum{y = 0}^{R - 1}{\sum{z = 0}^{C - 1}{DAIN{(w + x + 1 - S,h + y + 1 - R,\ z)}*W{(S - 1 - x,R - 1 - y,z,k)}}}}$
式によると、3Dのdeconvolutionは$(S-1)$と$(R-1)$のゼロパディングと、逆転した$R/S$重みの順番で

deconvolutionのXのストライドか$Y$のストライドが1ではない場合、計算フローは少し異なる。重みカーネルは小さなカーネル集合に分割される。それぞれのカーネル集合は$X$と$Y$のストライドが1と等しいように畳み込みレイヤで処理が行われる。いくつかの畳み込みレイヤはdeconvolutionのレイヤ結果を生成するために使用される。
シリアル畳み込みレイヤの後にすべてのdeconvolutionの結果の値が計算されるが、マッピングの順番は意図したものとは異なる。 もし畳み込みの結果のキューブをC方向に追加すると、最終的な出力キューブはWinogradチャネル拡張データキューブとなる。 拡張パラメータはdeconv_x_strideとdeconv_y_strideである。
したがって、NVDLAはこれらの出力の値を並び替えて、所望のdeconvolution出力キューブを取得するためにRubikモジュール内のcontract layerという特殊なレイヤを使用する。
まとめると、NVDLAは以下の手法をもってdeconvolutionをサポートする:
- NVDLAはdeconvolutionにおいて、1以上のストライドをサポートするために2つのステップを使用する。
- 最初のステップはシリアル畳み込みレイヤと、逆順序のカーネルを使用する。
- 最初のステップの出力はWinogradチャネル拡張出力データキューブである。拡張パラメータはdeconvolution xストライドと、deconvolution yストライドである。
- 2番目のステップはRUBIKユニットで実行する。
- RubikユニットはWinogradチャネル拡張データキューブに対して逆の操作を実行する。
- 2番目のHWレイヤの後は、出力データキューブは所望の結果に整形される。
Convolution with Image Input
入力画像の畳み込み
NVDLAはMACの使用率を向上させるために特殊モードにおいて入力データの畳み込みをサポートしている。ここで、画像データは入力サーフェイスの一部とする。しかし、NVDLAは直接畳み込みしかサポートしない。DC, Winogradおよびdeconvolutionレイヤはピクセルフォーマットを扱うことができない。マルチバッチオプションも、画像入力ではサポートされない。
DCと比較して、画像入力では以下の点が異なる:
チャネルのプレ拡張。重みカーネルはチャネルのプレ拡張を実行する必要がある。これはDCモードやWinogradモードのようなものではない。
畳み込みバッファのデータマッピング。畳み込みバッファでの画像データマッピングはDCおよびWinogradモードでのものとは異なる。左右パディングのすべての要素と入力ピクセルラインはCBUFエントリ中にコンパクトに格納されている。以下の画像を参考のこと。チャネルサイズが4である場合、要素のマッピング順番はR(Y)->G(U)->B(V)->A(X)である。チャネルが3の場合は、順番はR(Y)->G(U)->B(V)である。
- ストライプ操作の晩餐。ストライプ操作の長さは64に固定される。ストライプ操作はラインをまたぐことはない。したがって、すべてのストライプ操作はCBUFエントリの最初のバイトから開始される。
- チャネルポスト拡張による高速化。チャネルのプレ拡張を行っても、通常はカーネルのチャネルサイズは32よりも小さい。したがって、チャネルのポスト拡張は画像入力の畳み込みレイヤで非常に有用である。
![]()
チャネルのポスト拡張
チャネルのポスト拡張は、画像入力の畳み込みにおいてMACの使用効率を向上させるためのオプションである。
畳み込みパイプラインでは、1つのアトミック操作で64要素のチャネルの次元が必要になる(Winogradモードの場合を除く)。 もし入力データのチャネルのサイズが64よりも小さければ、MACは100%の使用効率にはならない。 したがって、MACの効率はDCモードと画像入力モードの場合はチャネルサイズに依存する。
チャネルのポスト拡張の基本的なアイデアは、実行中にチャネルサイズを拡大するために縦方向の拡張を行うということである。
例えば、画像入力レイヤはのカーネルサイズを持っている。
もしポスト拡張が有効でないと、拡張前のチャネルのサイズは16であり、MACの使用効率は25%となる。
しかし、ポスト拡張パラメータを4に設定すると、各アトミックサイクルにおいて畳み込みパイプラインは隣接する4つのラインをフェッチすることで、
のラインとする。
これにより、MACの効率は100%に復帰する。
チャネルのポスト拡張にはいくつかの制限が存在する。
チャネルポスト拡張は、画像入力の畳み込みのみ有効でである。
チャネルポスト拡張は2-line拡張と4-line拡張のみサポートしている。
- チャネルポスト拡張は拡張前のチャネルサイズと、畳み込みの
ストライドにより制限される。
| チャネルのポスト拡張 | conv_x_stride の制限 | 拡張前のチャネルサイズの制限 |
|---|---|---|
| 1-line | No | No |
| 2-lines | (conv_x_stride * ori_channel_size) <=32 | <=32 |
| 4-lines | (conv_x_stride * ori_channel_size) <=16 | <=16 |
チャネルポスト拡張の数(N)はカーネルの高さ(R)よりも小さくする必要はない。ハードウェアは自動的に冗長なサイズを検出して計算に巻き込まれることを避ける。しかし、これはこの場合はMACの使用効率が向上するわけではないということに注意する必要がある。
マルチバッチモード
NVDLAのエンジンは、マルチバッチをサポートして性能を向上させバンド幅を削減する。これは特にFully-Connected(FC)レイヤで有効である。1つのFCレイヤの出力はのデータキューブを出力する。これはつまり、FCレイヤのすべての重みデータは1度だけ使われる。FCレイヤの1回のストライド操作は、1回のアトミック操作で羅う。これによりパイプライン中では多くのバブルが発生し、MACの効率は6.25%まで減少する。効率を向上させるために、NVDLAのエンジンはマルチバッチモードを適用することができる。
マルチバッチモードはDCモードの特殊なオプションであり、複数の入力特徴データキューブを一度にしょるすることができる。畳み込みパイプラインは複数の入力データキューブをフェッチし、1セットのカーネルに適用する。これはアトミック操作にも変更を与える。異なる入力データキューブから作られた小さなキューブはインターリーブしながらロードされ、アトミック操作に渡される。ストライプ操作は、マルチバッチのためにアトミック操作が含まれている。ストライプ内で重みは再利用されるため、重みをロードするサイクルは隠蔽され、効率が向上する。
バッチサイズ毎のストライプ操作の長さは以下の通りである:
| バッチサイズ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Normal length | 16 | 8x2 | 8x3 | 4x4 | 4x5 | 4x6 |
| Max length | 32 | 16x2 | 16x3 | 8x4 | 8x5 | 8x6 |
| Batch Size | 7 | 8 | 9 | 10 | 11 | 12 |
| Normal length | 4x7 | 2x8 | 2x9 | 2x10 | 2x11 | 2x12 |
| Max length | 8x7 | 4x8 | 4x9 | 4x10 | 4x11 | 4x12 |
| Batch Size | 13 | 14 | 15 | 16~32 | ||
| Normal length | 2x13 | 2x14 | 2x15 | 1xN | ||
| Max length | 4x13 | 4x14 | 4x15 | 1xN |

Dilation
Dilationはと
のサイズのカーネルを0で拡張するためのもう1つのオプションである。この機能は必要であればSWで有効である。
以下の図は、パラメータ=3のdilationである。

NVDLAはと
の両方の次元でサポートしている。Dilationの制約は:
- DilationはDCモードでのみサポートしている。
- DilationはWinogradおよび画像入力モードではサポートしていない。
消費電力について
畳み込みパイプラインは、各主要なパイプライン中にてクロックゲーティングをサポートしている。もしパイプラインステージが空いている場合、パイプライン中のデータパスはクロックゲートされる。