SiFive の P870-Dコアが発表されたが、個人的には、これはつまりSiFiveがメインコアの開発を実質的に止めている、ということを示していると思う。
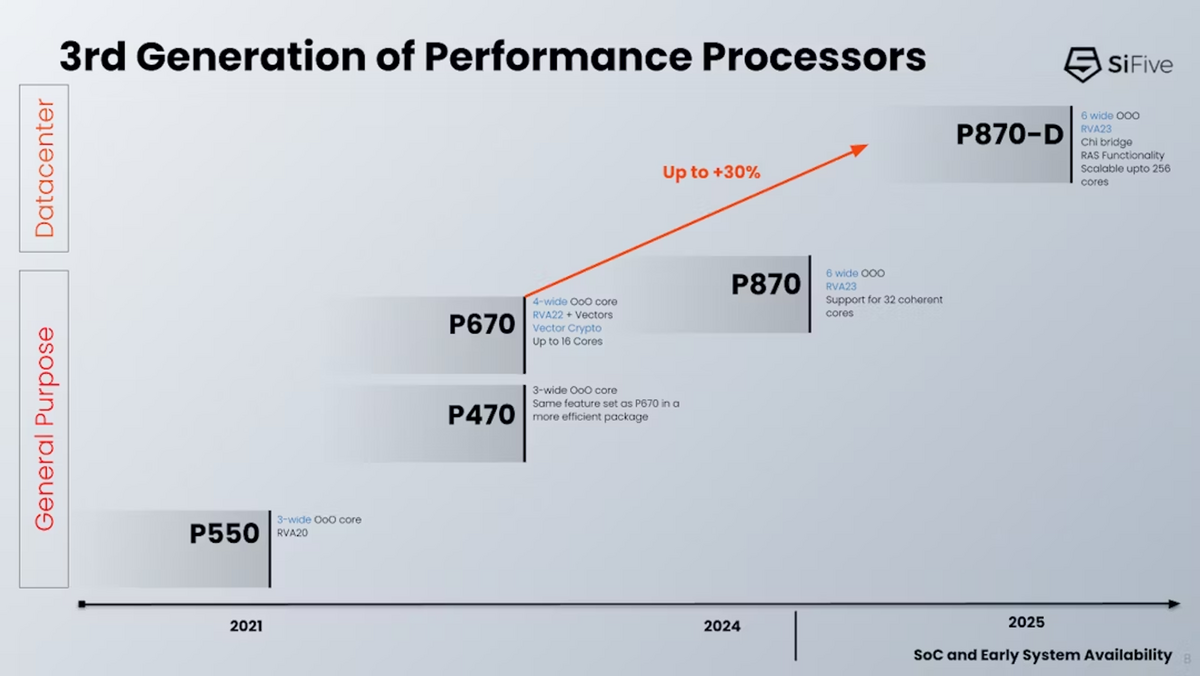
このグラフは、縦軸が性能を意味するものと思われるがはっきりはしない。なぜかというと、後述する P870-D を追加したグラフは縦軸が性能ではなく、全く意味のない指標になってしまっているからである。
という訳で、P870はどういうコアだったのか、Hot Chips 2023の発表資料を基にしたレポートを読みながら、振り返って復習しようという訳だ。
https://chipsandcheese.com/2023/09/03/hot-chips-2023-sifives-p870-takes-risc-v-further/ より引用chipsandcheese.com
SiFive が Hot Chips 2023で発表した P870 コアは、ARMの Cortex X2 や ARM の Zen 4c と同程度の性能を達成するものと見込まれている。
マイクロアーキテクチャ概要
- アウトオブオーダ実行、6ワイドコア
- 大容量のリオーダバッファと強力な命令フュージョン機能
- 非連結分岐予測
- 非スケジューリング・キュー(ディスパッチ・キュー)
- ベクトル実行機能
SiFiveのパイプライン図から、P870のミス予測ペナルティは8サイクルのようだが、これはARM、AMD、Intelの最新CPUと比べるとかなり短い。
もし、ミス予測がExステージで発見され、命令キャッシュルックアップステージからパイプラインを再開できる場合、ミス予測ペナルティはわずか7サイクルとなる。
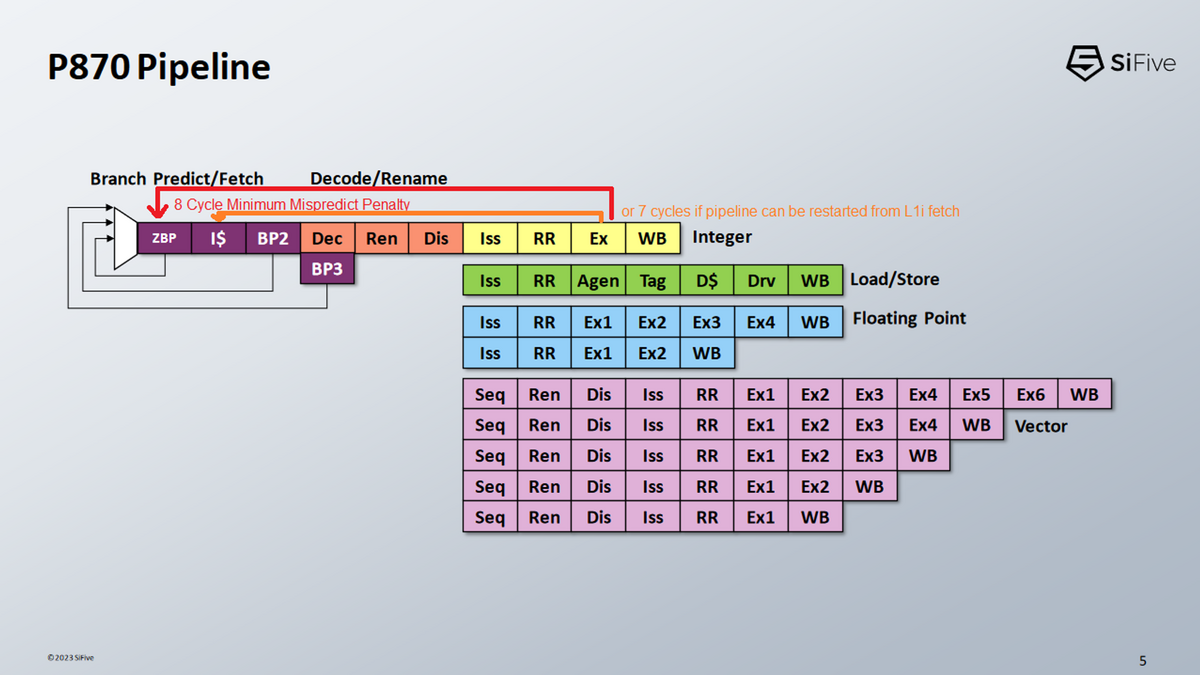
P870は非常に短いパイプライン構成であり、なおかつ3GHzのクロック周波数を達成できるとしている。
分岐予測器
P870の分岐予測器は、8つのテーブルからなるTAGE分岐予測器が搭載されており、合計16Kのエントリを持っている。また、それ以外にも少なくとも8つのサブ分岐予測器を使用している。
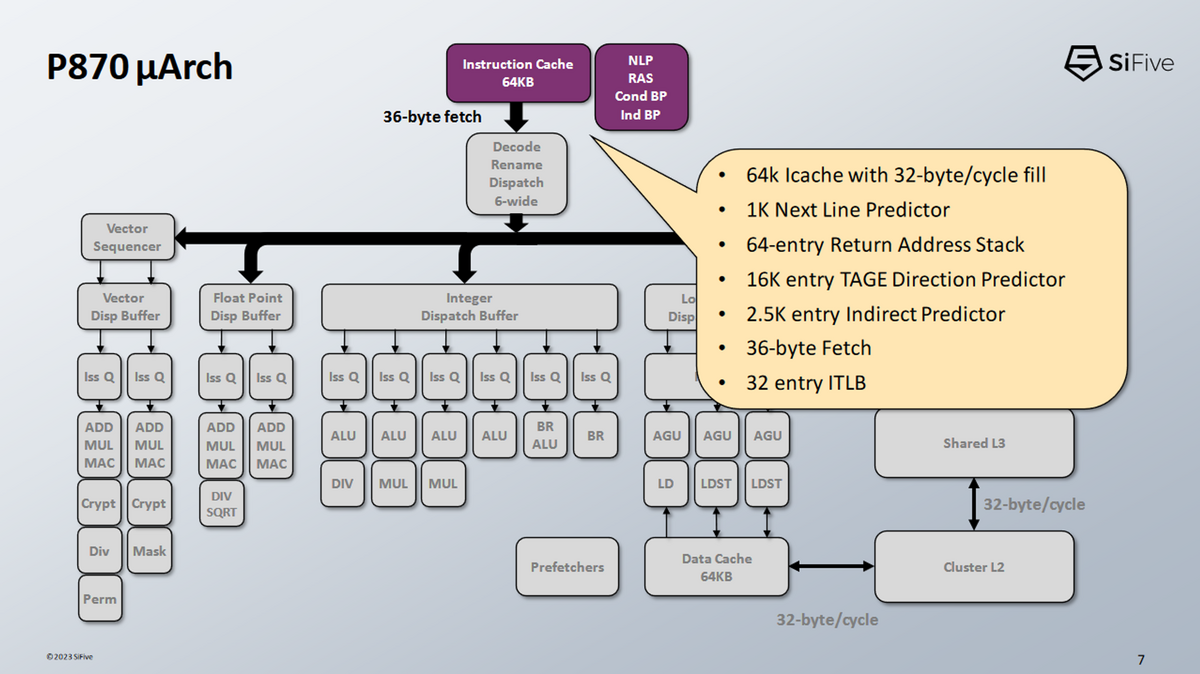
P870の分岐予測器は、複数のパイプラインステージにわたってフェッチターゲットを生成する。
- 高速ゼロバブル(Fast Zero Bubble)予測器がターゲットアドレスを生成する
- 命令キャッシュに渡され、フェッチ処理が開始される
- TAGE予測器が予測を完了し、2サイクルのペナルティでゼロバブル予測器を上書きすることができる。
- 間接分岐予測は次のサイクルで行われ、命令デコードと重なる
- 間接予測には3サイクルのペナルティが発生する。
- 比較のため、AMDのZen 4では、間接予測やL2 BTBのオーバーライドに同様の3サイクルのペナルティがある。
- ゼロバブル予測に1024エントリを持っており、これはAMDのZen 3に匹敵するものである。
- 64エントリーのリターンアドレススタックは非常に大きく、やり過ぎの域に達している。
- AMDのZenラインには32エントリーのリターン・スタックしかない。
- 間接予測器は2.5Kエントリーの容量
- Zen 4は3072エントリーの間接予測器
- Zen 3は1536エントリーだ。
- したがって、P870の間接予測機能は、これら2つのZen世代のちょうど中間に位置する。
命令フェッチ
分岐予測器がフェッチアドレスを生成すると、P870のフロントエンドは64KBの命令キャッシュから1サイクルあたり36バイトをフェッチできる。
- 1サイクルに36バイトというのは誤字ではない
- P870は毎サイクル9命令分のRISC-V命令をフェッチし、6ワイドデコーダーに供給することができる。
- 32エントリのiTLBをもっている。
- AMDのZen 4に搭載されている64エントリーのiTLBと比べると少し小さい
- P870の命令デコーダの命令フュージョン
- SiFiveは具体的な内容には触れなかった。
- x86コアが比較分岐や条件分岐、あるいは隣接する命令とのNOPを融合するのを見てきた。
- SiFive社は、P870がそれ以上の能力を持つことを示唆している。
- 「なぜRISC-Vはもっと複雑なメモリ・アドレッシング・モードを持っていないのか」と反論する人もいるかもしれない。その哲学は興味深いものだと思うが、単にオペコード空間を食いつぶすのとは対照的に、それを構築した命令を取り出して融合させるというものだ」Brad Burgess at Hot Chips 2023
命令の融合は非常に直感的に理解できる。例えば、ドイツ人は 「financial market stabilization act」(金融市場安定化法)のような5つのトークンを持つ英語のフレーズを読み、脳のリソースをより効率的に使うために、それを1つのマイクロオペ(finanzmarktstabilisierungsgesetz)に融合させるかもしれない。命令融合には、融合された命令が隣接している必要があるからだ。コンパイラーは、これを可能にするために命令を配置しなければならない。
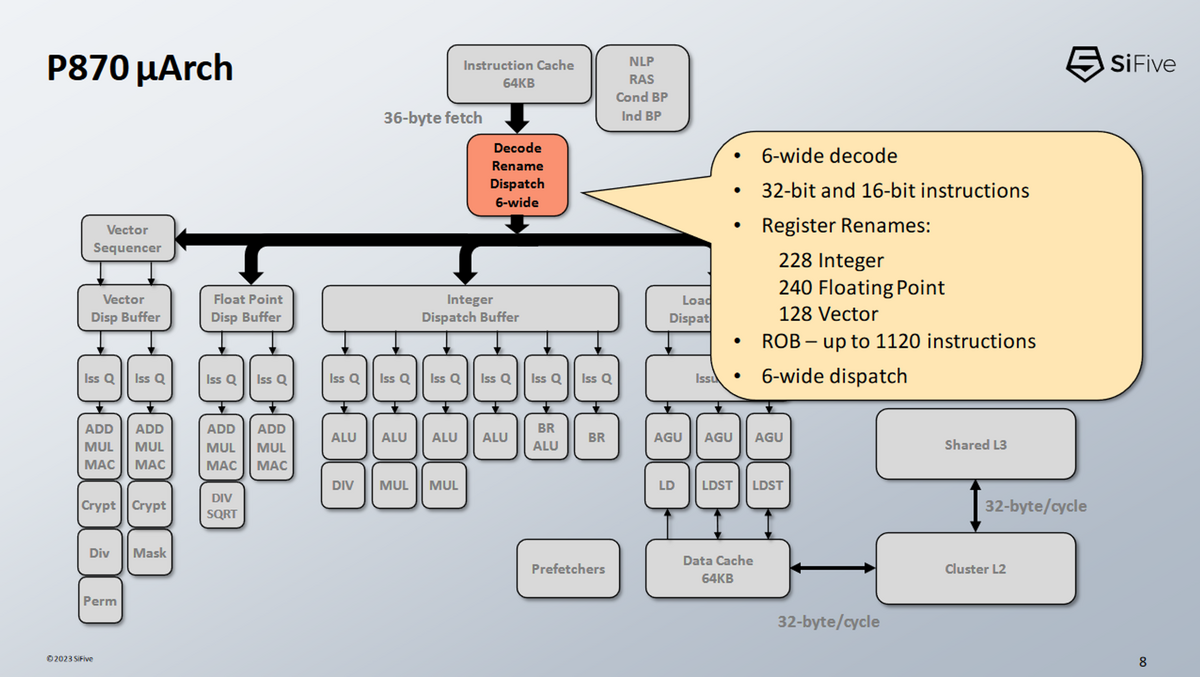
命令がデコードされると、すべてのレジスタ参照は、対応する物理レジスタ・ファイル・エントリを参照するように適切にリネームされる。その他のバックエンド・リソースは必要に応じて割り当てられ、命令はアウトオブオーダー実行エンジンによって追跡される。
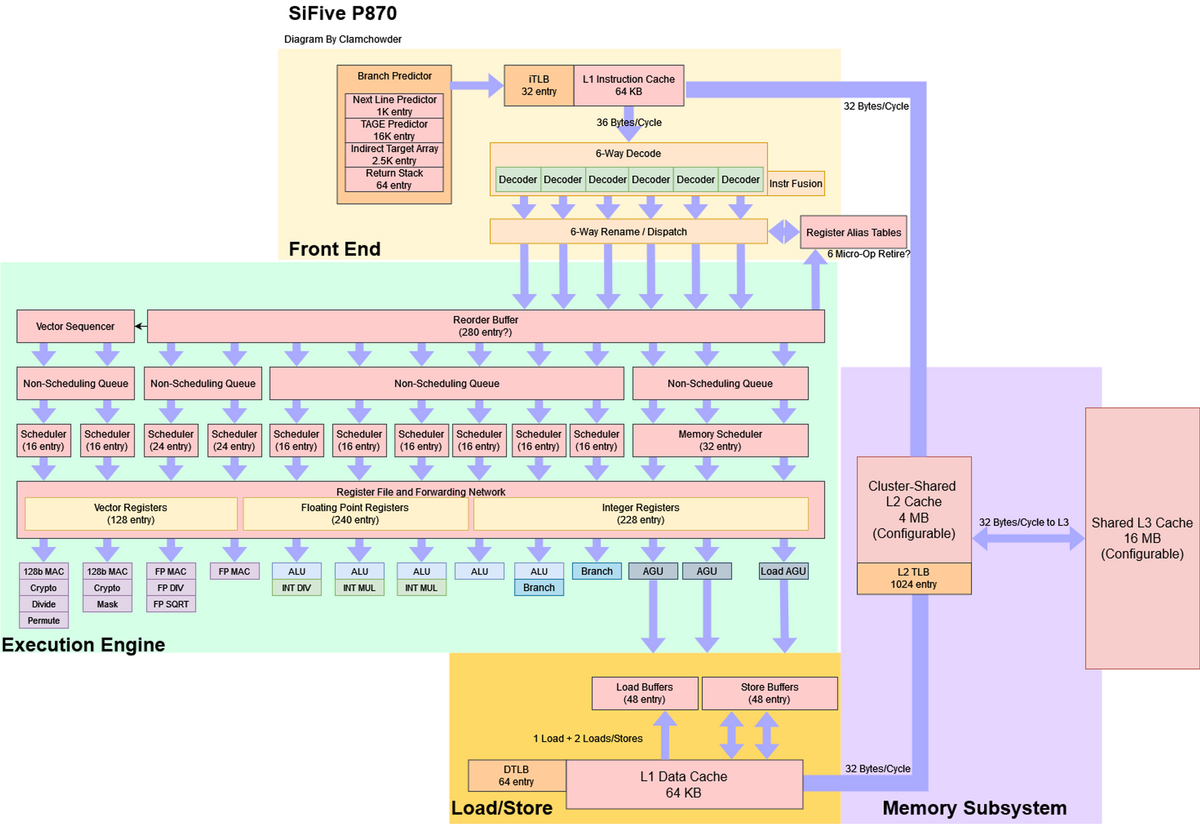
実行エンジン
P870は大規模なバックエンドを持ち、ARMのCortex XシリーズやAMDのZen 4にほぼ匹敵するリソースを持つ。
リオーダーバッファとレジスタファイルの容量は3つのコアでほぼ同じだが、P870のロードキューとストアキューは少し軽い。
| リソース | 使用条件 | SiFive P870 | AMD Zen 4 | ARM Cortex X2 |
|---|---|---|---|---|
| リオーダバッファ | exists | 280 entry? 1エントリあたり4つのFusedされた命令を保持できる? | 320 entry 1エントリあたり4つのFusedされた命令を保持できる | 288 entry 1エントリあたり2つのFusedされた命令を保持できる |
| 整数レジスタファイル | 整数レジスタへの書き込み | 228 entry | 224 entry | ~213 entry |
| 浮動小数点レジスタファイル | 浮動小数点レジスタへの書き込み | 240 entry | 192 entry | ~249 renames measured. フュージョン可能 |
| ベクトルレジスタファイル | ベクトルレジスタ書き込み時 | 128 entry | 192 entry | ~156 entry |
| ロードキュー | メモリからの読み込み | 48 entry | 136 entry | 174 entry |
| ストアキュー | メモリへの書き込み | 48 entry | 64 entry | 72 entry |
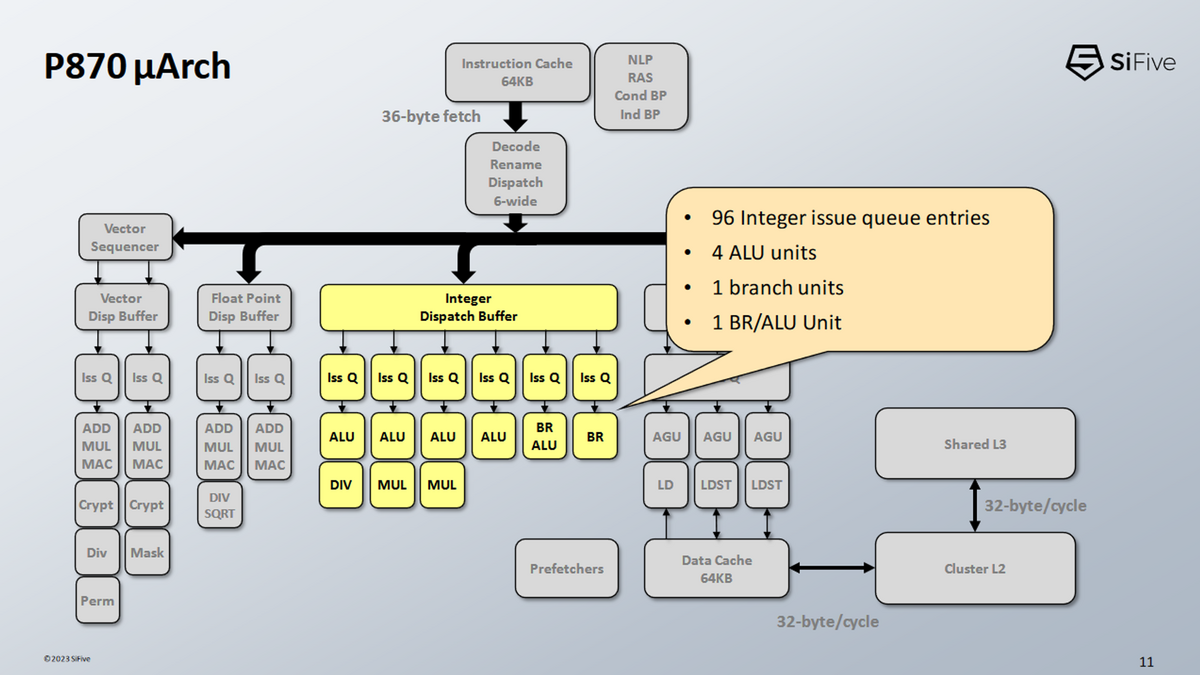
- SiFiveの実行ポート戦略:ARMのCortex X2戦略と類似している:
- 小さな分散スケジューラーを乱発し、大量の実行ポートを生み出している
- 分散スケジューラは、1つのスケジューリング・キューがいっぱいになるとストールにつながる可能性があるため、チューニングが難しい場合がある。
- これに対抗するため、SiFive社はアップル社のFirestormと同様の戦略を使っている。
- 非スケジューリングキュー
- 整数実行ユニットには合計6ポートが備えている
- Cortex-X2と同じ数
- それぞれに専用のスケジュール・キューが用意されている
- P870の分岐ポートの1つを一般的なALU演算としても使用できるようにしている。
浮動小数点実行
- P870のFPパイプラインは2本
- それぞれが最も一般的な演算を処理できる
- FP加算と乗算のレイテンシが2サイクルであることを強調している
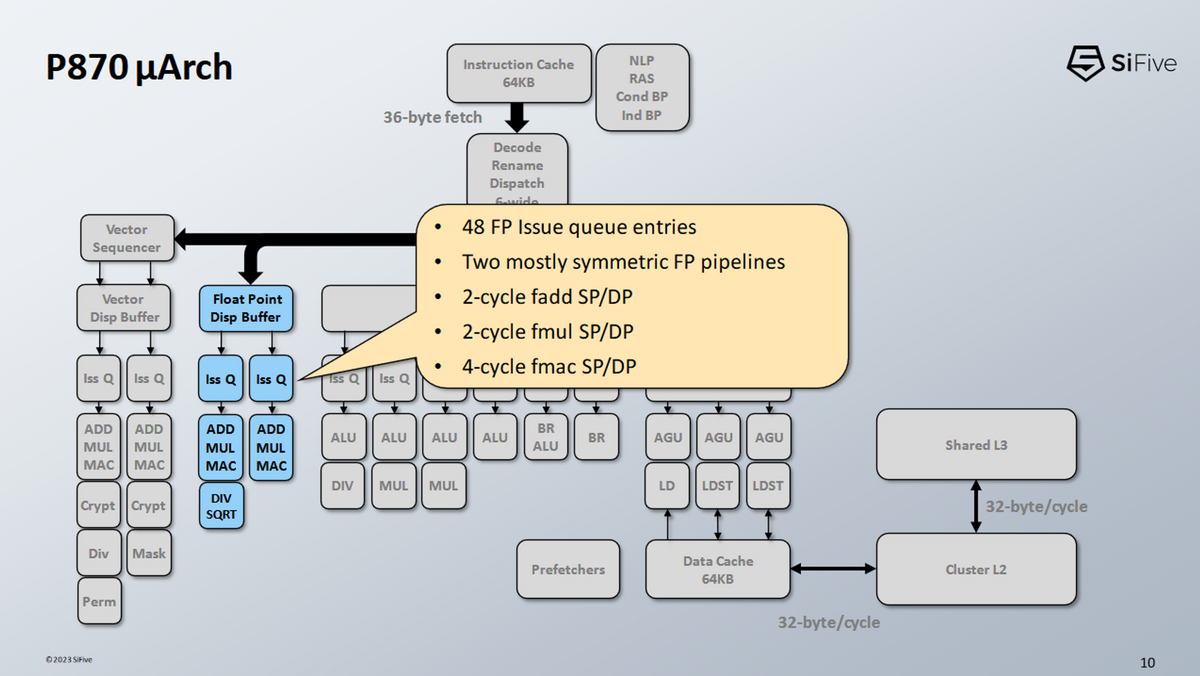
- P870はFPとベクトルのレジスタファイルを分けている
- 現在の他の多くのCPUとは異なっている
- 利用可能なリネームレジスタの数が異なる
- 一方は他方の倍数ではない(フュージョンケースの可能性は低い)。
- もしそうであれば、浮動小数点とベクタのレジスタファイルは個別にポート数が少なくなる可能性がある。
- 2つの乗算加算ユニットに供給するには6つの入力が必要であり、ポート数を少なくすることで、より面積効率の良いレジスタファイルができるはずである。
ベクトル実行
- P870は、128ビット幅のパイプライン1組を使ったベクトル実行をサポートしている
- これはP870のアーキテクチャの弱点だが、それでもRISC-Vの世界では確かな前進だ。
- Ventana社のVeyron V1のような他のRISC-Vチップは、スカラーFP実行のみで、ベクトル実行機能はまったくない。
- 一対の128ビット・ベクトルパイプは、ARMのNeoverse N1とN2に搭載されているものとほぼ同じであり、合格点のベクトル性能を提供できる。
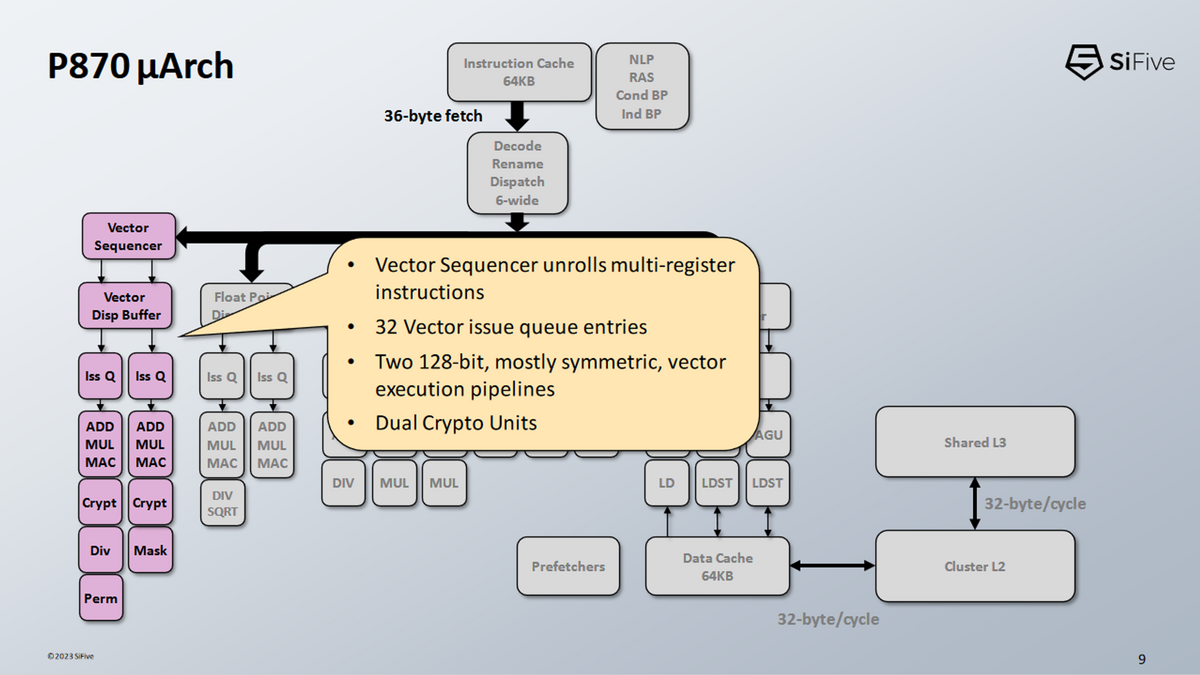
- P870は、ベクターシーケンサーと呼ばれるRISC-VのLMUL機能を狙ったユニークな対処メカニズムを備えている。
- 非常識なプログラマーは、LMULを1より大きな値に設定し、ベクタ命令を連続したレジスタ・ブロックにアドレスさせることができる。
- 通常、複雑な命令はデコーダーが複数のマイクロオペに分割して処理する。
- しかし、そうすると、LMUL≠1の場合、デコーダーとリネーマーの帯域幅を大量に消費することになる。

そこでSiFiveでは、LMUL > 1の場合、パイプラインのさらに下流でベクタ命令を分割する。つまり、LMUL = 2の命令は、1つのデコードスロットしか消費しない。シーケンサの後では、複数のスケジューラスロットを消費し、必要なサイクル数だけマイクロオペが発行されることになる。
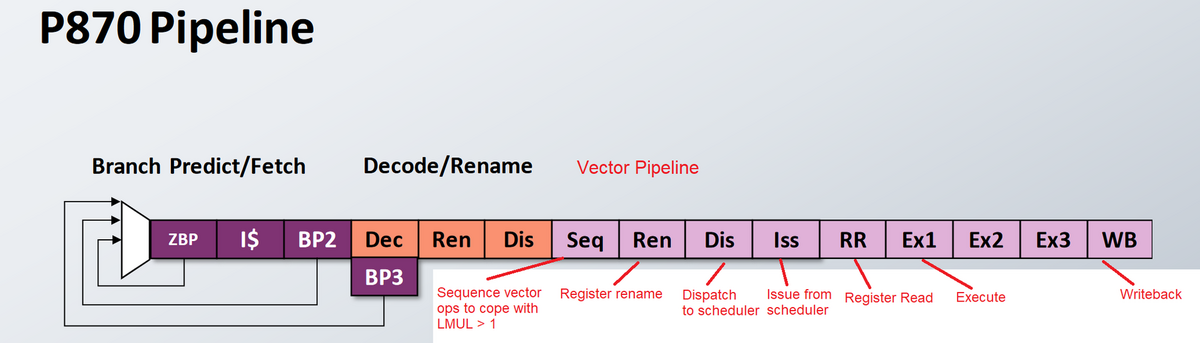
- シーケンサーはベクトル演算をわずか1サイクルで分割できることがわかる。
- シーケンサの後に配置された独自のレジスタ・リネーム・ステージがあるため、物理レジスタはベクタ演算が分割された後に割り当てられる。
- すべての新しいアーキテクチャ機能と同様に、RISC-VのLMULがどの程度有用なものになるかは、しばらく様子を見る必要がある。