GAP Benchmarkの各プログラムの中身を調べている。まずはbfsから。
bfs : Breath First Search
./bfs -f benchmark/graphs/kron.sg -n64 > benchmark/out/bfs-kron.out
fでグラフをロードする。nはトライアルの数。start_vertex()は-1が設定されるっぽい。DOBFS()にてBFSの実行。start_vertex()が-1であることにより、64回ランダムにトライアルがなされるっぽい。 出力される情報は以下。benchmark/out/bfs-kron.outに生成される。
Read Time: 26.00838
Graph has 134217726 nodes and 2111632322 undirected edges for degree: 15
Source: 2338012
i 0.19856 # InitParent()に必要な時間
td 2562 0.51446 #
td 9911670 0.60898
e 0.26399
bu 51425989 0.77198
bu 1687995 0.33199
c 0.15596
td 4661 0.17200
td 15 0.20400
td 0 0.21998
Trial Time: 3.60879
/* ... 途中省略 ... */
int main(int argc, char* argv[]) { CLApp cli(argc, argv, "breadth-first search"); if (!cli.ParseArgs()) return -1; Builder b(cli); Graph g = b.MakeGraph(); SourcePicker<Graph> sp(g, cli.start_vertex()); auto BFSBound = [&sp] (const Graph &g) { return DOBFS(g, sp.PickNext()); }; SourcePicker<Graph> vsp(g, cli.start_vertex()); auto VerifierBound = [&vsp] (const Graph &g, const pvector<NodeID> &parent) { return BFSVerifier(g, vsp.PickNext(), parent); }; BenchmarkKernel(cli, g, BFSBound, PrintBFSStats, VerifierBound); return 0; }
InitParent()により、グラフの親情報を構成する。
pvector<NodeID> parent = InitParent(g);
- 条件分岐が存在している。現在のノードの出力エッジ数よりも、調べるべきグラフのエッジ数/alphaが大きい場合と小さい場合で分岐している。
int64_t edges_to_check = g.num_edges_directed(); int64_t scout_count = g.out_degree(source); while (!queue.empty()) { if (scout_count > edges_to_check / alpha) { /* ボトムアップアプローチ: Bitmapを使用する */ } else { /* トップダウンアプローチ: SlidingQueueを使用する */ } } }
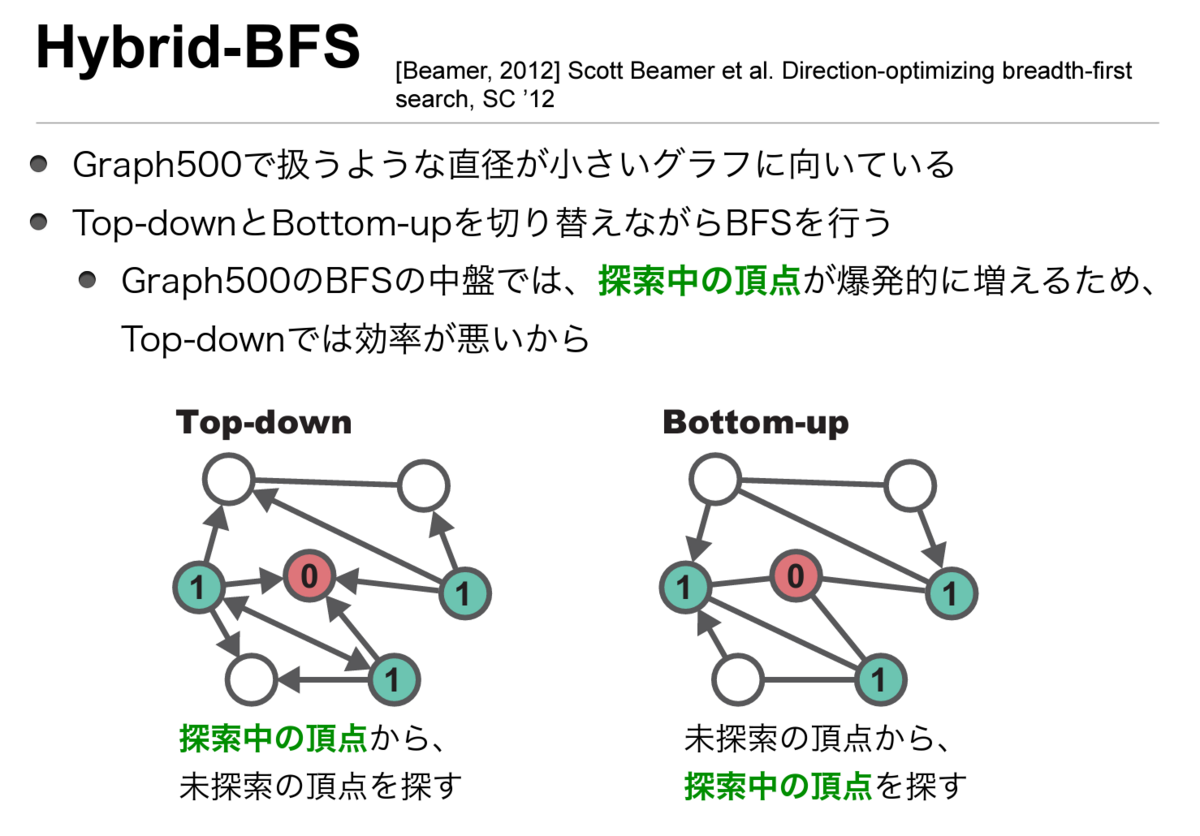
このBFS実装は、方向最適化アプローチ[1]を利用している。
alphaとbetaパラメータを使って探索方向を切り替えるかどうかを決定する。フロンティアを表現するために、トップダウンアプローチではSlidingQueueを使用し、ボトムアップアプローチではBitmapを使用する。トップダウンアプローチでは、偽共有を減らすために、スレッドローカルのQueueBufferが使用される。フロンティアから出る辺の数を計算する時間を節約するために、この実装では、親配列に負の数として格納することで、最初に次数を一括で事前計算する。したがって,parentのエンコーディングは次のようになる.parent[x] < 0は x が未訪問であり,parent[x] = -out_degree(x)であることを意味する.parent[x] >= 0は x が訪問済みであることを意味する。
https://dl.acm.org/doi/10.5555/2388996.2389013
ちょっとこれをまじめに勉強するには沼にはまりすぎる気がしてきた。
トップダウンアプローチは、単純に親ノードから探索をしていき、キューに詰め込んでいく一般的な実装っぽく見える。これをOpenMPで並列化してある。トップダウンステップによって、新しく発見されたノード数を返しているようだ。
ボトムアップアプローチは未探索の頂点から、探索済みの頂点を探すというアプローチらしい。あんまり詳しいことはわからん。