ETH Zurichが公開した論文を読んでいる。疎行列計算のためのアクセラレータに関する論文だ。
https://arxiv.org/pdf/2305.05559v1.pdf
概要
疎行列演算を高速化するためのハードウェアアクセラレーション手法の提案:
疎行列の演算というのは、一般的に以下のような計算を行うものである。A_vals行列とbベクトルの演算をするためには、以下のような方式をとる。A_valsは疎ベクトルで、非ゼロの位置はA_ptrによって管理されている。
for i in 0 to A_nrows: for j in A_ptr[i] to A_ptr[i+1]: c[i] += A_vals[j] * b[A_idcs[j]]
ちなみに、この疎ベクトルと密ベクトルの計算を、Sparse VectorとDence Vectorのベクトル積ということでと表記する。
さらに、疎ベクトルと疎ベクトルのベクトル積を取る場合にはさらに複雑になる。Sparse VectorとSparse Vectorのベクトル積ということで、と表記する。
while ia < len_a and ib < len_b: if a_idcs[ia] == b_idcs[ib]: c_i += a_vals[ia++] * b_vals[ib++] while ia < len_a and a_icds[ia] < b_idcs[ib]: ia++ while ib < len_b and b_idcs[ib] < a_icds[ia]: ib++
この計算を高速化するために、SSSRという新しい拡張レジスタを定義する。SSSRはSparse Stream Semantic Registerの意味で、もともとあるSSR(Stream Semantic Register)を拡張したもので、Sparseなアクセスに対しても適用可能にしたものである。
これにより、上記のの計算はRISC-Vのアセンブリ命令を用いて以下のように記述できる。
call cfg_sssr_a_ft0 call cfg_sssr_b_ft1 hwloop 1 fmadd.d %c, ft0, ft1, %c
ハードウェアとして、2つのアドレスジェネレータを持っている。
- Indirect Address Generator
疎行列における非ゼロ要素の位置情報を格納するインデックス行列を参照するためのもの。
インデックス行列に格納された非ゼロ要素の位置情報を参照し、それに応じたデータ行列内のアドレスを生成する。
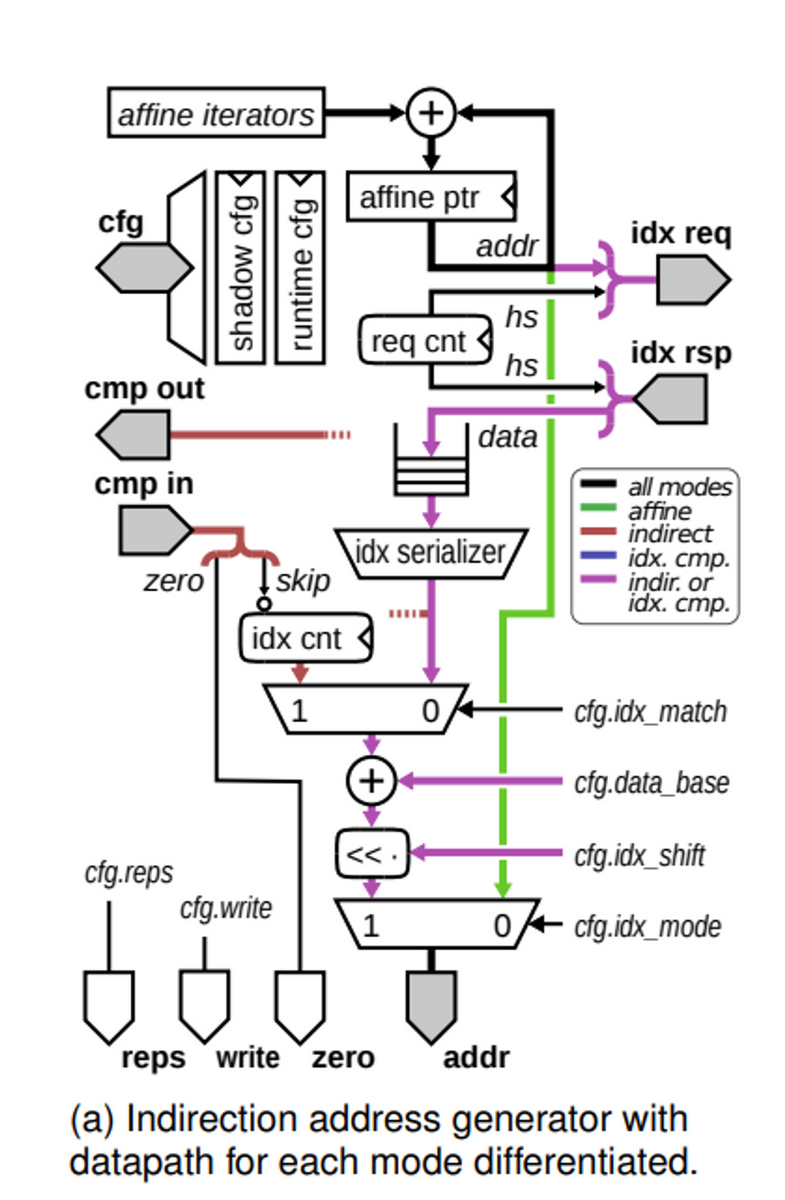

Affine_ptrを使って、ポインタを保持する行列に対するアクセスを行う。その結果から、データサイズやコンフィグレーンションに応じてアドレスを生成して、その結果をFIFOに書き込む。
- Egress Address Generator
演算結果を格納するための出口行列のアドレスを生成する機能を持つ。
具体的には、入力行列と同じ構造の出口行列を参照し、そのアドレスを生成する。
また、複数の演算を行う場合には、前の演算結果を参照して次の演算に必要なアドレスを生成することができる。
最終的に、図1bのようにISSRとESSRが構成されている。
図1(c)は、ISSRとESSR、さらに最終的なインタフェースなどを備えたSparse SSRストリーマの構成である。
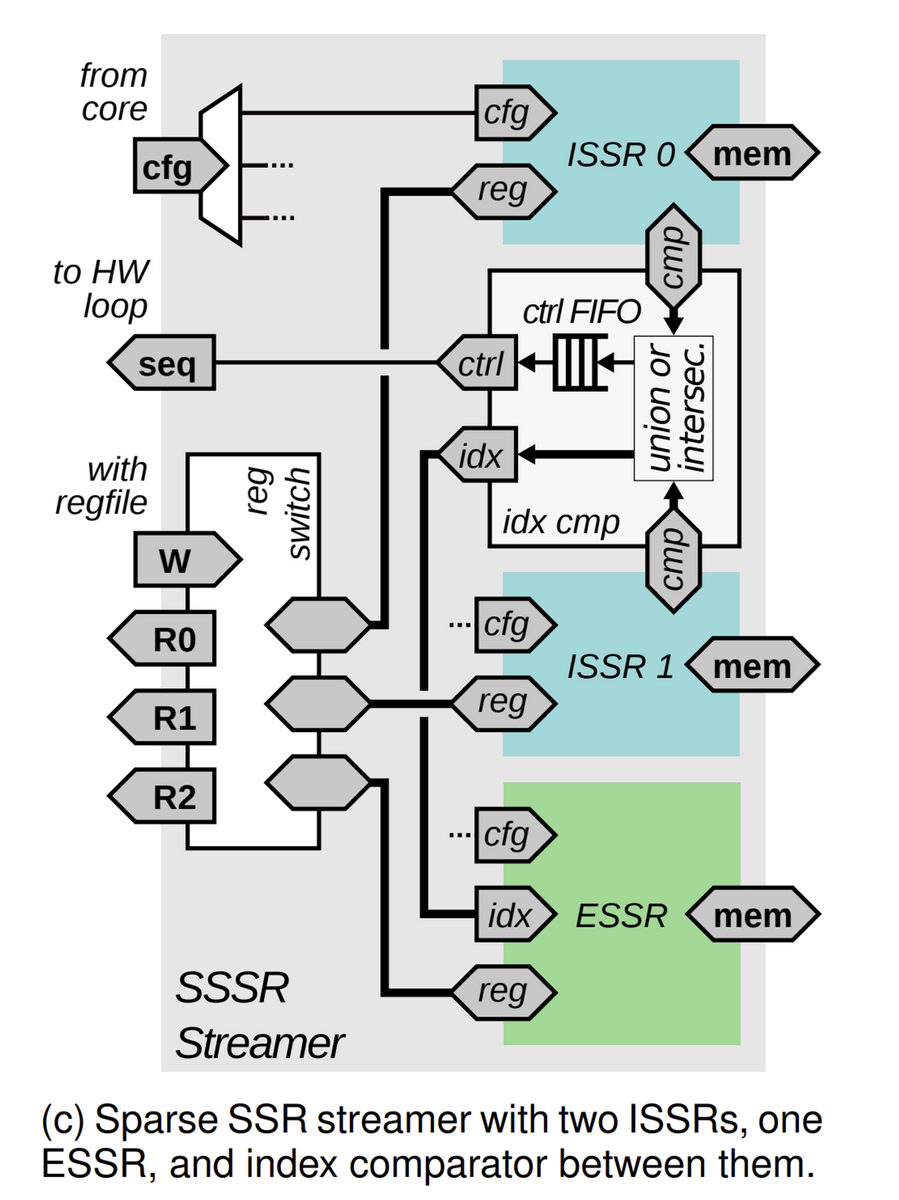
- 任意の数のSSR、ISSR、ESSRを任意のレジスタ・インデックスにマッピングするように構成することができる
- オプションのSSRインデックス間ストリーム結合機能がある場合は、いくつかの構成上の制約を受ける
- ストリーマ内の2つのISSRだけが、互いのインデックス比較をサポートする
- 第3のESSRは、ライトバックのために結合したインデックス・ストリームを消費することができる
- したがって、デフォルトの構成は、2つのインデックス比較用ISSRと1つのESSRからなる
- オプションのSSRインデックス間ストリーム結合機能がある場合は、いくつかの構成上の制約を受ける
- さらに、
をサポートするためのインデックスコンパレータを含んでいる。
の動作をサポートするための構成は以下の通り。
- ISSR0はインデックスとして 2 → 4 → 5 → 8を生成する
- ISSR1はインデックスとして 1 → 4 → 5 → 6を生成する
- ISSRインデックスストリームのどちらかが先行している場合、そのどちらかを判断し、必要に応じて両方を前進させてインデックスの和または交差を生成する。