Rustで作っているBinary Translation型のRISC-Vエミュレータ、Dhrystoneを使ってシミュレーション速度の解析を行っている。前回の解析でFNVHashMapを使うことである程度速度の向上が見られたが、より性能を上げるためにはそもそもHashMapを使わなければよいのではないかという気分になってきた。HashMapはinsertしたキーを必ず保持するようだが、必ず保持しておく必要はなく、キャッシュのように動いてくれるだけで十分だ。ダイレクトマップのようにアドレスに関連ついてTCGを保持しておき、同じキーによりDropoutしてしまっても、もう一度変換すればよいだけの話だ。というわけで、HashMapをあきらめて単純なダイレクトマップキャッシュ(というか配列)に置き換えてみることにした。
キャッシュとして1024要素を保持できる配列を用意し、
m_tb_text_hash_address: キー(アドレス)を保持するm_tb_text_hash_inst_size: 命令のサイズを保持するm_tb_text_hash_memmap: 変換後のx86コードを保持する
diff --git a/src/emu_env.rs b/src/emu_env.rs index 1edb93b..33d0eb5 100644 --- a/src/emu_env.rs +++ b/src/emu_env.rs @@ -3,7 +3,8 @@ use std::rc::Rc; use mmap::{MapOption, MemoryMap}; // use std::collections::HashMap; -use fnv::FnvHashMap; +use arr_macro::arr; +// use fnv::FnvHashMap; use std::mem; use crate::elf_loader::{ELFLoader}; @@ -25,6 +26,11 @@ use crate::instr_info::InstrInfo; use std::time::Instant; +const TCG_HASH_SIZE:usize = 1024; +fn calc_hash_func(addr: u64) -> usize { + ((addr >> 1) & 0x3ff) as usize +} + #[derive(Debug, Copy, Clone, PartialEq)] pub enum MachineEnum { RiscvVirt, @@ -69,8 +75,12 @@ pub struct EmuEnv { pub m_prologue_epilogue_mem: MemoryMap, pub m_guest_mem: MemoryMap, - pub m_tb_text_hashmap: FnvHashMap<u64, (usize, Rc<RefCell<MemoryMap>>)>, + // pub m_tb_text_hashmap: FnvHashMap<u64, (usize, Rc<RefCell<MemoryMap>>)>, // pub m_tb_text_hashmap: HashMap<u64, (usize, Rc<RefCell<MemoryMap>>)>, + pub m_tb_text_hash_address: [u64; TCG_HASH_SIZE], + pub m_tb_text_hash_inst_size: [usize; TCG_HASH_SIZE], + pub m_tb_text_hash_memmap: [Rc<RefCell<MemoryMap>>; TCG_HASH_SIZE], + pub m_curr_tb_text_mem: Rc<RefCell<MemoryMap>>, ...
挿入・検索は以下のようになった。まあinsert()、get()の代わりに配列の挿入と参照に変わっているだけだ。
@@ -338,18 +351,15 @@ impl EmuEnv { let tb_text_mem = if self.m_arg_config.debug { self.decode_and_run() } else { - match self.m_tb_text_hashmap.get(&self.m_pc[0]) { - Some((inst_size, mem_map)) => { - if self.m_arg_config.debug { - eprintln!("Search Hit! {:016x}", &self.m_pc[0]); - } + let hash_key = calc_hash_func(self.m_pc[0]); + if self.m_tb_text_hash_address[hash_key] == self.m_pc[0] { + let inst_size = self.m_tb_text_hash_inst_size[hash_key]; + let mem_map = &self.m_tb_text_hash_memmap[hash_key]; - self.m_pc[0] = self.m_pc[0] + *inst_size as u64; - Rc::clone(&mem_map) - } - None => { - self.decode_and_run() - } + self.m_pc[0] = self.m_pc[0] + inst_size as u64; + Rc::clone(mem_map) + } else { + self.decode_and_run() } }; @@ -790,8 +800,11 @@ impl EmuEnv { } } - // eprintln!("total_inst_byte = {:}", total_inst_byte); - self.m_tb_text_hashmap.insert(init_pc, (total_inst_byte, Rc::clone(&tb_text_mem))); + let hash_key = calc_hash_func(init_pc); + self.m_tb_text_hash_address[hash_key] = init_pc; + self.m_tb_text_hash_inst_size[hash_key] = total_inst_byte; + self.m_tb_text_hash_memmap[hash_key] = Rc::clone(&tb_text_mem);
この実装で性能測定を行った。
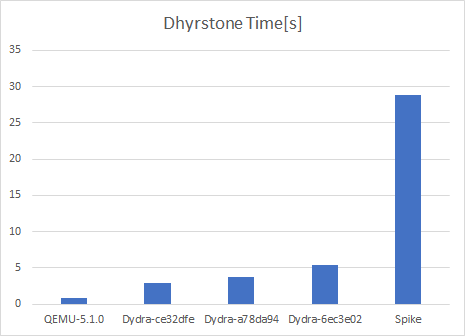
| Simulator | Dhyrstone Time[s] | |
|---|---|---|
| QEMU-5.1.0 | 0.789 | |
| Dydra-ce32dfe | HashMap未使用版 | 2.971 |
| Dydra-a78da94 | FnvHashMap使用 | 3.7488 |
| Dydra-6ec3e02 | 初期版 | 5.4504 |
| Spike | 28.909 |
FnvHashMapが3.7秒だったものが、単純な配列に変換することにより2.9秒まで削減された。ただし実装としては汚いので、もう少しきれいにしたいなあ...