Microsemiが自社のFPGA向けに、RISC-Vのソフトコアを発表した(FPGA向けは世界初ということだが)。
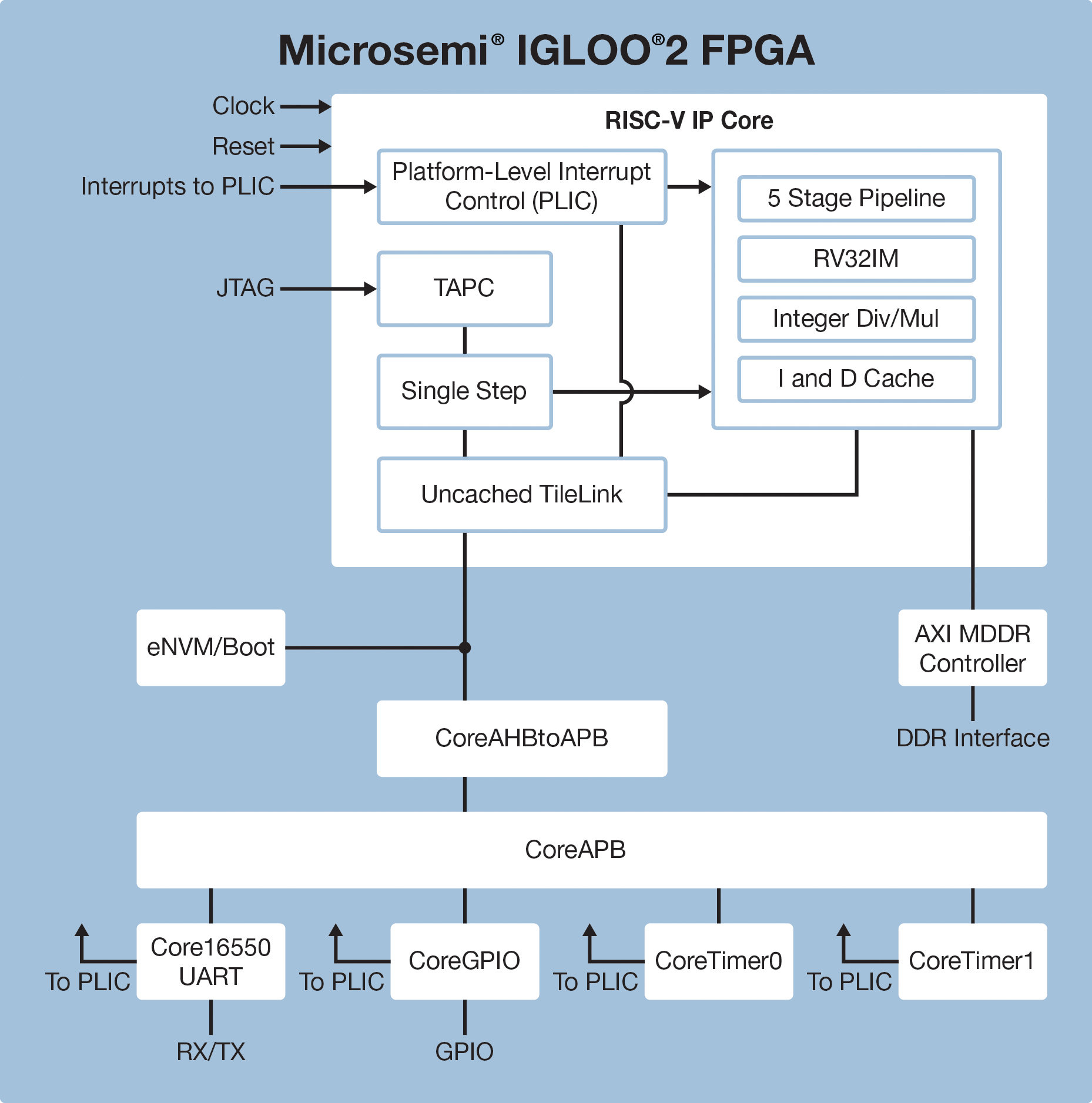
(画像はMicrosemiのウェブサイトより引用。)
Microsemiの発表によれば、自社のFPGA(SmartFusionおよびIGLOO)向けのRISC-VソフトコアIPを開発したとのことで、Eclipseベースのソフトコンソールも提供される。
詳細はこっちだ。
RV32IMということは、32ビットの最小構成タイプ、浮動小数点は付いておらず、パイプラインは5段。おそらく制御コアとして利用することを想定しているのだろう。
上記のMicrosemiのウェブサイトを見る限り、RISC-VのIPの外にはDDRのコントローラがAXI経由で接続されており、PLD部(?)とはAPB経由で接続されるようになっている。 Zynqで言うところのARMコアの立ち位置ということで良いのかな。ということは、動作周波数はどれくらいになるのだろう?
ロジックの量で言うと、
Suitable for use with all Microsemi FPGAs, the RISC-V core requires about 12,000 logic elements.
なので、MicrosemiのFPGAのロジックエレメントの規模が良く分かっていないが、数値的にはあまり大きくない感触ではある。
ってか、Microsemiは自社のFPGA向けに他にどのようなソフトコアIPを提供しているんだ?
それなりに揃っている印象ではある。Cortex-Mとか用意しているのならそれでも十分じゃないかと感じる。Cortex-Mで性能が足りない、という状況を想定しているのかな。
だとしたら、各種ソフトコアIPの性能比較の表を用意するべきだろう。これではRISC-Vを選択するメリットが分からない。
もうちょっとリリースノートを読み進めてみる。
- SoftConsole v5.0 Release Notes
SoftConsole v5.0 supports development and debugging of software targeting RISC-V CPU based SoCs on Microsemi FPGA devices.
ははあ。Linux経由でFPGA上のRISC-V CPUコアをデバッグできるという環境のことか。 OpenOCDなどという記述も出ているので、JTAG経由でデバッグするのかな?













")


