LLVMにCpu0アーキテクチャを追加するチュートリアル。ちょっと飛ばしすぎたので一度立ち戻って、LLVMのアーキテクチャについてもう一度勉強し直す。
LLVMにバックエンドを追加するチュートリアル の Cpu0 architecture and LLVM structure をもう一度読み直してまとめていく。
最初の方は一生懸命自分の言葉でまとめていたけど、途中からほぼ直訳みたいになってきた。纏めた分を掲載しておく。今回は以下の項目。
Cpu0 architecture and LLVM structure
Cpu0のアーキテクチャについては、ここでは本題ではないので省略する。
LLVMの構造
このセクションでは、LLVMが使用するコンパイラのデータ構造、アルゴリズム、およびメカニズムについて説明します。
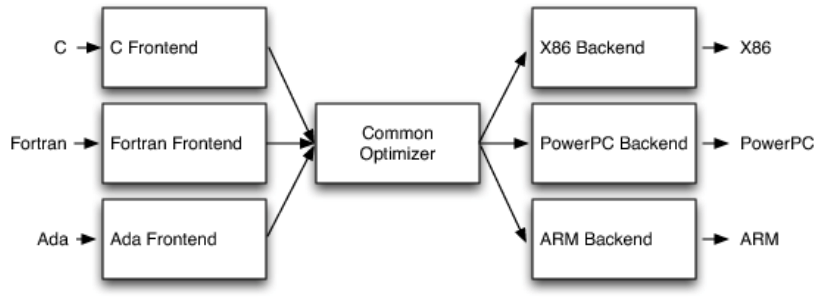
3フェーズ設計
3フェーズ設計では、下記の図に示すように、
- フロントエンド : ソースコードを解析し、抽象構文木(AST)を生成する。
- オプティマイザ : 冗長な計算の排除など、コード実行時間を短縮するための変換を行う。
- バックエンド : コードをターゲット命令セットにマッピングする。サポートされるアーキテクチャの珍しい機能を利用する、優れたコードを制しなければならない。
の3フェーズに分ける設計のことを言う。

この3フェース設計の利点は、コンパイラが複数のソース言語をサポートして、複数のターゲットをサポートしても大きく影響しないというところである。フロントエンドは共通の中間言語を生成し、バックエンドは中間言語からそれぞれのターゲット用にマシン命令を生成する。通常は、N個のソース言語とM個のアーキテクチャが存在する場合、N*M個のコンパイラが必要だが、それを削減することができる。
さらに、フロントエンドとバックエンドを分離することによって異なるスキルを持つ技術者がコンパイラ開発に参画することができ、コンパイラ開発の障壁を削減することができる。
フロントエンドで解析されたソースコードは、LLVM中間表現(IR)に変換される。以下は.llファイルの例である。
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
// 上記のLLVM IRは下記のCコードに相当するものである。整数加算をおこなう関数を、2種類実装したものである: unsigned add1(unsigned a, unsigned b) { return a+b; } // Perhaps not the most efficient way to add two numbers. unsigned add2(unsigned a, unsigned b) { if (a == 0) return b; return add2(a-1, b+1); }
この中間言語の特徴としては、型システムで型付けされているというところである。さらに、呼び出し規約はcall命令、returnはret命令により抽象化されている。さらに、レジスタは固定されておらず、無限にレジスタが存在しているという前提で表現されている。
さらに、LLVM IRは上記のテキスト形式ではなく、バイナリ形式である「ビットコード」形式によってやり取りされる。
llvm-as:.llファイルから.bcへの変換llvm-dis:.bcフィルから.llへの変換を行う。
オプティマイザは、フロントエンドとバックエンドと異なり、特定のターゲットやソースコードに依存せず、最適化のみを担当する。
LLVMのTarget Description言語: .td
バックエンドで生成される命令を記述するために、tdファイルを記述する必要がある。tdファイルの難しいところは、各アーキテクチャの固有の特徴をうまく一般的に表現しなければならないところである。
下記はx86ターゲットのビルドプロセスの例である。
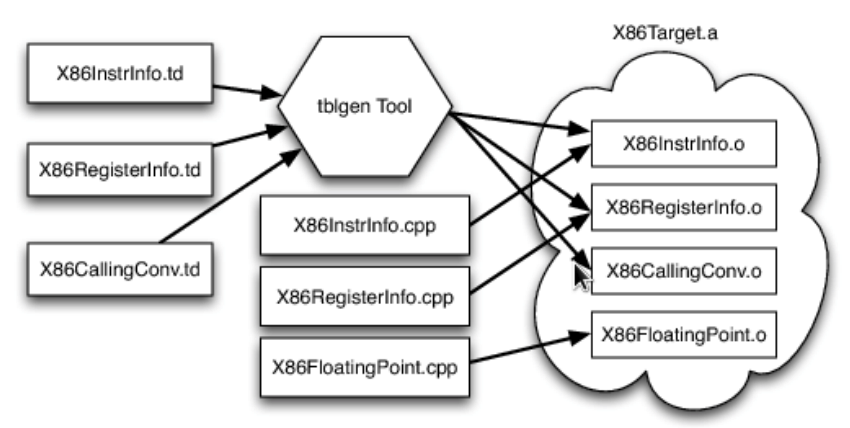
.tdファイルは、ターゲットの様々な情報を記述する。例えば、下記はx86のGR32というレジスタクラスを定義しており、このレジスタクラスにはいくつかのレジスタが含まれていることを示している。
def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { ... }
フロントエンドでは、コンパイラ開発ツールは"Parser Generator"を提供するが、バックエンドでは、以下のように"マシンコードジェネレータ"を提供する。
![digraph G { rankdir=TB; subgraph cluster_0 { node [color=black]; "parser generator such as yacc/lex"; node [shape=note]; "code gen function embedded in BNF", "regular expression + BNF", "front parser"; "code gen function embedded in BNF" -> "parser generator such as yacc/lex"; "regular expression + BNF" -> "parser generator such as yacc/lex"; "parser generator such as yacc/lex" -> "front parser"; } subgraph cluster_1 { node [color=black]; "yacc/lex"; node [shape=note]; "*.c, *.cpp", "*.y, *.l", "front parser: *.cpp"; "*.c, *.cpp" -> "yacc/lex"; "*.y, *.l" -> "yacc/lex"; "yacc/lex" -> "front parser: *.cpp"; } label = "Front TableGen Flow"; }](https://jonathan2251.github.io/lbd/_images/graphviz-c9b1e3fb8a4750cbccceb8d544f7a947dce8251b.png)
![digraph G { rankdir=TB; subgraph cluster_0 { node [color=black]; "TableGen"; node [shape=note]; "Hardware/Target Description Language Files", "Pattern Match files in c/c++\nfor IR -> Machine Instructions"; "Hardware/Target Description Language Files" -> "TableGen"; "TableGen" -> "Pattern Match files in c/c++\nfor IR -> Machine Instructions"; } subgraph cluster_1 { node [color=black]; "llvm-tblgen"; node [shape=note]; "*.td", "*.inc"; "*.td" -> "llvm-tblgen" -> "*.inc"; } label = "llvm TableGen Flow"; }](https://jonathan2251.github.io/lbd/_images/graphviz-9ac76033d1705f36f56d5b7c566fc144726b2b44.png)
C++のフロントエンドはBNF生成ツールを使わず、ハンドコードのParserを使用している。GNU G++コンパイラは実際、BNFツールを使っていない。バックエンドは、TableGenツールを使用している。C++の場合はフロントエンドを1から作るのは大変だが、多くのプログラミング言語はBNFを使用することができる。
LLVMのコード生成シーケンス
以下はtricore_llvm.pdfからの引用。
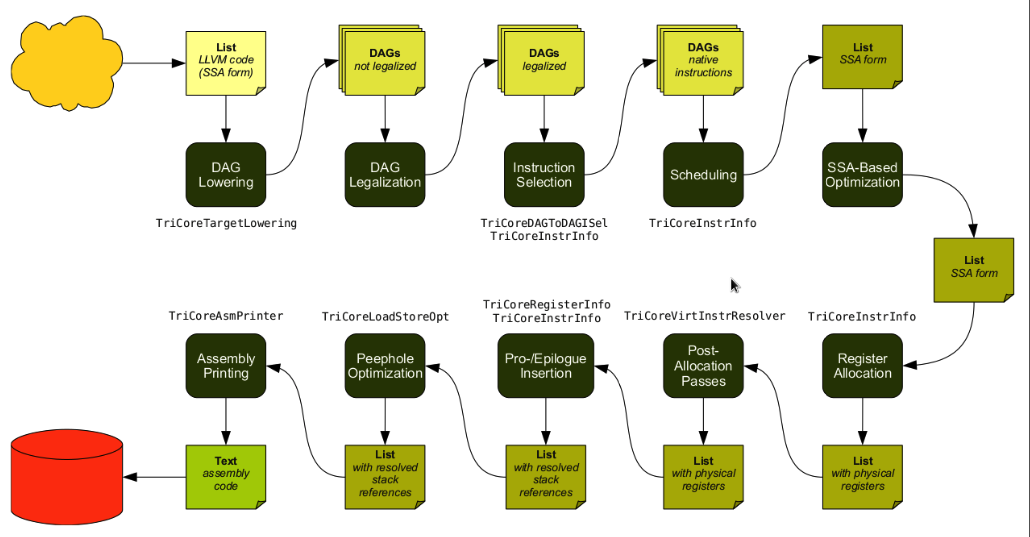
LLVMのIRの特徴は以下である。
- スタティック・シングル・アサインメント(SSA)ベースの表現を持っている。
- プリミティブ型(整数、浮動小数点、またはポインタ値)の値を保持できる仮想レジスタを持っている。
- 仮想レジスタの数は無限である。
- コメントは";"
store i32 0, i32* %a ; i32型の0を仮想レジスタ%aに保存する。%aはi32値を指すためのポインタ型である。 store i32 %b, i32* %c ; %bの内容を%cの指している場所へ格納する。%bはi32型の仮想レジスタであり、%cはi32の値を指すためのポインタである。 %a1 = load i32* %a ; %aが指す場所のデータをメモリからロードし、メモリの値を%a1に格納する。 %a3 = add i32 %a2, 1 ; %a2と1を加算し%a3に格納する。
コード生成プロセスを以下に説明する。
1. 命令選択
// このステージでは、LLVMオペコードをマシンオペコードに変換する。しかしこのステージでのオペランドはLLVM仮想オペランドのままである。 store i16 0, i16* %a // i32型の0を仮想レジスタ%aに保存する。%aはi32値を指すためのポインタ型である。 => st i16 0, i32* %a // IRのストアの代わりに、Cpu0バックエンド命令を使用する。
2. スケジュールとフォーメーション
// このステージでは、命令サイクル数やレジスタプレッシャなどの最適化のために命令を並べ替える。
st i32 %a, i16* %b, i16 5 // st %a to *(%b+5)
st %b, i32* %c, i16 0
%d = ld i32* %c
// 上記の命令を以下のように変換する。MIPS RISC CPUでは ld %cは前の命令であるst %cの結果を使用する。したがって1サイクル待つ必要があり、ldはstの直後に実行することができないことを意味する。
=> st %b, i32* %c, i16 0
st i32 %a, i16* %b, i16 5
%d = ld i32* %c, i16 0
// 命令の並べ替えが行われないと、何もしないためのnop命令が挿入され1サイクル伸びる。(実際にはMIPSはハードウェアで動的にスケジューリングを入れるため、コンパイラがnopを入れなかったとしてもstとld命令に自動的にnopが挿入される。)
st i32 %a, i16* %b, i16 5
st %b, i32* %c, i16 0
nop
%d = ld i32* %c, i16 0
// レジスタプレッシャ
// %c が命令の基本ブロックの外でも生きているとすると、%aと%bはブロックの外では生きていない。
// 以下の並べ替えを行わない版では、少なくともレジスタが3つ必要である。
%a = add i32 1, i32 0
%b = add i32 2, i32 0
st %a, i32* %c, 1
st %b, i32* %c, 2
// 並べ替えを行った版では、%aと%bを同じレジスタで使用するため、2レジスタしか使用しない。
=> %a = add i32 1, i32 0
st %a, i32* %c, 1
%b = add i32 2, i32 0
st %b, i32* %c, 2
3. SSAベースのマシンコード最適化
例えば、DAGでの共通式削除などを行う。
4. レジスタ割り付け
5. プロローグ/エピローグコードの挿入
「プロローグ/エピローグ関数の追加」のセクションで説明する。
6. 後期マシンコードの最適化
ピープホール最適化を行う。例えば、x = x * 2をx = x << 1に置き換える。
7. コード出力
最後に、完成したマシンコードが出力される。
LLVMがどのようなコード生成のシーケンスを持っているかは、llc -debug-pass = Structureで確認できる。
118-165-79-200:input Jonathan$ llc --help-hidden
OVERVIEW: llvm system compiler
USAGE: llc [options] <input bitcode>
OPTIONS:
...
-debug-pass - Print PassManager debugging information
=None - disable debug output
=Arguments - print pass arguments to pass to 'opt'
=Structure - print pass structure before run()
=Executions - print pass name before it is executed
=Details - print pass details when it is executed
118-165-79-200:input Jonathan$ llc -march=mips -debug-pass=Structure ch3.bc
...
Target Library Information
Target Transform Info
Data Layout
Target Pass Configuration
No Alias Analysis (always returns 'may' alias)
Type-Based Alias Analysis
Basic Alias Analysis (stateless AA impl)
Create Garbage Collector Module Metadata
Machine Module Information
Machine Branch Probability Analysis
ModulePass Manager
FunctionPass Manager
Preliminary module verification
Dominator Tree Construction
Module Verifier
Natural Loop Information
Loop Pass Manager
Canonicalize natural loops
Scalar Evolution Analysis
Loop Pass Manager
Canonicalize natural loops
Induction Variable Users
Loop Strength Reduction
Lower Garbage Collection Instructions
Remove unreachable blocks from the CFG
Exception handling preparation
Optimize for code generation
Insert stack protectors
Preliminary module verification
Dominator Tree Construction
Module Verifier
Machine Function Analysis
Natural Loop Information
Branch Probability Analysis
* MIPS DAG->DAG Pattern Instruction Selection
Expand ISel Pseudo-instructions
Tail Duplication
Optimize machine instruction PHIs
MachineDominator Tree Construction
Slot index numbering
Merge disjoint stack slots
Local Stack Slot Allocation
Remove dead machine instructions
MachineDominator Tree Construction
Machine Natural Loop Construction
Machine Loop Invariant Code Motion
Machine Common Subexpression Elimination
Machine code sinking
* Peephole Optimizations
Process Implicit Definitions
Remove unreachable machine basic blocks
Live Variable Analysis
Eliminate PHI nodes for register allocation
Two-Address instruction pass
Slot index numbering
Live Interval Analysis
Debug Variable Analysis
Simple Register Coalescing
Live Stack Slot Analysis
Calculate spill weights
Virtual Register Map
Live Register Matrix
Bundle Machine CFG Edges
Spill Code Placement Analysis
* Greedy Register Allocator
Virtual Register Rewriter
Stack Slot Coloring
Machine Loop Invariant Code Motion
* Prologue/Epilogue Insertion & Frame Finalization
Control Flow Optimizer
Tail Duplication
Machine Copy Propagation Pass
* Post-RA pseudo instruction expansion pass
MachineDominator Tree Construction
Machine Natural Loop Construction
Post RA top-down list latency scheduler
Analyze Machine Code For Garbage Collection
Machine Block Frequency Analysis
Branch Probability Basic Block Placement
Mips Delay Slot Filler
Mips Long Branch
MachineDominator Tree Construction
Machine Natural Loop Construction
* Mips Assembly Printer
Delete Garbage Collector Information
SSA形式
LLVM IRはSSA形式である。SSA形式の場合、各変数は1度だけ使用される。SSAの利点は、命令選択やスケジューリングなどの各種最適化処理が行いやすいということである。
例えば、次のようなコードでレジスタ数を制限する場合、処理が煩雑になる。
%a = add nsw i32 1, i32 0 store i32 %a, i32* %c, align 4 %a = add nsw i32 2, i32 0 store i32 %a, i32* %c, align 4
仮想レジスタ%aが2度使われる。以下のようにコードを生成する必要がある。
=> %a = add i32 1, i32 0 st %a, i32* %c, 1 %a = add i32 2, i32 0 st %a, i32* %c, 2
この結果、実は並列に動作できるコードも再構築できなくなる可能性がある。
%a = add nsw i32 1, i32 0
store i32 %a, i32* %c, align 4
%b = add nsw i32 2, i32 0
store i32 %b, i32* %d, align 4
// version 1
=> %a = add i32 1, i32 0
st %a, i32* %c, 0
%b = add i32 2, i32 0
st %b, i32* %d, 0
// version 2
=> %a = add i32 1, i32 0
%b = add i32 2, i32 0
st %a, i32* %c, 0
st %b, i32* %d, 0
// version 3
=> %b = add i32 2, i32 0
st %b, i32* %d, 0
%a = add i32 1, i32 0
st %a, i32* %c, 0
DSA形式
for (int i = 0; i < 1000; i++) { b[i] = f(g(a[i])); }
上記のプログラムについて、下記はソースコードレベルのSSAとIRレベルのSSAである。
for (int i = 0; i < 1000; i++) { t = g(a[i]); b[i] = f(t); }
%pi = alloca i32 store i32 0, i32* %pi %i = load i32, i32* %pi %cmp = icmp slt i32 %i, 1000 br i1 %cmp, label %true, label %end true: %a_idx = add i32 %i, i32 %a_addr %val0 = load i32, i32* %a_idx %t = call i64 %g(i32 %val0) %val1 = call i64 %f(i32 %t) %b_idx = add i32 %i, i32 %b_addr store i32 %val1, i32* %b_idx end:
下記はDSA(Dynamic Single Assignment)形式である。
for (int i = 0; i < 1000; i++) { t[i] = g(a[i]); b[i] = f(t[i]); }
%pi = alloca i32 store i32 0, i32* %pi %i = load i32, i32* %pi %cmp = icmp slt i32 %i, 1000 br i1 %cmp, label %true, label %end true: %a_idx = add i32 %i, i32 %a_addr %val0 = load i32, i32* %a_idx %t_idx = add i32 %i, i32 %t_addr %temp = call i64 %g(i32 %val0) store i32 %temp, i32* %t_idx %val1 = call i64 %f(i32 %temp) %b_idx = add i32 %i, i32 %b_addr store i32 %val1, i32* %b_idx end:
SMPのプラットフォームの場合には、上記のコードはg()とf()のループを別々に実行した方が優れている可能性がある。SSAでは下記のようにループを分割できないが、DSAでは可能である。
for (int i = 0; i < 1000; i++) { t[i] = g(a[i]); } for (int i = 0; i < 1000; i++) { b[i] = f(t[i]); }
%pi = alloca i32 store i32 0, i32* %pi %i = load i32, i32* %pi %cmp = icmp slt i32 %i, 1000 br i1 %cmp, label %true, label %end true: %a_idx = add i32 %i, i32 %a_addr %val0 = load i32, i32* %a_idx %t_idx = add i32 %i, i32 %t_addr %temp = call i32 %g(i32 %val0) store i32 %temp, i32* %t_idx end: %pi = alloca i32 store i32 0, i32* %pi %i = load i32, i32* %pi %cmp = icmp slt i32 %i, 1000 br i1 %cmp, label %true, label %end true: %t_idx = add i32 %i, i32 %t_addr %temp = load i32, i32* %t_idx %val1 = call i32 %f(i32 %temp) %b_idx = add i32 %i, i32 %b_addr store i32 %val1, i32* %b_idx end:
これにより、LLVMは各種最適化や命令の順番の制御することができる。例えば、g(x)はGPU用で実行され、f(x)はCPUで実行する、というような制御も可能である。