RISC-VのアウトオブオーダコアであるBOOM (Berkely Out-of-Order Machine) について勉強を進めている。以下のドキュメントを日本語に訳しながら読んでいくことにした。
GShare分岐予測器
GShare はシンプルですが非常に効果的な分岐予測器です。 予測は、命令アドレスと GHR をハッシュ化し (通常は単純な XOR)、 2 ビットカウンターのテーブルにインデックスを付けることで行われます。 Fig. 10 は論理アーキテクチャを、 gshire-predictor-pipeline は GShare予測器 の物理的な実装と構造を示しています。 予測は、要求アドレスが予測器に送られた F0 ステージで開始されますが、命令キャッシュから命令が戻り、 GShare のp-tableから予測状態が読み出された F3 段階では、予測が後に行われることに注意してください。

Fig. 12 The GShare Predictor Pipeline
TAGE分岐予測器
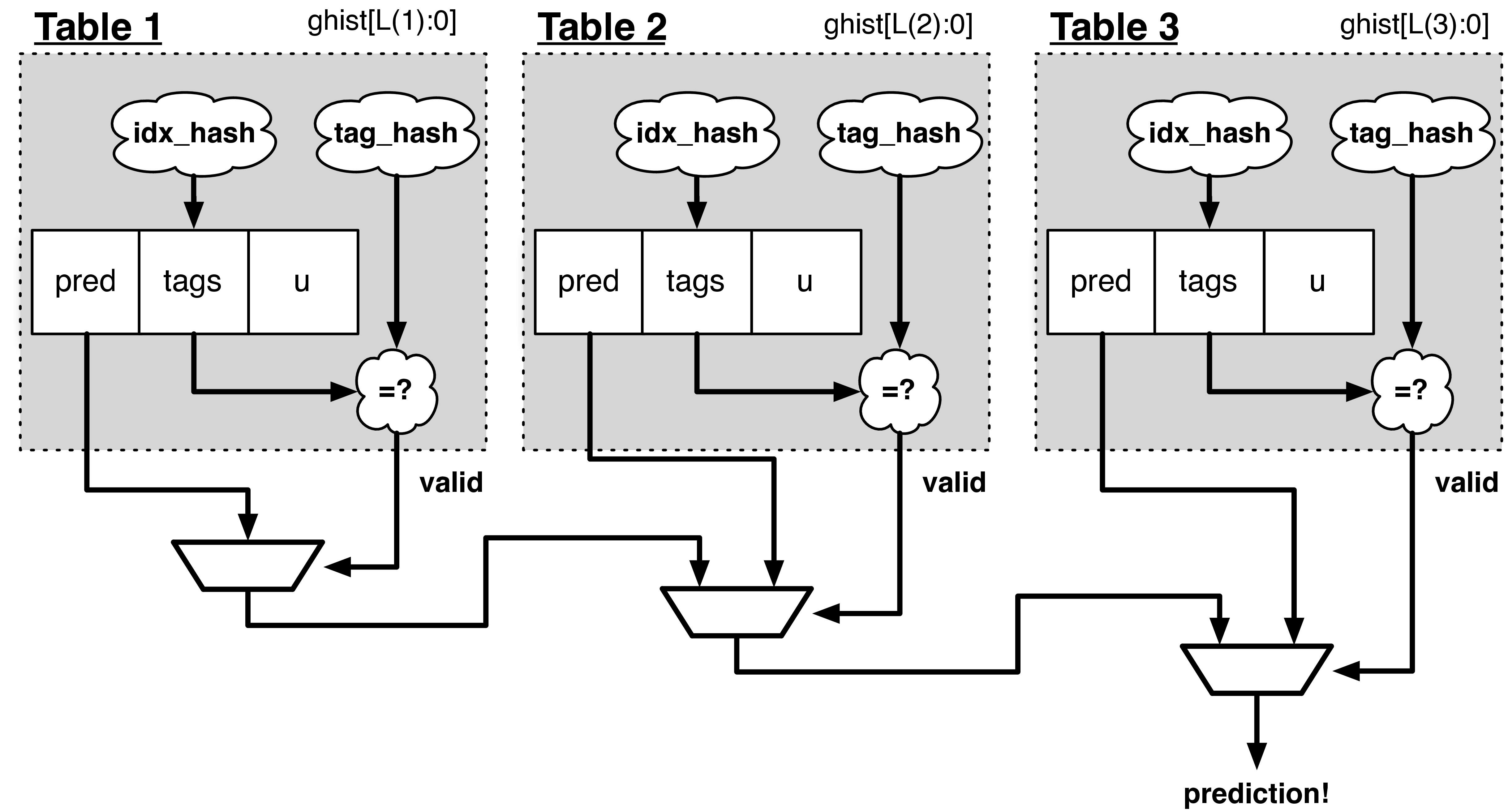
Fig. 13 TAGE分岐予測器。リクエストアドレス(PC)とグローバルヒストリーが各テーブルのインデックスハッシュとタグハッシュに入力されます。 各テーブルは独自の予測を行い(または予測を行わず)、最も長い履歴を持つテーブルが勝利します。
BOOMには、TAGE という条件付き分岐予測器も実装されています。 TAGE は高度にパラメータ化された、最先端のグローバルヒストリー予測器です。 この設計は、非常に小さな予測サイズから非常に大きな予測サイズまで拡張しながら、高い精度を維持することができます。 また、短いヒストリーを高速に学習する一方で、非常に長いヒストリー(1000以上の分岐ヒストリー)を学習することもできます。
TAGE (TAgged GEometric) は、予測テーブルのコレクションとして実装されています。 各テーブルのエントリは、 予測カウンタ 、 有用性カウンタ 、および タグ を含んでいます。 予測カウンタ は、予測を提供します(そして、予測がどの程度強く受験または非受験に偏っているかについて、いくつかのヒステリシスを維持します)。 usefulness counter は、特定のエントリが正しい予測を提供するために過去にどれだけ有用であったかを追跡します。 タグ は、特定の要求命令アドレスとグローバル履歴に対してタグの一致がある場合にのみ、テーブルが予測を行うことを可能にします。
各テーブルには、それぞれ異なる(幾何学的に増加する)履歴が関連付けられています。 各テーブルの履歴は、要求命令アドレスとのハッシュ化に使用され、インデックスハッシュとタグハッシュを生成します。 各テーブルは独自の予測を行います(タグが一致しない場合は予測を行いません)。 予測を行った履歴が最も長いテーブルが勝利します。
予測が外れた場合、 TAGE は新しいエントリを割り当てようとします。 これは”役に立たない”(ubits == 0)エントリーのみを上書きします。
TAGEグローバルヒストリとリングシフトレジスタ (CSR) 15
それぞれの TAGE テーブルには、独自のグローバルヒストリーが関連付けられています (各テーブルは最後のテーブルよりも幾何学的に多くのヒストリーを持っています)。 ヒストリーには、TAGE テーブルのインデックスに使用できるビット数よりも多くのヒストリーが含まれているため、ヒストリーを「折り畳む」必要があります。 1024エントリのテーブルでは、テーブルのインデックスに10ビットを使用します。 したがって、テーブルが20ビットのグローバルヒストリーを使用する場合、上位10ビットのヒストリーと下位10ビットのヒストリーがXORされます。
非常に長い履歴レジスタをサイクルごとに動的に折り畳もうとする代わりに、履歴をサーキュラー・シフ ト・レジスタ(CSR)に格納することができます。 履歴はすでに折りたたまれて保存されており、更新を行うために必要なのは新しい履歴ビットと最も古い履歴ビットだけです。 Listing 2 に、CSR の動作例を示します。
Listing 2 The circular shift register. When a new branch outcome is added, the register is shifted (and wrapped around). The new outcome is added and the oldest bit in the history is “evicted”.
Example:
A 12 bit value (0b_0111_1001_1111) folded onto a 5 bit CSR becomes
(0b_0_0010), which can be found by:
/-- history[12] (evict bit)
|
c[4], c[3], c[2], c[1], c[0]
| ^
| |
\_______________________/ \---history[0] (newly taken bit)
(c[4] ^ h[ 0] generates the new c[0]).
(c[1] ^ h[12] generates the new c[2]).
各テーブルは、 3つ のCSRを保持する必要があります。 1つ目のCSRはインデックスハッシュの計算に使用され、サイズは n=log(num_table_entries) です。 CSRには折り返しの履歴が含まれているため、CSRの長さに一致する周期的な履歴パターンはすべてゼロにXORされます(潜在的に非常によくあることです)。 このため、タグハッシュを計算するためのCSRは、幅nのものと幅 n-1 のものの2つがあります。
予測のたびに、(テーブルごとに)3つのCSRをすべてスナップショットし、ブランチの誤予測が発生した場合にはリセットしなければなりません。 また、パイプラインのフラッシュを処理するために、これらのCSRの別の3つの コミットコピー を維持する必要があります。
Usefulnessカウンタ (u-bits)
エントリの「有用性」は、u-bit カウンタに格納されます。 大まかに言うと、あるエントリーが正しい予測を提供した場合、u-bitカウンターはインクリメントされます。 エントリが間違った予測をした場合、u-bitカウンタはデクリメントされます。 予測違いが発生すると、TAGE は新しいエントリを割り当てようとします。 有用なエントリを上書きしないように、既存のエントリの有用性が0の場合にのみエントリを割り当てます。 しかし、潜在的なエントリがすべて有用であるためにエントリの割り当てに失敗した場合、 潜在的なエントリはすべてデクリメントされ、将来の割り当てのためのスペースを確保する可能性があります。
TAGE が有用だがほとんど使われないエントリでいっぱいになるのを防ぐために、TAGE は時間の経過とともにu-bitを「デグレード」するスキームを提供しなければなりません。 いくつかの方法があります。 1つのオプションは、u-bitカウンタを定期的にデグレードするタイマーです。 もう一つの方法は、割り当てに失敗した数を追跡することです(割り当てに失敗するとインクリメントし、割り当てに成功するとデクリメントします)。 カウンターが飽和すると、すべてのu-bitがデグレードされます。
TAGEスナップショット状態
すべての予測について、3つのCSR(すべてのテーブル)がスナップショットされ、ブランチの誤予測が発生した場合にリセットされなければなりません。 また、TAGE は、予測のためにチェックされた各テーブルのインデックスを記憶しておく必要があります(これにより、各テーブルの正しいエントリを後で更新することができます)。 最後に、TAGE は各テーブルに対して計算されたタグを覚えておかなければなりません。 タグは後で新しいエントリを割り当てる際に必要になります。16
他の分岐予測器
BOOMには、他にも有用な分岐予測器が多数用意されています。
Base Only Predictorは、BTBのBIMを使って、分岐が取られたかどうかの予測を行います。
Null分岐予測器
Null Predictorは、BPDの分岐予測器が必要ない場合に使用します。 これは常に「not taken」と予測します。
ランダム分岐予測器
ランダム予測器はLFSRを使って、「予測が行われたか」と「フェッチパケットの各ブランチがどの方向に進むべきか」の両方をランダムにします。 これは、BOOMをテストするための拷問と、分岐予測器を比較するためのより悪いケースのパフォーマンスのベースラインを提供するための両方に非常に役立ちます。