SonicBOOMのロードユースについて調査したい。キャッシュヒットした場合、ロード命令からその次の依存命令まで何サイクル掛かるのか。
以下のようなテストプログラムを作成した。ロードした命令を次にadd命令で使用する。ヒットしたときとそうでないときでレイテンシの差分を見たい。
int64_t data [16 * 4] __attribute__ ((aligned (64))) = { 0x100, 0x101, 0x102, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f, 0x110, 0x111, 0x112, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x1a, 0x1b, 0x1c, 0x1d, 0x1e, 0x1f, 0x120, 0x121, 0x122, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2a, 0x2b, 0x2c, 0x2d, 0x2e, 0x2f, 0x130, 0x131, 0x132, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3a, 0x3b, 0x3c, 0x3d, 0x3e, 0x3f }; volatile int init_wait = 0; int main (int hartid) { int64_t load; __asm__ __volatile__ ("ld %0, %1":"=r"(load): "m"(data[0])); __asm__ __volatile__ ("add %0, %1, 0x10":"=r"(load): "r"(load)); __asm__ __volatile__ ("add %0, %1, 0x20":"=r"(load): "r"(load)); data [16*4-1] = load; __asm__ __volatile__ ("fence"); __asm__ __volatile__ ("ld %0, %1":"=r"(load): "m"(data[2])); __asm__ __volatile__ ("add %0, %1, 0x20":"=r"(load): "r"(load)); __asm__ __volatile__ ("add %0, %1, 0x30":"=r"(load): "r"(load)); data [16*4-2] = load; }
結果はこのようになった。最初のロード命令から次のADD命令までが6サイクル、次のロード命令から次のADD命令までが5サイクル。2番目のロード命令はキャッシュヒットしているのでレイテンシはもう少し短くなると思ったのだが、なんで5サイクルもかかっているんだ?
832 3 0x0000000080001784 auipc a4, 0x0 x14 0x0000000080001784
838 3 0x0000000080001788 addi a4, a4, 508 x14 0x0000000080001980
// 1発目のロード命令(これはキャッシュミス)
858 3 0x000000008000178c c.ld a5, 0(a4) x15 0x0000000000000100
// Load→ADDまで6サイクル
864 3 0x000000008000178e c.addi a5, 16 x15 0x0000000000000110
865 3 0x0000000080001790 addi a5, a5, 32 x15 0x0000000000000130
865 3 0x0000000080001794 sd a5, 504(a4)
901 3 0x0000000080001798 fence
// 2発目のロード命令(これはキャッシュヒット)
914 3 0x000000008000179c c.ld a5, 16(a4) x15 0x0000000000000102
// Load→ADDまで5サイクル
919 3 0x000000008000179e addi a5, a5, 32 x15 0x0000000000000122
920 3 0x00000000800017a2 addi a5, a5, 48 x15 0x0000000000000152
920 3 0x00000000800017a6 c.li a0, 0 x10 0x0000000000000000
921 3 0x00000000800017a8 sd a5, 496(a4)
921 3 0x00000000800017ac ret
922 3 0x0000000080001648 addi s0, gp, -1984 x 8 0x0000000080001bc0
937 3 0x000000008000164c c.ld a3, 0(s0) x13 0x0000000000000000
938 3 0x000000008000164e addi s2, sp, 63 x18 0x0000000080021bcf
938 3 0x0000000080001652 andi s2, s2, -64 x18 0x0000000080021bc0
939 3 0x0000000080001656 c.mv s3, a0 x19 0x0000000000000000
943 3 0x0000000080001658 c.bnez a3, pc + 44
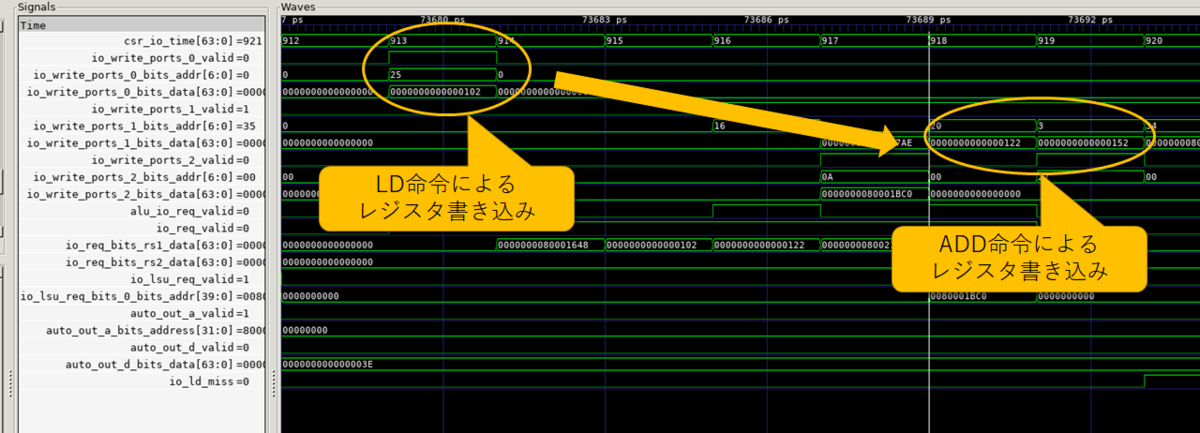
一応、ld_missという信号線があって、これがアサートされない場合(L1Dにヒットした場合)1サイクル速くなるらしいけど、それでも5サイクルは遅すぎる。どうしてそうなるんだろう?詳しく調査する。
テストパタンは以下のようになっている。
0000000080001784 <main>:
80001784: 00000717 auipc a4,0x0
80001788: 1fc70713 addi a4,a4,508 # 80001980 <data>
8000178c: 631c ld a5,0(a4)
8000178e: 07c1 addi a5,a5,16
80001790: 02078793 addi a5,a5,32
80001794: 1ef73c23 sd a5,504(a4)
80001798: 0ff0000f fence
8000179c: 6b1c ld a5,16(a4)
8000179e: 02078793 addi a5,a5,32
800017a2: 03078793 addi a5,a5,48
800017a6: 4501 li a0,0
800017a8: 1ef73823 sd a5,496(a4)
800017ac: 8082 ret






