速いコンピュータが欲しいんです...
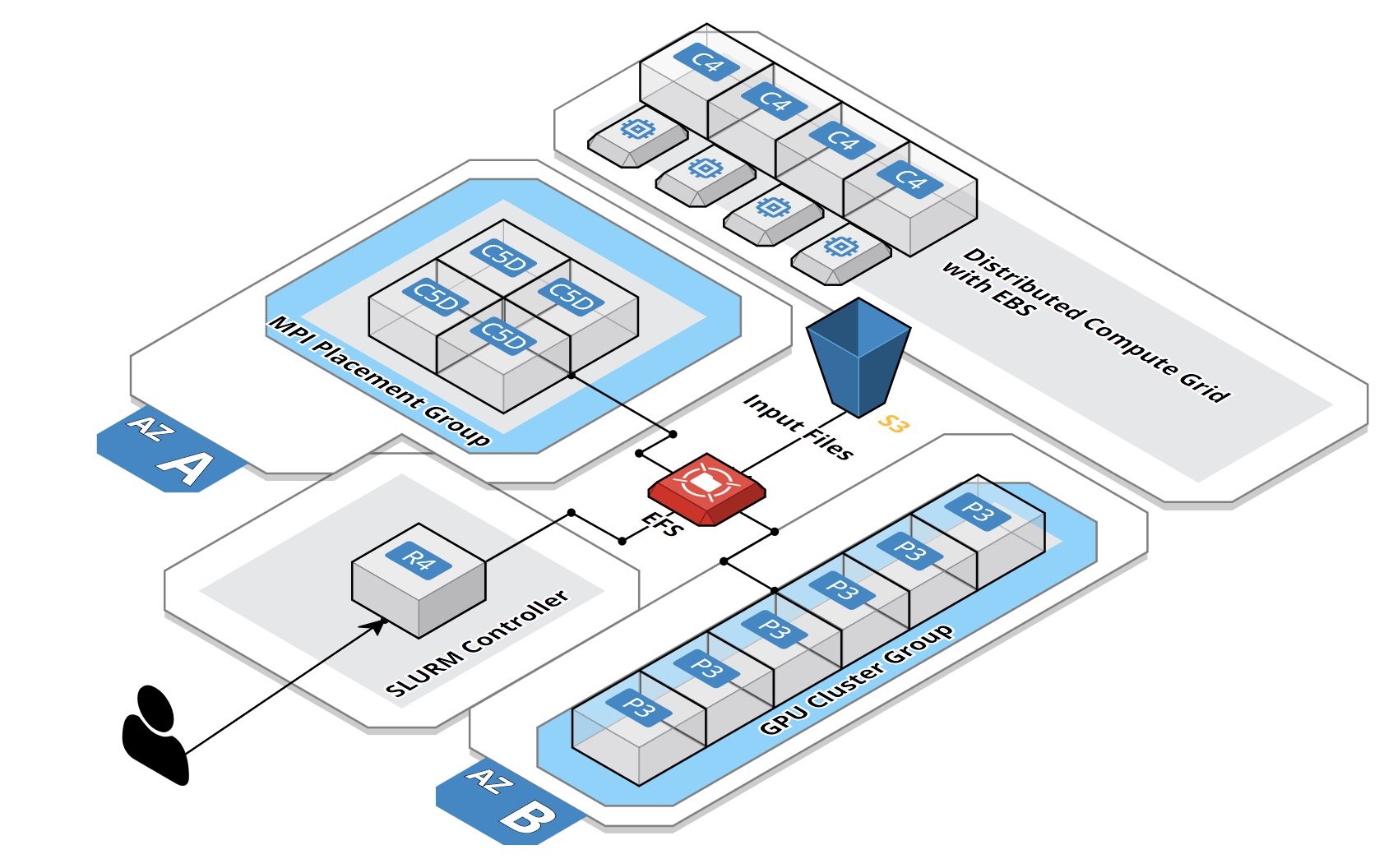
AWSを使用すると一時的にでも高速なコンピュータでジョブを動かすことができるが、高性能なマシンはお値段も高いので、作業中に常時立ち上げておくのはもったいない。 そこで、普段の作業の時はもっと弱いサーバ(もしくはローカル環境)で作業して、ビルドやシミュレーションなどの速度が要求されるような環境ではオンデマンドど高速なサーバを立ち上げたい。 この方法を色々調べていたのだが、slurmというジョブ管理ツールを使ってAWS上でクラスタを構成する方法があるらしいということを知った。 これを使うと、ジョブを高性能クラスタに投げる、ということが可能だろうか?
結構な時間を掛けて格闘していたのだが、なんとなくやり方が分かってきた。
slurmというのは、ヘッドノードからクラスタのノードに対してジョブを投入するためのツールだ。これをAWSに組み込めるかどうかを見ていく。
最初に、使用するOSとパッケージを指定する。ここでは CentOS 7 (x86_64) - with Updates HVM を使用する(というか、推奨されている)。
このCentOSのパッケージをSubscribeする。そうしないとCloud FoundationでこのOSをデプロイすることができない。

まず、ローカル(つまりAWSのサーバではなく)のPCに上記のgithubのリポジトリ、そしてslurmのソースコードをダウンロードしておく。
mkdir aws cd aws git clone https://github.com/aws-samples/aws-plugin-for-slurm.git cd aws-plugin-for-slurm wget https://download.schedmd.com/slurm/slurm-17.11.8.tar.bz2
これをAWS S3のバケットにクローンしておくらしい。S3のバケットは、全ユーザでユニークでなければならないらしい。s3://slurm-common-[ユニークな文字列]とした。
aws-plugin-for-slurm/slurm_headnode_cloudformation.ymlをいくつか編集しないといけないようだ。
s3のバケット名の設定と、デフォルトで使用するAMIを指定する。ami-045f38c93733dd48d(CentOS 7 (x86_64) - with Updates HVM) を指定した。
Parameters: S3Bucket: Description: Basic SLURM Cluster S3 Default: s3://slurm-common-[ユニークな文字列] Type: String ... BaseAMI: Description: AMI to use for ephermal compute nodes. Only CentOS/RHEL is supported Type: String Default: ami-045f38c93733dd48d ...
そして、リポジトリとslurmのパッケージをs3にコピーする。
cd aws/aws-plugin-for-slurm aws s3 sync . s3://slurm-common-[ユニークな文字列]
次に、編集したaws-plugin-for-slurm/slurm_headnode_cloudformation.ymlをCouldFoundationで読み込み、クラスタを構成する。
https://ap-northeast-1.console.aws.amazon.com/cloudformation/home?region=ap-northeast-1#/stacks
[Create Stack]をクリックして、編集した slurm_headnode_cloudformation.yml をテンプレートとして読み込ませる。これで、Slurmを使用したクラスタのテンプレートが読み込まれる。

これでNextを押し続けると、最終的な確認とともにクラスタ構成が作成される。
クラスタ構成の作成が始まる。しばらくしたら、StatusがCREATE_COMPLETEに変わる(これには10分程度必要となる)。

リソースの一覧を見てSlurmManagementEC2がCOMPLETEになるの時間がかかるようだ。たしかに、YAMLの設定ではこの設定が一番長い。
SlurmManagementEC2: DependsOn: PublicSubnet1 Type: AWS::EC2::Instance Properties: ... UserData: Fn::Base64: !Sub | #!/bin/bash -xe sudo sed -i "s|enforcing|disabled|g" /etc/selinux/config sudo setenforce 0 sudo yum update -y sudo yum --nogpgcheck install wget curl epel-release nano nfs-utils -y ... sudo sed -i "s|@BASEAMI@|${BaseAMI}|g" /home/centos/slurm-aws-startup.sh sudo sed -i "s|@SLURMROLE@|${SlurmCInstanceProfile}|g" /home/centos/slurm-aws-startup.sh sudo sed -i "s|@PRIVATE1@|${PrivateSubnet1}|g" /home/centos/slurm-aws-startup.sh sudo sed -i "s|@PRIVATE2@|${PrivateSubnet2}|g" /home/centos/slurm-aws-startup.sh sudo sed -i "s|@PRIVATE3@|${PrivateSubnet3}|g" /home/centos/slurm-aws-startup.sh aws s3 cp ${S3Bucket}/slurm-aws-shutdown.sh /home/centos/slurm-aws-shutdown.sh chmod +x /home/centos/slurm-mgmtd.sh sudo /home/centos/slurm-mgmtd.sh ${SlurmVersion} ${PrivateSubnet1.AvailabilityZone},${PrivateSubnet2.AvailabilityZone},${PrivateSubnet3.AvailabilityZone} ${SLURMComputeIPRange} cfn-signal -e $? --stack ${AWS::StackName} --resource SlurmManagementEC2WaitCondition --region ${AWS::Region}
EC2の構成を見ると、新たなslurm-headnodeのEC2インスタンスが作られている。

ログインすると、Slurmのコマンド群が使えるようになっているのが確認できる。
[centos@ip-10-0-0-212 ~]$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST all* up infinite 0 n/a gpu up infinite 0 n/a [centos@ip-10-0-0-212 ~]$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
次にsbatchのテストをしてみる。以下のようなバッチファイルを作成して流してみる。
#!/bin/bash #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=1 env
[centos@ip-10-0-0-212 ~]$ sbatch ./test.sbatch Submitted batch job 14 [centos@ip-10-0-0-212 ~]$ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST all* up infinite 1 mix# ip-10-0-1-11 gpu up infinite 1 mix# ip-10-0-1-11 [centos@ip-10-0-0-212 ~]$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 14 all test.sba centos CF 1:17 1 ip-10-0-1-11
EC2インスタンスの一覧を見ると、ジョブ用のサーバが立ち上がっていることが分かる。何とか通信はできているようだ。

ただし、ジョブを投げようとするとタイムアウトしてしまう。これは少し解析が必要だ。
$ time srun env srun: error: Node failure on ip-10-0-1-11 srun: Force Terminated job 15 srun: error: Job allocation 15 has been revoked real 10m10.613s user 0m0.014s sys 0m0.035s