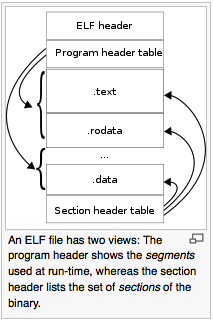
LLVMにはすでにRISC-Vのバックエンドサポートが追加されている。しかし、勉強のために独自のRISC-V実装をLLVMに追加している。
jonathan2251.github.io
第11章では、アセンブラやIntrinsicをサポートする。
具体的には、Intrinsic関数などのC言語の内部にアセンブラを埋め込む処理をサポートするのだが、これまで、さんざんアセンブリ言語のサポートを追加してきたじゃん。。。
Intrinsicでのアセンブリ記述をサポートするためには、さらにllcに改造を加える必要があるらしい。
まずは、何も改造せずにCのソースコード内にアセンブリ命令を挿入するとどうなるのか。
asm("lw $2, 8($sp)")
asm("sw $0, 4($sp)")
asm("addi $3, $zero, 0")
asm("add $s0, $s1, $t1")
asm("sub $3, $2, $3")
asm("mul $2, $1, $3")
asm("div $3, $2, $1")
asm("divu $2, $3, $10")
asm("and $2, $1, $3")
asm("or $3, $1, $2")
asm("xor $1, $2, $3")
asm("mul $11, $4, $3")
asm("mul $12, $3, $2")
asm("srai $2, $2, 2")
asm("slli $2, $2, 2")
asm("srli $2, $3, 5")
asm("jalr $t6")
asm("li $3, 0x00700000")
asm("la $3, 0x00800000($6)")
asm("la $3, 0x00900000")
まず、上記のC言語のコードをclangでIRに変換するのだが、ここでは現在開発に使用しているclang/llcではなく、リリース済みの標準のclangを使用する。
開発中のclangでは、なぜかclangに読み込ませた段階でアセンブリ言語を認識してしまい、Errorを吐いてしまった。
たぶん、何かしらオプションを指定しないと、clangがデフォルトのアセンブリ言語をx86と認識しているのかなあ。。。
LLVM IRをアセンブリに直接変換することはできるが、ハンドコードしたアセンブリ命令をオブジェクトファイルに直接変換することはできない。
これはなぜかというと、アセンブリ命令はAsmParserという機能が司っているかららしい。
アセンブリ命令を読み取ると、AsmParserがParseInstruction()という関数を呼び、これがどの命令であるのかをチェックする。そして、このアセンブリ命令を読み取ったうえで、LLVM IRを作成し、それを返す。
そのあとでMatchAndEmitInstruction()を呼び出して生成したLLVM IRをMCInstに変換する。どうせなら一気通貫で何も考えずにやってくれればよいのに。
しかしそうは言っても、LLVMはある程度アセンブリ命令にマッチするための関数を出力してくれる。この自動生成されたヘッダファイルを使用して、アセンブリ言語のサポートを少しでも簡単に実装してみる。
clang -target mips-unknown-linux-gnu -c ../lbdex/input/ch11_1.cpp -emit-llvm -o ch11_1.bc
./bin/llc -march=myriscvx32 -relocation-model=pic -filetype=obj ch11_1.bc
./bin/llvm-objdump -d ch11_1.o
ch11_1.o: file format ELF32-unknown
Disassembly of section .text:
.text:
0: 83 25 84 00 lw x11, 8(x8)
4: 23 22 00 00 sw x0, 4(x0)
8: 13 06 00 00 addi x12, x0, 0
c: 33 84 64 00 add x8, x9, x6
10: 33 86 c5 40 sub x12, x11, x12
14: b3 05 c5 02 mul x11, x10, x12
18: 33 c6 a5 02 div x12, x11, x10
1c: b3 55 66 02 divu x11, x12, x6
20: b3 75 c5 00 and x11, x10, x12
24: 33 66 b5 00 or x12, x10, x11
28: 33 c5 c5 00 xor x10, x11, x12
2c: b3 83 c6 02 mul x7, x13, x12
30: 33 0e b6 02 <unknown>
34: 93 d5 25 40 srai x11, x11, 2
38: 93 95 25 00 slli x11, x11, 2
3c: 93 55 56 00 srli x11, x12, 5
40: 67 80 00 00 jalr x0
44: 37 06 07 00 lui x12, 112
48: 13 66 06 00 ori x12, x12, 0
4c: 37 06 08 00 lui x12, 128
50: 13 66 06 00 ori x12, x12, 0
54: 33 06 f6 00 add x12, x12, x15
58: 37 06 09 00 lui x12, 144
5c: 13 66 06 00 ori x12, x12, 0
まず、ParseInstruction()について見て行く。
bool MYRISCVXAsmParser::
ParseInstruction(ParseInstructionInfo &Info, StringRef Name, SMLoc NameLoc,
OperandVector &Operands) {
size_t Start = 0, Next = Name.find('.');
StringRef Mnemonic = Name.slice(Start, Next);
if (Mnemonic == "ret")
Mnemonic = "jr";
Operands.push_back(MYRISCVXOperand::CreateToken(Mnemonic, NameLoc));
if (getLexer().isNot(AsmToken::EndOfStatement)) {
if (ParseOperand(Operands, Name)) {
SMLoc Loc = getLexer().getLoc();
Parser.eatToEndOfStatement();
return Error(Loc, "unexpected token in argument list");
}
while (getLexer().is(AsmToken::Comma) ) {
Parser.Lex();
if (ParseOperand(Operands, Name)) {
SMLoc Loc = getLexer().getLoc();
Parser.eatToEndOfStatement();
return Error(Loc, "unexpected token in argument list");
}
}
}
if (getLexer().isNot(AsmToken::EndOfStatement)) {
SMLoc Loc = getLexer().getLoc();
Parser.eatToEndOfStatement();
return Error(Loc, "unexpected token in argument list");
}
Parser.Lex();
return false;
}
オペコードの中でも、.で分離できるものを分離するらしい。しかし、RISC-Vではそのような命令形態はないので、とりあえず無視していいかな。
次に、MatchAndEmitInstruction()である。
bool MYRISCVXAsmParser::MatchAndEmitInstruction(SMLoc IDLoc, unsigned &Opcode,
OperandVector &Operands,
MCStreamer &Out,
uint64_t &ErrorInfo,
bool MatchingInlineAsm) {
...
unsigned MatchResult = MatchInstructionImpl(Operands, Inst, ErrorInfo,
MatchingInlineAsm);
...
MatchInstructionImpl()は、build-myriscvx/lib/Target/MYRISCVX/MYRISCVXGenAsmMatcher.incで定義されている。どうやら、Instに命令のデコードした結果生成されるLLVM IRを返すらしい。
switch (MatchResult) {
default: break;
case Match_Success: {
if (needsExpansion(Inst)) {
SmallVector<MCInst, 4> Instructions;
MatchInstructionImpl()でのマッチングに成功すると、Expansionの確認を行った後にEmitInstruction()に命令を出力する。needExppansion()はオペコードによっては命令を展開する必要があるため、その判断に使用している。
bool MYRISCVXAsmParser::needsExpansion(MCInst &Inst) {
switch(Inst.getOpcode()) {
case MYRISCVX::LoadImm32Reg:
case MYRISCVX::LoadAddr32Imm:
case MYRISCVX::LoadAddr32Reg:
return true;
default:
return false;
}
}
void MYRISCVXAsmParser::expandInstruction(MCInst &Inst, SMLoc IDLoc,
SmallVectorImpl<MCInst> &Instructions){
switch(Inst.getOpcode()) {
case MYRISCVX::LoadImm32Reg:
return expandLoadImm(Inst, IDLoc, Instructions);
...
void MYRISCVXAsmParser::expandLoadImm(MCInst &Inst, SMLoc IDLoc,
SmallVectorImpl<MCInst> &Instructions){
MCInst tmpInst;
const MCOperand &ImmOp = Inst.getOperand(1);
assert(ImmOp.isImm() && "expected immediate operand kind");
const MCOperand &RegOp = Inst.getOperand(0);
assert(RegOp.isReg() && "expected register operand kind");
int ImmValue = ImmOp.getImm();
tmpInst.setLoc(IDLoc);
if ( 0 <= ImmValue && ImmValue <= 65535) {
tmpInst.setOpcode(MYRISCVX::ORI);
tmpInst.addOperand(MCOperand::createReg(RegOp.getReg()));
...
} else if ( ImmValue < 0 && ImmValue >= -32768) {
tmpInst.setOpcode(MYRISCVX::ADDI); TODO
...
} else {
tmpInst.setOpcode(MYRISCVX::LUI);
tmpInst.addOperand(MCOperand::createReg(RegOp.getReg()));
tmpInst.addOperand(MCOperand::createImm((ImmValue & 0xffff0000) >> 16));
}
}
見ての通り、生成しなければならない値範囲に応じて生成方法を変えている。
- 0 < Imm < 0xffff の場合 :
ori dest, $zero, jに単純に置き換える。
- -32768 < Imm < 0 の場合 :
addi dest, $zero, jに置き換える。
- それ以外の範囲の場合 :
lui hi16(Imm); ori dest, dest, lo16(Imm)に置き換える。
に置き換えるという条件判断を、愚直に書き下ろしている訳だ。
その結果、生成されたオブジェクトコードをダンプしてみると、以下のようになる。
$ ./bin/llc -march=myriscvx32 -relocation-model=pic -filetype=obj ch11_1.bc
$ ./bin/llvm-objdump -d ch11_1.o
ch11_1.o: file format ELF32-unknown
Disassembly of section .text:
.text:
0: 83 25 84 00 lw x11, 8(x8)
4: 23 22 00 00 sw x0, 4(x0)
8: 13 06 00 00 addi x12, x0, 0
c: 33 84 64 00 add x8, x9, x6
10: 33 86 c5 40 sub x12, x11, x12
14: b3 05 c5 02 mul x11, x10, x12
18: 33 c6 a5 02 div x12, x11, x10
1c: b3 55 66 02 divu x11, x12, x6
20: b3 75 c5 00 and x11, x10, x12
24: 33 66 b5 00 or x12, x10, x11
28: 33 c5 c5 00 xor x10, x11, x12
2c: b3 83 c6 02 mul x7, x13, x12
30: 33 0e b6 02 <unknown>
34: 93 d5 25 40 srai x11, x11, 2
38: 93 95 25 00 slli x11, x11, 2
3c: 93 55 56 00 srli x11, x12, 5
40: 67 80 00 00 jalr x0
44: 37 06 07 00 lui x12, 112
48: 13 66 06 00 ori x12, x12, 0
4c: 37 06 08 00 lui x12, 128
50: 13 66 06 00 ori x12, x12, 0
54: 33 06 f6 00 add x12, x12, x15
58: 37 06 09 00 lui x12, 144
5c: 13 66 06 00 ori x12, x12, 0
Immediate値が、luiとorに変換されている様子が確認できた。